A multilingual training strategy for low resource Text to Speech

0

Sign in to get full access
Overview
- This paper presents a multilingual training strategy for text-to-speech (TTS) systems in low-resource languages.
- The key idea is to leverage data from high-resource languages to improve TTS performance in low-resource languages.
- The researchers evaluate their approach on several language pairs and show significant improvements over monolingual baselines.
Plain English Explanation
The paper is about a new way to train text-to-speech (TTS) systems for languages that don't have a lot of available data. TTS systems are used to convert written text into spoken audio, and they typically require large datasets of recorded speech to work well.
The challenge is that many languages around the world don't have these large speech datasets available. To address this, the researchers developed a multilingual training strategy. The idea is to leverage data from high-resource languages (like English or Mandarin Chinese) to help train TTS models for low-resource languages.
By combining data from multiple languages during training, the researchers found they could significantly improve TTS performance in the low-resource languages, compared to training models using only the limited local data. This is an important advancement, as it allows TTS technology to be more widely deployed, even in parts of the world with less available speech data.
Technical Explanation
The paper proposes a multilingual training strategy for text-to-speech (TTS) systems in low-resource settings. The core idea is to leverage data from high-resource languages to improve TTS performance in low-resource languages.
The researchers experiment with several multilingual TTS model architectures, including internal link: "multilingual Tacotron" and internal link: "cross-lingual transfer learning". They evaluate these approaches on multiple language pairs, comparing to internal link: "monolingual baselines".
The results show that the multilingual training strategies consistently outperform the monolingual baselines, achieving significant improvements in objective speech quality metrics like mean opinion score (MOS). The researchers attribute this success to the model's ability to learn universal speech representations that can be effectively transferred to the low-resource language.
Critical Analysis
The paper presents a compelling approach to address the challenge of building high-quality TTS systems for low-resource languages. The multilingual training strategy is a clever and well-executed idea that leverages data from abundant languages to benefit scarce ones.
However, the paper does not fully explore the limitations of this approach. For example, it is unclear how the performance would scale as the number of languages or the degree of language dissimilarity increases. Internal link: "Further research" is needed to understand the boundaries of this technique.
Additionally, the paper does not address potential ethical concerns, such as the risk of perpetuating biases in the training data or the challenge of ensuring appropriate cultural representation in the synthesized speech. These are important considerations as TTS systems become more widely deployed.
Overall, the paper makes a valuable contribution to the field of low-resource TTS, but there remain opportunities for further refinement and investigation of this promising multilingual approach.
Conclusion
This paper presents an effective multilingual training strategy for building text-to-speech (TTS) systems in low-resource language settings. By leveraging data from high-resource languages, the researchers demonstrate significant improvements in TTS performance over monolingual baselines.
This work represents an important step towards making TTS technology more accessible to a wider range of the world's languages, which could have substantial societal impact. With further research to address the technique's limitations and ethical considerations, this multilingual approach has the potential to greatly expand the reach and inclusivity of speech synthesis capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A multilingual training strategy for low resource Text to Speech
Asma Amalas, Mounir Ghogho, Mohamed Chetouani, Rachid Oulad Haj Thami
Recent speech technologies have led to produce high quality synthesised speech due to recent advances in neural Text to Speech (TTS). However, such TTS models depend on extensive amounts of data that can be costly to produce and is hardly scalable to all existing languages, especially that seldom attention is given to low resource languages. With techniques such as knowledge transfer, the burden of creating datasets can be alleviated. In this paper, we therefore investigate two aspects; firstly, whether data from social media can be used for a small TTS dataset construction, and secondly whether cross lingual transfer learning (TL) for a low resource language can work with this type of data. In this aspect, we specifically assess to what extent multilingual modeling can be leveraged as an alternative to training on monolingual corporas. To do so, we explore how data from foreign languages may be selected and pooled to train a TTS model for a target low resource language. Our findings show that multilingual pre-training is better than monolingual pre-training at increasing the intelligibility and naturalness of the generated speech.
Read more9/4/2024
0
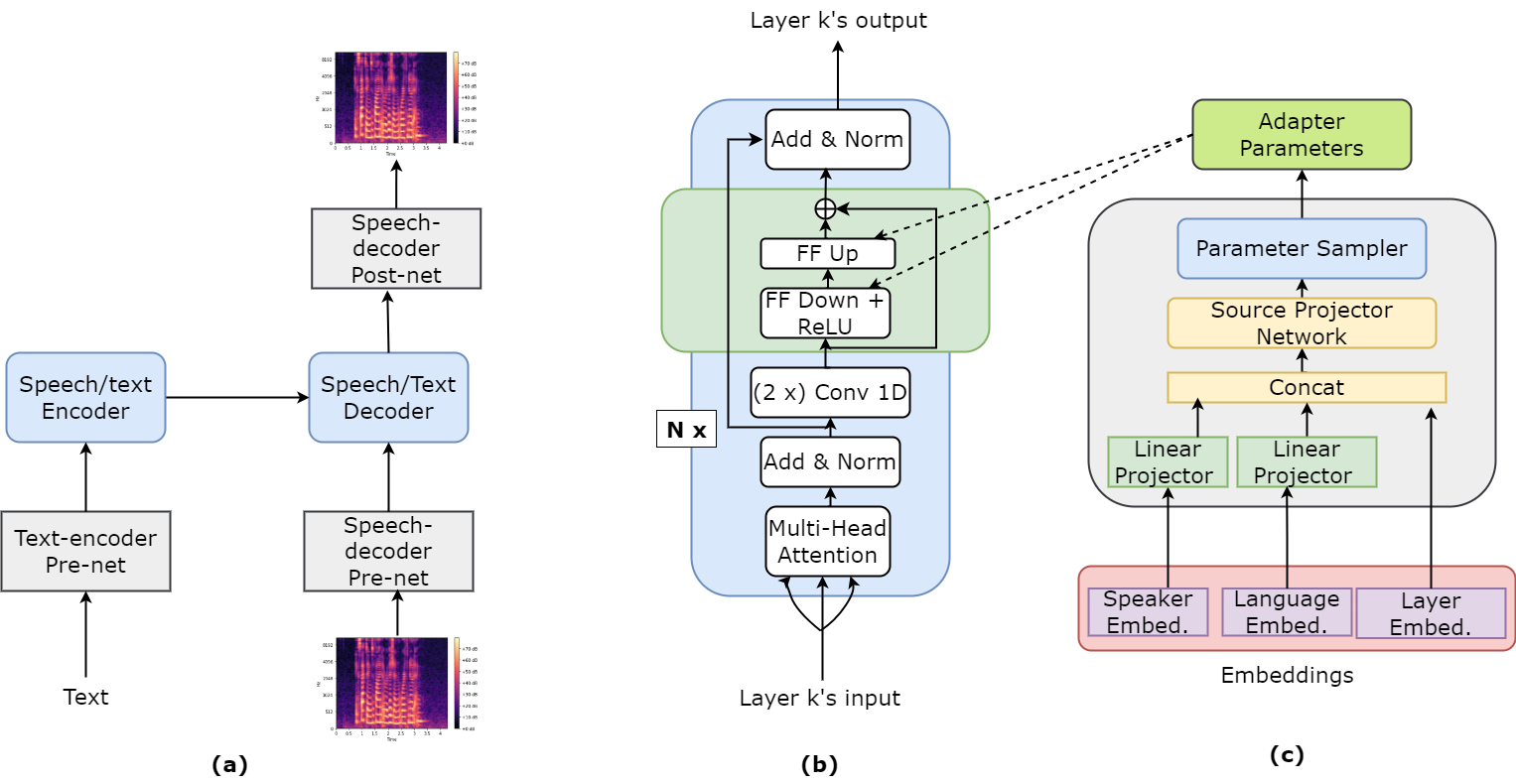
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
Read more6/26/2024
0
An Initial Investigation of Language Adaptation for TTS Systems under Low-resource Scenarios
Cheng Gong, Erica Cooper, Xin Wang, Chunyu Qiang, Mengzhe Geng, Dan Wells, Longbiao Wang, Jianwu Dang, Marc Tessier, Aidan Pine, Korin Richmond, Junichi Yamagishi
Self-supervised learning (SSL) representations from massively multilingual models offer a promising solution for low-resource language speech tasks. Despite advancements, language adaptation in TTS systems remains an open problem. This paper explores the language adaptation capability of ZMM-TTS, a recent SSL-based multilingual TTS system proposed in our previous work. We conducted experiments on 12 languages using limited data with various fine-tuning configurations. We demonstrate that the similarity in phonetics between the pre-training and target languages, as well as the language category, affects the target language's adaptation performance. Additionally, we find that the fine-tuning dataset size and number of speakers influence adaptability. Surprisingly, we also observed that using paired data for fine-tuning is not always optimal compared to audio-only data. Beyond speech intelligibility, our analysis covers speaker similarity, language identification, and predicted MOS.
Read more6/14/2024
🛸
0
Enabling ASR for Low-Resource Languages: A Comprehensive Dataset Creation Approach
Ara Yeroyan (Data Science Department, American University of Armenia), Nikolay Karpov (Nvidia, NeMo Conversational AI team)
In recent years, automatic speech recognition (ASR) systems have significantly improved, especially in languages with a vast amount of transcribed speech data. However, ASR systems tend to perform poorly for low-resource languages with fewer resources, such as minority and regional languages. This study introduces a novel pipeline designed to generate ASR training datasets from audiobooks, which typically feature a single transcript associated with hours-long audios. The common structure of these audiobooks poses a unique challenge due to the extensive length of audio segments, whereas optimal ASR training requires segments ranging from 4 to 15 seconds. To address this, we propose a method for effectively aligning audio with its corresponding text and segmenting it into lengths suitable for ASR training. Our approach simplifies data preparation for ASR systems in low-resource languages and demonstrates its application through a case study involving the Armenian language. Our method, which is portable to many low-resource languages, not only mitigates the issue of data scarcity but also enhances the performance of ASR models for underrepresented languages.
Read more6/4/2024