MultiMatch: Multi-task Learning for Semi-supervised Domain Generalization

0
🖼️
Sign in to get full access
Overview
- The paper proposes a semi-supervised domain generalization (SSDG) method called MultiMatch, which extends the FixMatch algorithm to the multi-task learning framework.
- SSDG aims to learn a model on source domains with limited label information that can generalize well to unseen target domains.
- The key ideas are to: 1) mitigate the impact of domain gap, and 2) exploit all samples to train the model and improve pseudo-label quality.
Plain English Explanation
The paper is about a machine learning technique called domain generalization. The goal of domain generalization is to train a model on data from certain source domains, so that the model can perform well on new, unseen target domains.
Typically, domain generalization methods require a lot of labeled data from the source domains. This can be time-consuming and expensive to obtain in real-world applications. The paper tackles a more challenging setting called semi-supervised domain generalization, where there is only a small amount of labeled data available in each source domain.
To address this, the authors propose a method called MultiMatch. The key ideas are:
- Mitigate domain gap: Reducing the differences between the source domains, so the model can generalize better to the target domain.
- Exploit all samples: Using both labeled and unlabeled samples from the source domains to train the model and improve the quality of the automatically generated "pseudo-labels".
The paper shows that these two principles can help the model perform well on the unseen target domain, even with limited labeled data in the source domains.
Technical Explanation
The paper proposes a semi-supervised domain generalization (SSDG) method called MultiMatch, which extends the FixMatch algorithm to a multi-task learning framework.
The key technical ideas are:
-
Multi-task learning framework: The authors treat each source domain as a separate "local" task, and an additional "global" task is used to learn a model that can generalize to the unseen target domain. This allows the model to effectively leverage all the training samples while mitigating interference between different domains.
-
Independent BN and classifier: Each local task has its own batch normalization (BN) layers and classifier, which can help alleviate the impact of domain shift during pseudo-labeling.
-
Shared parameters: Most of the model parameters are shared across all tasks, allowing the model to be trained efficiently using all available samples.
-
Fusion of local and global predictions: During both training and testing, the authors fuse the predictions from the local tasks and the global task to further boost the pseudo-label accuracy and the model's generalization ability.
The authors evaluate MultiMatch on several benchmark domain generalization datasets and show that it outperforms existing semi-supervised methods and the SSDG method.
Critical Analysis
The paper proposes a novel SSDG method that effectively leverages limited labeled data and unlabeled samples to improve domain generalization. The multi-task learning framework, with independent BN and classifiers for each task, is a clever way to mitigate the impact of domain shift.
However, the paper does not discuss the potential limitations of the method. For example, it's unclear how the method would scale to a large number of source domains, or how sensitive it is to the choice of hyperparameters. Additionally, the paper does not compare MultiMatch to other SSDG approaches or domain generalization methods that utilize meta-learning, which could provide useful insights.
Overall, the proposed MultiMatch method is a promising approach to SSDG, but further research is needed to better understand its strengths, limitations, and potential extensions.
Conclusion
The paper presents a semi-supervised domain generalization (SSDG) method called MultiMatch, which extends the FixMatch algorithm to a multi-task learning framework. The key ideas are to mitigate the impact of domain gap and exploit all available samples, including unlabeled data, to improve the quality of pseudo-labels and the model's generalization ability.
The authors show that MultiMatch outperforms existing semi-supervised methods and the SSDG method on several benchmark domain generalization datasets. This work contributes to the growing field of domain generalization, which is crucial for developing machine learning models that can be reliably deployed in real-world, diverse environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
MultiMatch: Multi-task Learning for Semi-supervised Domain Generalization
Lei Qi, Hongpeng Yang, Yinghuan Shi, Xin Geng
Domain generalization (DG) aims at learning a model on source domains to well generalize on the unseen target domain. Although it has achieved great success, most of existing methods require the label information for all training samples in source domains, which is time-consuming and expensive in the real-world application. In this paper, we resort to solving the semi-supervised domain generalization (SSDG) task, where there are a few label information in each source domain. To address the task, we first analyze the theory of the multi-domain learning, which highlights that 1) mitigating the impact of domain gap and 2) exploiting all samples to train the model can effectively reduce the generalization error in each source domain so as to improve the quality of pseudo-labels. According to the analysis, we propose MultiMatch, i.e., extending FixMatch to the multi-task learning framework, producing the high-quality pseudo-label for SSDG. To be specific, we consider each training domain as a single task (i.e., local task) and combine all training domains together (i.e., global task) to train an extra task for the unseen test domain. In the multi-task framework, we utilize the independent BN and classifier for each task, which can effectively alleviate the interference from different domains during pseudo-labeling. Also, most of parameters in the framework are shared, which can be trained by all training samples sufficiently. Moreover, to further boost the pseudo-label accuracy and the model's generalization, we fuse the predictions from the global task and local task during training and testing, respectively. A series of experiments validate the effectiveness of the proposed method, and it outperforms the existing semi-supervised methods and the SSDG method on several benchmark DG datasets.
Read more4/30/2024

0
Domain-Guided Weight Modulation for Semi-Supervised Domain Generalization
Chamuditha Jayanaga Galappaththige, Zachary Izzo, Xilin He, Honglu Zhou, Muhammad Haris Khan
Unarguably, deep learning models capable of generalizing to unseen domain data while leveraging a few labels are of great practical significance due to low developmental costs. In search of this endeavor, we study the challenging problem of semi-supervised domain generalization (SSDG), where the goal is to learn a domain-generalizable model while using only a small fraction of labeled data and a relatively large fraction of unlabeled data. Domain generalization (DG) methods show subpar performance under the SSDG setting, whereas semi-supervised learning (SSL) methods demonstrate relatively better performance, however, they are considerably poor compared to the fully-supervised DG methods. Towards handling this new, but challenging problem of SSDG, we propose a novel method that can facilitate the generation of accurate pseudo-labels under various domain shifts. This is accomplished by retaining the domain-level specialism in the classifier during training corresponding to each source domain. Specifically, we first create domain-level information vectors on the fly which are then utilized to learn a domain-aware mask for modulating the classifier's weights. We provide a mathematical interpretation for the effect of this modulation procedure on both pseudo-labeling and model training. Our method is plug-and-play and can be readily applied to different SSL baselines for SSDG. Extensive experiments on six challenging datasets in two different SSDG settings show that our method provides visible gains over the various strong SSL-based SSDG baselines.
Read more9/6/2024

0
Towards Generalizing to Unseen Domains with Few Labels
Chamuditha Jayanga Galappaththige, Sanoojan Baliah, Malitha Gunawardhana, Muhammad Haris Khan
We approach the challenge of addressing semi-supervised domain generalization (SSDG). Specifically, our aim is to obtain a model that learns domain-generalizable features by leveraging a limited subset of labelled data alongside a substantially larger pool of unlabeled data. Existing domain generalization (DG) methods which are unable to exploit unlabeled data perform poorly compared to semi-supervised learning (SSL) methods under SSDG setting. Nevertheless, SSL methods have considerable room for performance improvement when compared to fully-supervised DG training. To tackle this underexplored, yet highly practical problem of SSDG, we make the following core contributions. First, we propose a feature-based conformity technique that matches the posterior distributions from the feature space with the pseudo-label from the model's output space. Second, we develop a semantics alignment loss to learn semantically-compatible representations by regularizing the semantic structure in the feature space. Our method is plug-and-play and can be readily integrated with different SSL-based SSDG baselines without introducing any additional parameters. Extensive experimental results across five challenging DG benchmarks with four strong SSL baselines suggest that our method provides consistent and notable gains in two different SSDG settings.
Read more5/8/2024
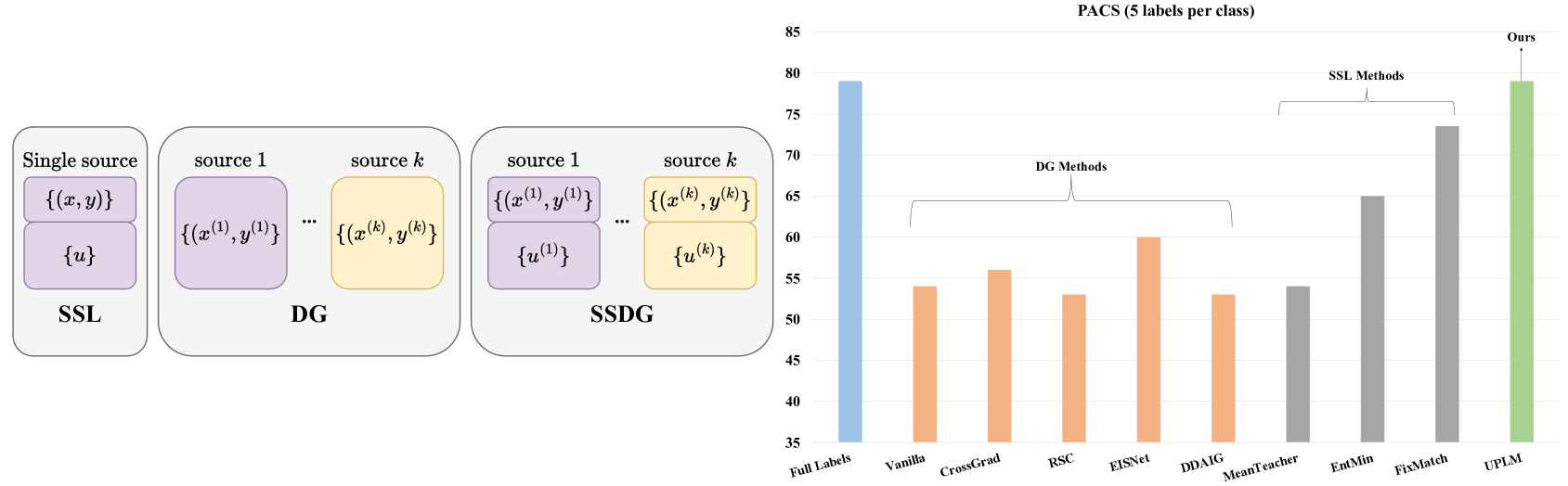
0
Improving Pseudo-labelling and Enhancing Robustness for Semi-Supervised Domain Generalization
Adnan Khan, Mai A. Shaaban, Muhammad Haris Khan
Beyond attaining domain generalization (DG), visual recognition models should also be data-efficient during learning by leveraging limited labels. We study the problem of Semi-Supervised Domain Generalization (SSDG) which is crucial for real-world applications like automated healthcare. SSDG requires learning a cross-domain generalizable model when the given training data is only partially labelled. Empirical investigations reveal that the DG methods tend to underperform in SSDG settings, likely because they are unable to exploit the unlabelled data. Semi-supervised learning (SSL) shows improved but still inferior results compared to fully-supervised learning. A key challenge, faced by the best-performing SSL-based SSDG methods, is selecting accurate pseudo-labels under multiple domain shifts and reducing overfitting to source domains under limited labels. In this work, we propose new SSDG approach, which utilizes a novel uncertainty-guided pseudo-labelling with model averaging (UPLM). Our uncertainty-guided pseudo-labelling (UPL) uses model uncertainty to improve pseudo-labelling selection, addressing poor model calibration under multi-source unlabelled data. The UPL technique, enhanced by our novel model averaging (MA) strategy, mitigates overfitting to source domains with limited labels. Extensive experiments on key representative DG datasets suggest that our method demonstrates effectiveness against existing methods. Our code and chosen labelled data seeds are available on GitHub: https://github.com/Adnan-Khan7/UPLM
Read more9/26/2024