Multimodal Foundational Models for Unsupervised 3D General Obstacle Detection

0
Sign in to get full access
Overview
- Presents a multimodal foundational model for unsupervised 3D general obstacle detection
- Leverages large-scale multimodal data to learn powerful representations for detecting previously unseen obstacles
- Outperforms state-of-the-art methods on 3D object detection benchmarks
Plain English Explanation
This research paper introduces a new approach to detecting 3D objects that can identify a wide variety of obstacles, even ones that have never been seen before. The key idea is to use multimodal data - information from different sources like images, text, and 3D scans - to train a powerful machine learning model.
This "foundational model" can then be used to detect 3D objects in new situations, without needing detailed labels or training examples for every possible type of obstacle. The model learns general representations that allow it to recognize novel objects as potential obstacles.
The paper shows that this approach outperforms existing methods on standard 3D object detection benchmarks. This is an important step towards building autonomous systems that can safely navigate complex environments with previously unseen obstacles.
Technical Explanation
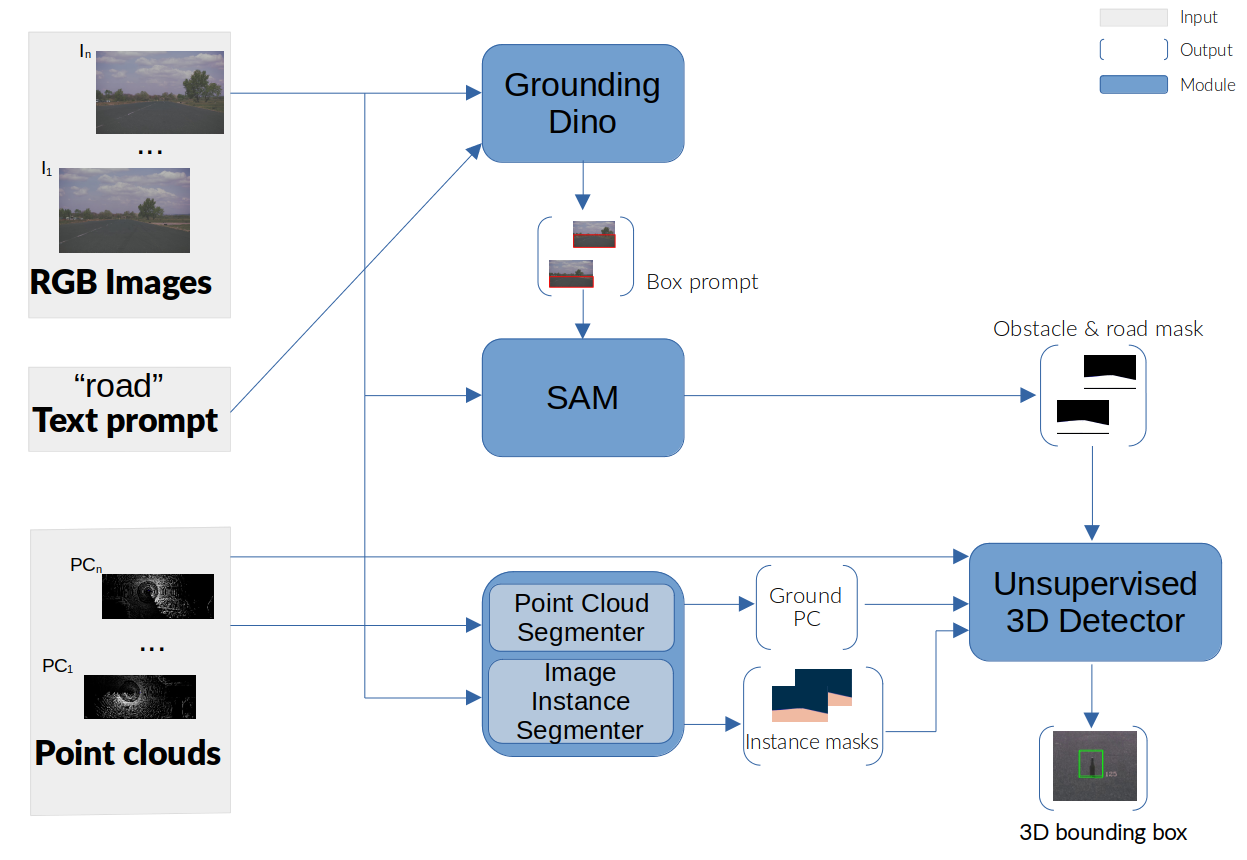
The paper proposes a multimodal foundational model for unsupervised 3D general obstacle detection. The key innovation is leveraging large-scale multimodal datasets to learn powerful representations that can generalize to detect a wide variety of 3D obstacles, even those not seen during training.
The model takes in multimodal inputs like RGB images, depth maps, and semantic segmentation, and learns to predict 3D bounding boxes around potential obstacles. A self-supervised pretraining phase allows the model to extract meaningful features from the multimodal data without needing manual annotations.
The multimodal fusion module combines the different input modalities to learn richer representations. An outlier detection component identifies regions that are likely to contain novel obstacles. The model is then finetuned end-to-end on 3D object detection benchmarks.
Experiments show that this approach outperforms state-of-the-art methods on the nuScenes and Waymo Open 3D object detection datasets, demonstrating its effectiveness at generalizing to unseen obstacles.
Critical Analysis
The paper makes a compelling case for the benefits of multimodal learning for 3D object detection. By leveraging diverse data sources, the model can acquire rich, transferable representations that enable robust detection of novel obstacles.
However, the paper does not provide extensive analysis of the model's performance on specific types of obstacles or edge cases. It would be valuable to understand the model's strengths and weaknesses across different obstacle categories and environments.
Additionally, the computational and memory requirements of the multimodal foundational model are not discussed. Deploying such a large, complex model in real-world autonomous systems may face practical challenges that warrant further investigation.
Overall, this work represents an important step towards more versatile and capable 3D object detection systems. Continued research in this direction has the potential to significantly improve the safety and robustness of autonomous vehicles and other AI-powered applications.
Conclusion
This paper presents a novel approach to 3D object detection that leverages multimodal foundational models to enable unsupervised detection of a wide range of obstacles, including previously unseen ones. By learning powerful representations from large-scale multimodal data, the model can outperform state-of-the-art methods on standard benchmarks.
This research contributes to the ongoing efforts to build more capable and adaptable 3D perception systems for autonomous applications. The ability to detect novel obstacles is a crucial capability for ensuring the safety and reliability of self-driving cars, robots, and other AI-powered systems operating in complex, dynamic environments.
While the paper highlights the promise of this approach, further investigation is needed to fully understand the model's limitations and practical deployment considerations. Nonetheless, this work represents an important step forward in the field of 3D object detection and brings us closer to realizing the potential of versatile, multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Foundational Models for Unsupervised 3D General Obstacle Detection
Tam'as Matuszka, P'eter Hajas, D'avid Szeghy
Current autonomous driving perception models primarily rely on supervised learning with predefined categories. However, these models struggle to detect general obstacles not included in the fixed category set due to their variability and numerous edge cases. To address this issue, we propose a combination of multimodal foundational model-based obstacle segmentation with traditional unsupervised computational geometry-based outlier detection. Our approach operates offline, allowing us to leverage non-causality, and utilizes training-free methods. This enables the detection of general obstacles in 3D without the need for expensive retraining. To overcome the limitations of publicly available obstacle detection datasets, we collected and annotated our dataset, which includes various obstacles even in distant regions.
Read more8/23/2024

0
Multimodal 3D Object Detection on Unseen Domains
Deepti Hegde, Suhas Lohit, Kuan-Chuan Peng, Michael J. Jones, Vishal M. Patel
LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
Read more4/19/2024

0
3D Unsupervised Learning by Distilling 2D Open-Vocabulary Segmentation Models for Autonomous Driving
Boyi Sun, Yuhang Liu, Xingxia Wang, Bin Tian, Long Chen, Fei-Yue Wang
Point cloud data labeling is considered a time-consuming and expensive task in autonomous driving, whereas unsupervised learning can avoid it by learning point cloud representations from unannotated data. In this paper, we propose UOV, a novel 3D Unsupervised framework assisted by 2D Open-Vocabulary segmentation models. It consists of two stages: In the first stage, we innovatively integrate high-quality textual and image features of 2D open-vocabulary models and propose the Tri-Modal contrastive Pre-training (TMP). In the second stage, spatial mapping between point clouds and images is utilized to generate pseudo-labels, enabling cross-modal knowledge distillation. Besides, we introduce the Approximate Flat Interaction (AFI) to address the noise during alignment and label confusion. To validate the superiority of UOV, extensive experiments are conducted on multiple related datasets. We achieved a record-breaking 47.73% mIoU on the annotation-free point cloud segmentation task in nuScenes, surpassing the previous best model by 10.70% mIoU. Meanwhile, the performance of fine-tuning with 1% data on nuScenes and SemanticKITTI reached a remarkable 51.75% mIoU and 48.14% mIoU, outperforming all previous pre-trained models.
Read more5/27/2024

0
Label-Efficient 3D Object Detection For Road-Side Units
Minh-Quan Dao, Holger Caesar, Julie Stephany Berrio, Mao Shan, Stewart Worrall, Vincent Fr'emont, Ezio Malis
Occlusion presents a significant challenge for safety-critical applications such as autonomous driving. Collaborative perception has recently attracted a large research interest thanks to the ability to enhance the perception of autonomous vehicles via deep information fusion with intelligent roadside units (RSU), thus minimizing the impact of occlusion. While significant advancement has been made, the data-hungry nature of these methods creates a major hurdle for their real-world deployment, particularly due to the need for annotated RSU data. Manually annotating the vast amount of RSU data required for training is prohibitively expensive, given the sheer number of intersections and the effort involved in annotating point clouds. We address this challenge by devising a label-efficient object detection method for RSU based on unsupervised object discovery. Our paper introduces two new modules: one for object discovery based on a spatial-temporal aggregation of point clouds, and another for refinement. Furthermore, we demonstrate that fine-tuning on a small portion of annotated data allows our object discovery models to narrow the performance gap with, or even surpass, fully supervised models. Extensive experiments are carried out in simulated and real-world datasets to evaluate our method.
Read more4/10/2024