Worse than Random? An Embarrassingly Simple Probing Evaluation of Large Multimodal Models in Medical VQA

0
Sign in to get full access
Overview
• This paper examines the performance of large multimodal models on a medical visual question answering (VQA) task, using a simple probing evaluation approach.
• The authors find that these models perform only slightly better than random guessing on the task, challenging the assumption that they can effectively reason about medical images and questions.
• The paper highlights the need for more robust and challenging evaluation benchmarks to truly assess the capabilities of large multimodal models in specialized domains like healthcare.
Plain English Explanation
The researchers in this paper wanted to see how well large AI models that can handle both images and text (called "multimodal models") would do on a medical question-answering task. These models have become very advanced, but the researchers wondered if they could really understand and reason about medical information as well as a human doctor.
To test this, the researchers used a simple "probing" approach - they just asked the models simple yes/no questions about medical images and saw how often the models got the answers right. If the models were truly understanding the medical information, they should be able to answer these questions much better than just randomly guessing.
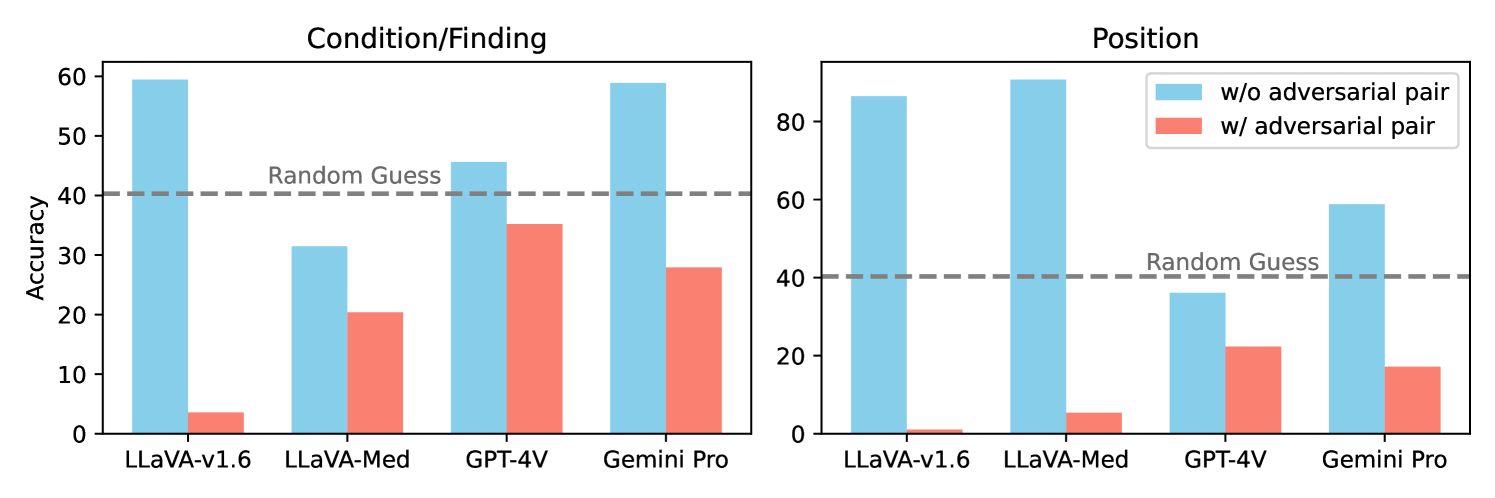
However, the researchers found that the models only performed slightly better than random guessing on this task. This was surprising, as these models are often touted as being very capable at tasks involving both images and text. The results suggest that while these models are powerful, they may still struggle to deeply comprehend and reason about specialized medical information.
The paper argues that we need better, more challenging evaluation benchmarks to really assess the true capabilities of large multimodal AI models, especially in important domains like healthcare. Simply asking them basic questions may not be enough to expose the limitations of these models.
Technical Explanation
The paper evaluates the performance of large multimodal models, such as OmniMedialVQA, PEFoMED, and MedExpQA, on a medical visual question answering (VQA) task. Rather than using a complex evaluation approach, the authors employ a simple "probing" technique.
The probing evaluation involves asking the models yes/no questions about medical images, such as "Does this image show a fractured bone?" The authors find that the models only perform slightly better than random guessing on these simple probing questions, suggesting they may struggle to deeply comprehend and reason about the medical content.
The paper also discusses the need for more robust and challenging evaluation benchmarks, such as Towards Clinically Accessible Radiology Foundation Model and MedThink, to truly assess the capabilities of large multimodal models in specialized domains like healthcare.
Critical Analysis
The paper raises valid concerns about the current state of evaluation for large multimodal models, particularly in specialized domains like healthcare. The simple probing approach used in the study highlights the potential limitations of these models, challenging the assumption that they can effectively reason about medical images and questions.
However, the paper does not delve into the potential reasons why the models may have struggled on the probing task. It would be helpful to understand if the issues are due to limitations in the model architectures, the training data, or other factors. Additionally, the paper could have explored the performance of the models on more complex medical VQA tasks to provide a more comprehensive assessment.
Furthermore, while the need for more robust and challenging evaluation benchmarks is well-argued, the paper could have provided more details on the specific characteristics and requirements of such benchmarks to be truly effective in assessing the capabilities of large multimodal models in healthcare.
Conclusion
This paper serves as an important wake-up call for the AI research community, highlighting the need to look beyond the impressive performance of large multimodal models on general-purpose tasks and carefully evaluate their capabilities in specialized domains like healthcare. The simple probing evaluation used in the study suggests that these models may not be as adept at reasoning about medical information as commonly assumed.
The paper's call for the development of more robust and challenging evaluation benchmarks is a critical step in ensuring that the deployment of large multimodal models in healthcare and other sensitive domains is done responsibly and with a clear understanding of their limitations. By encouraging a more rigorous and critical approach to model evaluation, this research can contribute to the responsible development and deployment of AI systems in the medical field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Worse than Random? An Embarrassingly Simple Probing Evaluation of Large Multimodal Models in Medical VQA
Qianqi Yan, Xuehai He, Xiang Yue, Xin Eric Wang
Large Multimodal Models (LMMs) have shown remarkable progress in medical Visual Question Answering (Med-VQA), achieving high accuracy on existing benchmarks. However, their reliability under robust evaluation is questionable. This study reveals that when subjected to simple probing evaluation, state-of-the-art models perform worse than random guessing on medical diagnosis questions. To address this critical evaluation problem, we introduce the Probing Evaluation for Medical Diagnosis (ProbMed) dataset to rigorously assess LMM performance in medical imaging through probing evaluation and procedural diagnosis. Particularly, probing evaluation features pairing original questions with negation questions with hallucinated attributes, while procedural diagnosis requires reasoning across various diagnostic dimensions for each image, including modality recognition, organ identification, clinical findings, abnormalities, and positional grounding. Our evaluation reveals that top-performing models like GPT-4o, GPT-4V, and Gemini Pro perform worse than random guessing on specialized diagnostic questions, indicating significant limitations in handling fine-grained medical inquiries. Besides, models like LLaVA-Med struggle even with more general questions, and results from CheXagent demonstrate the transferability of expertise across different modalities of the same organ, showing that specialized domain knowledge is still crucial for improving performance. This study underscores the urgent need for more robust evaluation to ensure the reliability of LMMs in critical fields like medical diagnosis, and current LMMs are still far from applicable to those fields.
Read more9/12/2024

0
MediConfusion: Can you trust your AI radiologist? Probing the reliability of multimodal medical foundation models
Mohammad Shahab Sepehri, Zalan Fabian, Maryam Soltanolkotabi, Mahdi Soltanolkotabi
Multimodal Large Language Models (MLLMs) have tremendous potential to improve the accuracy, availability, and cost-effectiveness of healthcare by providing automated solutions or serving as aids to medical professionals. Despite promising first steps in developing medical MLLMs in the past few years, their capabilities and limitations are not well-understood. Recently, many benchmark datasets have been proposed that test the general medical knowledge of such models across a variety of medical areas. However, the systematic failure modes and vulnerabilities of such models are severely underexplored with most medical benchmarks failing to expose the shortcomings of existing models in this safety-critical domain. In this paper, we introduce MediConfusion, a challenging medical Visual Question Answering (VQA) benchmark dataset, that probes the failure modes of medical MLLMs from a vision perspective. We reveal that state-of-the-art models are easily confused by image pairs that are otherwise visually dissimilar and clearly distinct for medical experts. Strikingly, all available models (open-source or proprietary) achieve performance below random guessing on MediConfusion, raising serious concerns about the reliability of existing medical MLLMs for healthcare deployment. We also extract common patterns of model failure that may help the design of a new generation of more trustworthy and reliable MLLMs in healthcare.
Read more9/25/2024

0
MMEvalPro: Calibrating Multimodal Benchmarks Towards Trustworthy and Efficient Evaluation
Jinsheng Huang, Liang Chen, Taian Guo, Fu Zeng, Yusheng Zhao, Bohan Wu, Ye Yuan, Haozhe Zhao, Zhihui Guo, Yichi Zhang, Jingyang Yuan, Wei Ju, Luchen Liu, Tianyu Liu, Baobao Chang, Ming Zhang
Large Multimodal Models (LMMs) exhibit impressive cross-modal understanding and reasoning abilities, often assessed through multiple-choice questions (MCQs) that include an image, a question, and several options. However, many benchmarks used for such evaluations suffer from systematic biases. Remarkably, Large Language Models (LLMs) without any visual perception capabilities achieve non-trivial performance, undermining the credibility of these evaluations. To address this issue while maintaining the efficiency of MCQ evaluations, we propose MMEvalPro, a benchmark designed to avoid Type-I errors through a trilogy evaluation pipeline and more rigorous metrics. For each original question from existing benchmarks, human annotators augment it by creating one perception question and one knowledge anchor question through a meticulous annotation process. MMEvalPro comprises $2,138$ question triplets, totaling $6,414$ distinct questions. Two-thirds of these questions are manually labeled by human experts, while the rest are sourced from existing benchmarks (MMMU, ScienceQA, and MathVista). Compared with the existing benchmarks, our experiments with the latest LLMs and LMMs demonstrate that MMEvalPro is more challenging (the best LMM lags behind human performance by $31.73%$, compared to an average gap of $8.03%$ in previous benchmarks) and more trustworthy (the best LLM trails the best LMM by $23.09%$, whereas the gap for previous benchmarks is just $14.64%$). Our in-depth analysis explains the reason for the large performance gap and justifies the trustworthiness of evaluation, underscoring its significant potential for advancing future research.
Read more7/2/2024
👁️
0
OmniMedVQA: A New Large-Scale Comprehensive Evaluation Benchmark for Medical LVLM
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, Ping Luo
Large Vision-Language Models (LVLMs) have demonstrated remarkable capabilities in various multimodal tasks. However, their potential in the medical domain remains largely unexplored. A significant challenge arises from the scarcity of diverse medical images spanning various modalities and anatomical regions, which is essential in real-world medical applications. To solve this problem, in this paper, we introduce OmniMedVQA, a novel comprehensive medical Visual Question Answering (VQA) benchmark. This benchmark is collected from 73 different medical datasets, including 12 different modalities and covering more than 20 distinct anatomical regions. Importantly, all images in this benchmark are sourced from authentic medical scenarios, ensuring alignment with the requirements of the medical field and suitability for evaluating LVLMs. Through our extensive experiments, we have found that existing LVLMs struggle to address these medical VQA problems effectively. Moreover, what surprises us is that medical-specialized LVLMs even exhibit inferior performance to those general-domain models, calling for a more versatile and robust LVLM in the biomedical field. The evaluation results not only reveal the current limitations of LVLM in understanding real medical images but also highlight our dataset's significance. Our code with dataset are available at https://github.com/OpenGVLab/Multi-Modality-Arena.
Read more4/23/2024