Multimodal Large Language Model Driven Scenario Testing for Autonomous Vehicles

0

Sign in to get full access
Overview
- Large language models (LLMs) and vision-language models (VLMs) can be used to generate diverse driving scenarios for autonomous vehicle testing.
- The research explores integrating multimodal LLMs into the autonomous vehicle testing pipeline to enhance scenario generation.
- Key aspects include prompt engineering, scenario generation, and evaluating the quality and diversity of generated scenarios.
Plain English Explanation
Autonomous vehicles need to be thoroughly tested in a wide range of driving scenarios before they can be safely deployed on public roads. Multimodal large language models can help with this testing process by generating diverse and realistic driving scenarios that the autonomous vehicle can then navigate.
The researchers in this paper explored ways to harness the power of these large language models to create novel driving scenarios. They experimented with different prompt engineering techniques to guide the language models in generating diverse and high-quality driving scenarios.
The generated scenarios were then evaluated to ensure they were realistic, challenging, and covered a broad range of driving conditions. This helps ensure the autonomous vehicle is trained and tested on a comprehensive set of scenarios, improving its safety and robustness.
Technical Explanation
The paper describes a framework for using multimodal large language models to generate diverse driving scenarios for autonomous vehicle testing. The researchers leveraged the ability of LLMs and VLMs to understand and reason about the physical world, as captured in their training data, to create novel and realistic driving scenarios.
The approach involves prompt engineering to guide the language models in generating relevant and high-quality scenarios. The researchers experimented with different prompting strategies, evaluating the diversity, complexity, and realism of the generated scenarios.
The generated scenarios were then used to enhance the training and testing of autonomous vehicle systems, helping to ensure they can handle a wide range of driving conditions. The results demonstrate the potential of multimodal LLMs to significantly improve the scenario-based testing of autonomous vehicles.
Critical Analysis
The paper provides a comprehensive exploration of using multimodal LLMs for autonomous vehicle scenario testing. However, the authors acknowledge some limitations, such as the potential for generated scenarios to be biased or unrealistic if the underlying language model has inherent biases or lacks certain domain knowledge.
Additionally, the evaluation of the generated scenarios could be further refined to better assess their suitability for autonomous vehicle testing. The authors suggest exploring more advanced metrics or human-in-the-loop evaluation to ensure the scenarios are truly representative of real-world driving conditions.
Overall, the research represents an important step forward in leveraging the powerful capabilities of large language models to enhance the testing and development of autonomous vehicle systems. Continued advancements in this area could lead to significant improvements in the safety and reliability of self-driving cars.
Conclusion
This research demonstrates the potential of multimodal large language models to revolutionize the scenario-based testing of autonomous vehicles. By generating diverse and realistic driving scenarios, these language models can help ensure autonomous vehicle systems are trained and tested on a comprehensive set of conditions, improving their safety and robustness.
The findings suggest that integrating multimodal LLMs into the autonomous vehicle development pipeline could lead to significant advancements in the field, paving the way for safer and more capable self-driving cars. As the technology continues to evolve, further research and refinement of these techniques will be crucial for realizing the full potential of autonomous vehicle systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Large Language Model Driven Scenario Testing for Autonomous Vehicles
Qiujing Lu, Xuanhan Wang, Yiwei Jiang, Guangming Zhao, Mingyue Ma, Shuo Feng
The generation of corner cases has become increasingly crucial for efficiently testing autonomous vehicles prior to road deployment. However, existing methods struggle to accommodate diverse testing requirements and often lack the ability to generalize to unseen situations, thereby reducing the convenience and usability of the generated scenarios. A method that facilitates easily controllable scenario generation for efficient autonomous vehicles (AV) testing with realistic and challenging situations is greatly needed. To address this, we proposed OmniTester: a multimodal Large Language Model (LLM) based framework that fully leverages the extensive world knowledge and reasoning capabilities of LLMs. OmniTester is designed to generate realistic and diverse scenarios within a simulation environment, offering a robust solution for testing and evaluating AVs. In addition to prompt engineering, we employ tools from Simulation of Urban Mobility to simplify the complexity of codes generated by LLMs. Furthermore, we incorporate Retrieval-Augmented Generation and a self-improvement mechanism to enhance the LLM's understanding of scenarios, thereby increasing its ability to produce more realistic scenes. In the experiments, we demonstrated the controllability and realism of our approaches in generating three types of challenging and complex scenarios. Additionally, we showcased its effectiveness in reconstructing new scenarios described in crash report, driven by the generalization capability of LLMs.
Read more9/11/2024
0
Testing Large Language Models on Driving Theory Knowledge and Skills for Connected Autonomous Vehicles
Zuoyin Tang, Jianhua He, Dashuai Pei, Kezhong Liu, Tao Gao
Handling long tail corner cases is a major challenge faced by autonomous vehicles (AVs). While large language models (LLMs) hold great potentials to handle the corner cases with excellent generalization and explanation capabilities and received increasing research interest on application to autonomous driving, there are still technical barriers to be tackled, such as strict model performance and huge computing resource requirements of LLMs. In this paper, we investigate a new approach of applying remote or edge LLMs to support autonomous driving. A key issue for such LLM assisted driving system is the assessment of LLMs on their understanding of driving theory and skills, ensuring they are qualified to undertake safety critical driving assistance tasks for CAVs. We design and run driving theory tests for several proprietary LLM models (OpenAI GPT models, Baidu Ernie and Ali QWen) and open-source LLM models (Tsinghua MiniCPM-2B and MiniCPM-Llama3-V2.5) with more than 500 multiple-choices theory test questions. Model accuracy, cost and processing latency are measured from the experiments. Experiment results show that while model GPT-4 passes the test with improved domain knowledge and Ernie has an accuracy of 85% (just below the 86% passing threshold), other LLM models including GPT-3.5 fail the test. For the test questions with images, the multimodal model GPT4-o has an excellent accuracy result of 96%, and the MiniCPM-Llama3-V2.5 achieves an accuracy of 76%. While GPT-4 holds stronger potential for CAV driving assistance applications, the cost of using model GPT4 is much higher, almost 50 times of that of using GPT3.5. The results can help make decision on the use of the existing LLMs for CAV applications and balancing on the model performance and cost.
Read more7/25/2024
⛏️
0
Chat2Scenario: Scenario Extraction From Dataset Through Utilization of Large Language Model
Yongqi Zhao, Wenbo Xiao, Tomislav Mihalj, Jia Hu, Arno Eichberger
The advent of Large Language Models (LLM) provides new insights to validate Automated Driving Systems (ADS). In the herein-introduced work, a novel approach to extracting scenarios from naturalistic driving datasets is presented. A framework called Chat2Scenario is proposed leveraging the advanced Natural Language Processing (NLP) capabilities of LLM to understand and identify different driving scenarios. By inputting descriptive texts of driving conditions and specifying the criticality metric thresholds, the framework efficiently searches for desired scenarios and converts them into ASAM OpenSCENARIO and IPG CarMaker text files. This methodology streamlines the scenario extraction process and enhances efficiency. Simulations are executed to validate the efficiency of the approach. The framework is presented based on a user-friendly web app and is accessible via the following link: https://github.com/ftgTUGraz/Chat2Scenario.
Read more4/29/2024
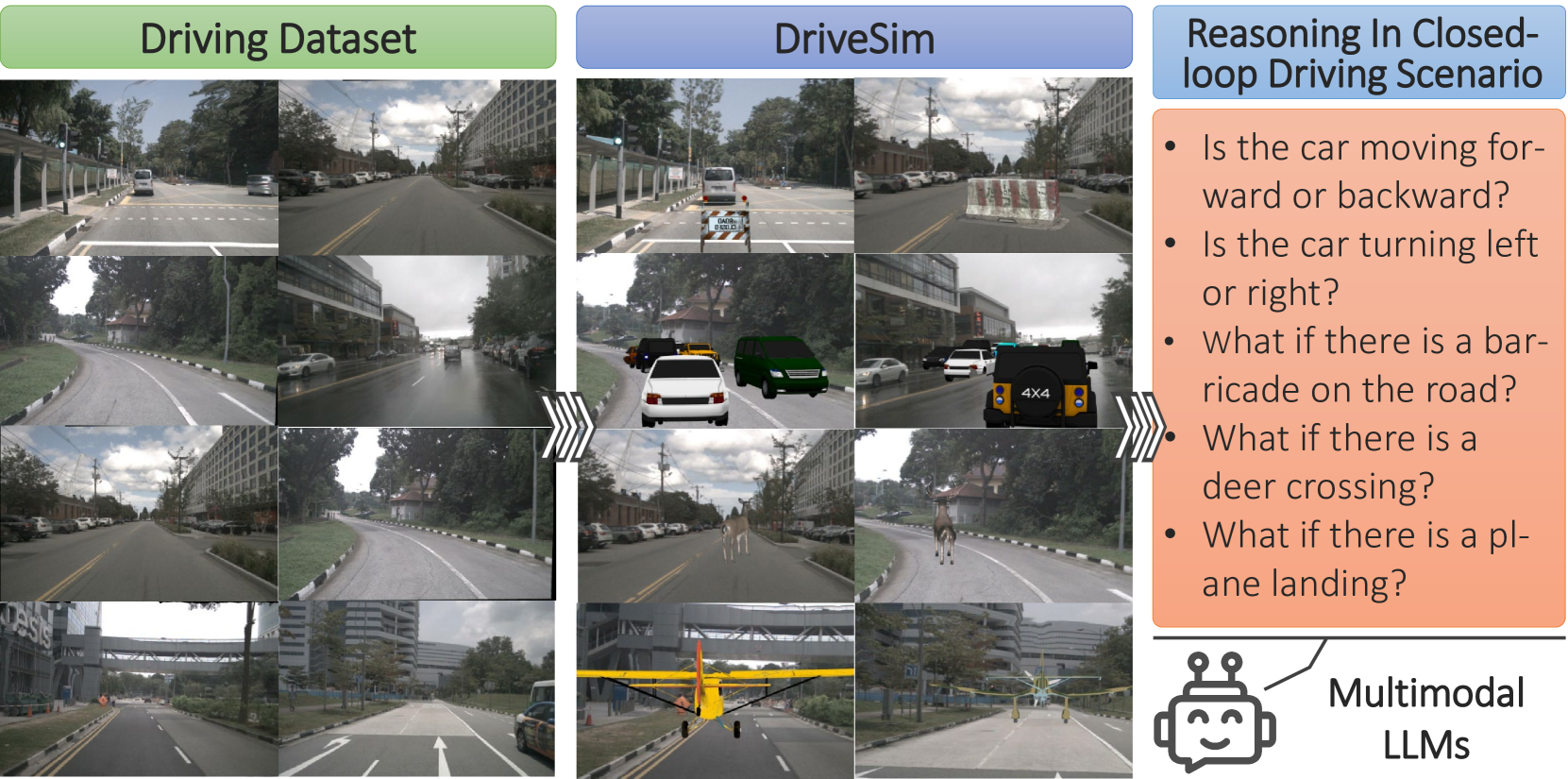
0
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
Read more5/10/2024