Multilingual Transfer and Domain Adaptation for Low-Resource Languages of Spain

0
Sign in to get full access
Overview
- This paper explores techniques for improving the performance of natural language processing (NLP) models on low-resource languages, using Spanish regional languages as a case study.
- The researchers investigate multilingual transfer learning and domain adaptation approaches to boost the performance of NLP models for these under-represented languages.
- The key idea is to leverage high-resource languages and domains to enhance the performance of models on low-resource counterparts, mitigating the challenge of limited training data.
Plain English Explanation
The paper focuses on improving the performance of language AI models for regional languages in Spain that have limited available data, such as Galician, Basque, and Catalan. These "low-resource" languages often struggle to achieve high accuracy with standard AI models due to the scarcity of training data.
The researchers explore two main techniques to address this challenge:
-
Multilingual Transfer Learning: This involves using AI models trained on high-resource languages like Spanish or English, and then "transferring" that knowledge to help train models for the low-resource languages. The idea is that the general language understanding gained from the high-resource languages can benefit the low-resource ones, even if the languages are quite different.
-
Domain Adaptation: This involves taking an AI model trained on one type of text (e.g. news articles) and adapting it to perform well on a different type of text (e.g. social media posts). By adapting the model to the specific domain, it can achieve better performance than a generic model.
The researchers combine these two techniques, using multilingual transfer learning to build an initial model, and then further adapting that model to the target low-resource language and domain. This "multilingual transfer and domain adaptation" approach aims to maximize the performance of the language AI models for the underserved regional languages of Spain.
Technical Explanation
The paper begins by highlighting the challenge of building effective NLP models for low-resource languages, which often lack the large training datasets available for high-resource languages like English or Mandarin Chinese. To address this, the researchers explore two complementary techniques:
-
Multilingual Transfer Learning: The researchers leverage pre-trained multilingual language models, such as mBERT, to initialize their models for the target low-resource languages (Galician, Basque, Catalan). This allows the model to benefit from the general language understanding captured in the high-resource source languages, which can then be fine-tuned on the limited data available for the low-resource languages.
-
Domain Adaptation: To further boost performance, the researchers adapt the multilingual models to the specific text domains relevant for their use case, such as social media, news articles, or government documents. This domain adaptation step helps the models better capture the linguistic nuances and styles of the target text, beyond just the language itself.
The researchers evaluate their multilingual transfer and domain adaptation approach on several downstream NLP tasks, including named entity recognition, text classification, and question answering. They demonstrate significant performance gains compared to baseline models trained solely on the low-resource language data.
Critical Analysis
The paper provides a well-designed and thorough investigation of techniques to improve NLP for low-resource languages. The authors acknowledge several limitations and areas for further research, such as:
- The need to explore more diverse target domains beyond the ones considered in this study, to ensure the approach generalizes well.
- Investigating alternative multilingual model architectures and pre-training strategies beyond mBERT, which may further boost performance.
- Extending the analysis to an even wider range of low-resource languages, beyond the Spanish regional languages covered in this work.
Additionally, while the results are promising, the paper does not provide a detailed error analysis or qualitative assessment of the model outputs. Such insights could help identify remaining challenges and guide future improvements to the techniques.
Overall, the paper makes a valuable contribution to the field of low-resource NLP, providing a solid foundation for further research and development in this important area.
Conclusion
This paper presents an effective approach for improving the performance of NLP models on low-resource languages, using the example of Spanish regional languages. By combining multilingual transfer learning and domain adaptation, the researchers demonstrate significant gains in tasks like named entity recognition, text classification, and question answering.
The techniques outlined in this work have the potential to benefit speakers of underserved languages worldwide, helping to bridge the gap in language technology access and enabling more inclusive NLP solutions. As the authors suggest, further research exploring alternative model architectures and a wider range of low-resource languages and domains could lead to even more impactful advances in this field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multilingual Transfer and Domain Adaptation for Low-Resource Languages of Spain
Yuanchang Luo, Zhanglin Wu, Daimeng Wei, Hengchao Shang, Zongyao Li, Jiaxin Guo, Zhiqiang Rao, Shaojun Li, Jinlong Yang, Yuhao Xie, Jiawei Zheng Bin Wei, Hao Yang
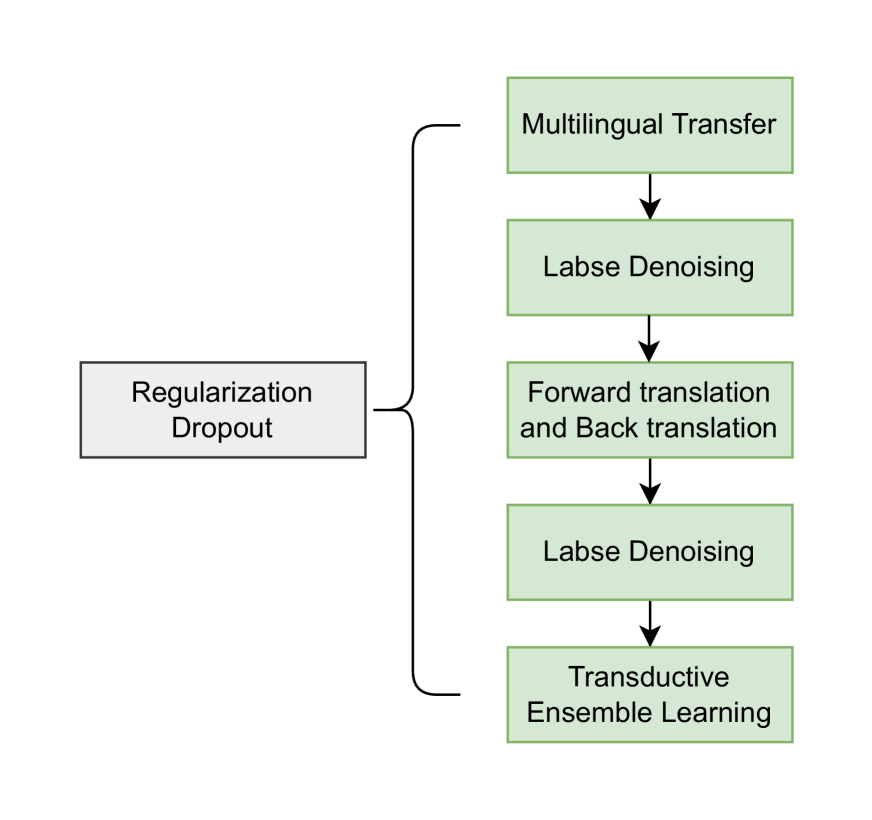
This article introduces the submission status of the Translation into Low-Resource Languages of Spain task at (WMT 2024) by Huawei Translation Service Center (HW-TSC). We participated in three translation tasks: spanish to aragonese (es-arg), spanish to aranese (es-arn), and spanish to asturian (es-ast). For these three translation tasks, we use training strategies such as multilingual transfer, regularized dropout, forward translation and back translation, labse denoising, transduction ensemble learning and other strategies to neural machine translation (NMT) model based on training deep transformer-big architecture. By using these enhancement strategies, our submission achieved a competitive result in the final evaluation.
Read more9/25/2024

0
Machine Translation Advancements of Low-Resource Indian Languages by Transfer Learning
Bin Wei, Jiawei Zhen, Zongyao Li, Zhanglin Wu, Daimeng Wei, Jiaxin Guo, Zhiqiang Rao, Shaojun Li, Yuanchang Luo, Hengchao Shang, Jinlong Yang, Yuhao Xie, Hao Yang
This paper introduces the submission by Huawei Translation Center (HW-TSC) to the WMT24 Indian Languages Machine Translation (MT) Shared Task. To develop a reliable machine translation system for low-resource Indian languages, we employed two distinct knowledge transfer strategies, taking into account the characteristics of the language scripts and the support available from existing open-source models for Indian languages. For Assamese(as) and Manipuri(mn), we fine-tuned the existing IndicTrans2 open-source model to enable bidirectional translation between English and these languages. For Khasi (kh) and Mizo (mz), We trained a multilingual model as a baseline using bilingual data from these four language pairs, along with an additional about 8kw English-Bengali bilingual data, all of which share certain linguistic features. This was followed by fine-tuning to achieve bidirectional translation between English and Khasi, as well as English and Mizo. Our transfer learning experiments produced impressive results: 23.5 BLEU for en-as, 31.8 BLEU for en-mn, 36.2 BLEU for as-en, and 47.9 BLEU for mn-en on their respective test sets. Similarly, the multilingual model transfer learning experiments yielded impressive outcomes, achieving 19.7 BLEU for en-kh, 32.8 BLEU for en-mz, 16.1 BLEU for kh-en, and 33.9 BLEU for mz-en on their respective test sets. These results not only highlight the effectiveness of transfer learning techniques for low-resource languages but also contribute to advancing machine translation capabilities for low-resource Indian languages.
Read more9/25/2024
0
HW-TSC's Submission to the CCMT 2024 Machine Translation Tasks
Zhanglin Wu, Yuanchang Luo, Daimeng Wei, Jiawei Zheng, Bin Wei, Zongyao Li, Hengchao Shang, Jiaxin Guo, Shaojun Li, Weidong Zhang, Ning Xie, Hao Yang
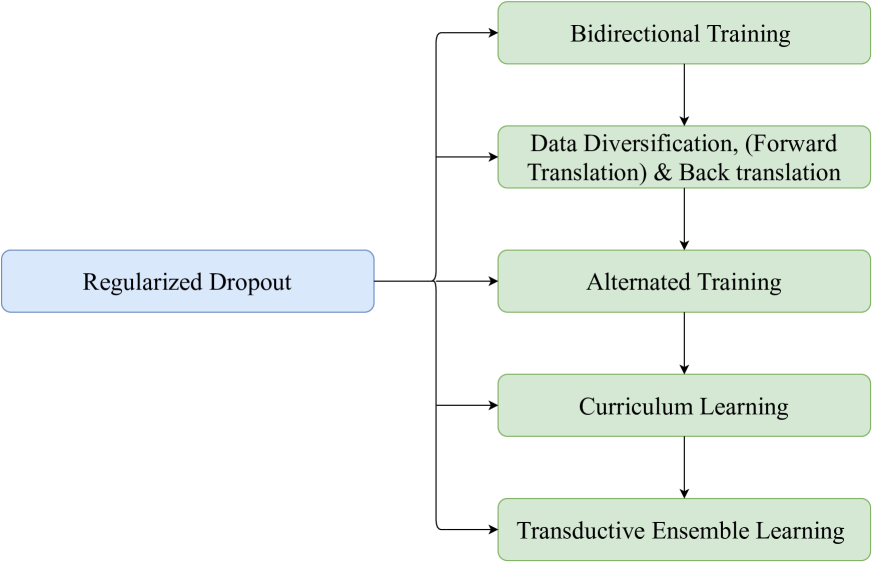
This paper presents the submission of Huawei Translation Services Center (HW-TSC) to machine translation tasks of the 20th China Conference on Machine Translation (CCMT 2024). We participate in the bilingual machine translation task and multi-domain machine translation task. For these two translation tasks, we use training strategies such as regularized dropout, bidirectional training, data diversification, forward translation, back translation, alternated training, curriculum learning, and transductive ensemble learning to train neural machine translation (NMT) models based on the deep Transformer-big architecture. Furthermore, to explore whether large language model (LLM) can help improve the translation quality of NMT systems, we use supervised fine-tuning to train llama2-13b as an Automatic post-editing (APE) model to improve the translation results of the NMT model on the multi-domain machine translation task. By using these plyometric strategies, our submission achieves a competitive result in the final evaluation.
Read more9/30/2024

0
A multilingual training strategy for low resource Text to Speech
Asma Amalas, Mounir Ghogho, Mohamed Chetouani, Rachid Oulad Haj Thami
Recent speech technologies have led to produce high quality synthesised speech due to recent advances in neural Text to Speech (TTS). However, such TTS models depend on extensive amounts of data that can be costly to produce and is hardly scalable to all existing languages, especially that seldom attention is given to low resource languages. With techniques such as knowledge transfer, the burden of creating datasets can be alleviated. In this paper, we therefore investigate two aspects; firstly, whether data from social media can be used for a small TTS dataset construction, and secondly whether cross lingual transfer learning (TL) for a low resource language can work with this type of data. In this aspect, we specifically assess to what extent multilingual modeling can be leveraged as an alternative to training on monolingual corporas. To do so, we explore how data from foreign languages may be selected and pooled to train a TTS model for a target low resource language. Our findings show that multilingual pre-training is better than monolingual pre-training at increasing the intelligibility and naturalness of the generated speech.
Read more9/4/2024