Multimodal Large Language Models with Fusion Low Rank Adaptation for Device Directed Speech Detection
2406.09617
0
0

Abstract
Although Large Language Models (LLMs) have shown promise for human-like conversations, they are primarily pre-trained on text data. Incorporating audio or video improves performance, but collecting large-scale multimodal data and pre-training multimodal LLMs is challenging. To this end, we propose a Fusion Low Rank Adaptation (FLoRA) technique that efficiently adapts a pre-trained unimodal LLM to consume new, previously unseen modalities via low rank adaptation. For device-directed speech detection, using FLoRA, the multimodal LLM achieves 22% relative reduction in equal error rate (EER) over the text-only approach and attains performance parity with its full fine-tuning (FFT) counterpart while needing to tune only a fraction of its parameters. Furthermore, with the newly introduced adapter dropout, FLoRA is robust to missing data, improving over FFT by 20% lower EER and 56% lower false accept rate. The proposed approach scales well for model sizes from 16M to 3B parameters.
Create account to get full access
Overview
- This paper introduces a multimodal large language model that uses Fusion Low Rank Adaptation (FLORA) to enable device-directed speech detection.
- The model leverages the strengths of both text and audio inputs to improve performance on this task.
- The FLORA technique allows for efficient adaption of the model to specific devices and scenarios without retraining the entire model.
Plain English Explanation
The researchers have created a powerful language model that can understand both text and speech. This model is designed to detect when a speech command is directed at a specific device, like a smart speaker or smartphone.
To do this, the model takes in both the text of what was said and the audio recording of the speech. By combining these two sources of information, the model can more accurately determine if the speech was intended for a particular device.
The key innovation in this work is the use of Fusion Low Rank Adaptation (FLORA). This technique allows the model to be fine-tuned for different devices or scenarios without having to retrain the entire model from scratch. This makes the model more flexible and efficient to deploy in the real world.
Overall, this research brings us closer to having language models that can seamlessly integrate with and understand the world around them, like the intelligent digital assistants of science fiction. By combining text and audio, the model can more accurately interpret human speech and intentions.
Technical Explanation
The researchers propose a multimodal large language model that leverages both text and audio inputs for the task of device-directed speech detection. The model architecture includes a text encoder and an audio encoder, which process the respective modalities and fuse the representations at multiple layers.
To enable efficient adaptation of the model to different devices and scenarios, the researchers employ the Fusion Low Rank Adaptation (FLORA) technique. FLORA introduces low-rank adaptation modules that can be fine-tuned on specific tasks or environments, while keeping the core model parameters frozen. This allows for parameter-efficient adaptation without the need to retrain the entire model.
The model is trained on a dataset of spoken phrases directed at various devices, with annotated labels indicating the target device. During inference, the model takes both the text transcript and the audio recording as input, and outputs a predicted target device.
The researchers demonstrate the effectiveness of their approach through experiments on multiple benchmarks, showing improvements over baseline models that use only text or audio alone. They also analyze the performance of the FLORA adaptation modules, highlighting the benefits of this technique for deployment in real-world scenarios.
Critical Analysis
The paper presents a compelling approach to device-directed speech detection by leveraging the complementary strengths of text and audio modalities. The use of FLORA for efficient adaptation is a particularly interesting contribution, as it addresses the challenge of deploying large language models in diverse real-world settings.
One potential limitation of the work is the reliance on a specific dataset for training and evaluation. While the researchers demonstrate strong performance on the provided benchmarks, it would be valuable to see how the model generalizes to a wider range of device types, accents, and environmental conditions.
Additionally, the paper does not provide a detailed analysis of the types of errors the model makes or the specific failure modes. A deeper exploration of the model's limitations and potential biases would help readers understand the practical challenges in deploying such systems.
Lastly, the paper could have benefited from a more thorough discussion of the societal implications of this technology. As language models become more pervasive and integrated with our physical devices, there are important privacy, security, and ethical considerations that should be addressed.
Overall, this research represents an important step towards developing more intelligent and adaptable multimodal language models. The FLORA technique, in particular, has broader applicability beyond the specific use case presented here and could be a valuable tool for personalized federated learning and cross-modal adaptation of large language models.
Conclusion
This paper introduces a multimodal large language model that combines text and audio information to enable more accurate device-directed speech detection. The key innovation is the use of Fusion Low Rank Adaptation (FLORA), which allows the model to be efficiently adapted to different devices and scenarios without retraining the entire model.
The results demonstrate the benefits of this approach, showing improvements over baseline models that use only a single modality. The FLORA technique in particular has broader implications for personalized federated learning and cross-modal adaptation of large language models.
As language models become more integrated with our physical devices, this research represents an important step towards developing intelligent systems that can seamlessly understand and interact with the world around us. However, the deployment of such technology also raises important privacy, security, and ethical considerations that warrant further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
FLoRA: Enhancing Vision-Language Models with Parameter-Efficient Federated Learning
Duy Phuong Nguyen, J. Pablo Munoz, Ali Jannesari
0
0
In the rapidly evolving field of artificial intelligence, multimodal models, e.g., integrating vision and language into visual-language models (VLMs), have become pivotal for many applications, ranging from image captioning to multimodal search engines. Among these models, the Contrastive Language-Image Pre-training (CLIP) model has demonstrated remarkable performance in understanding and generating nuanced relationships between text and images. However, the conventional training of such models often requires centralized aggregation of vast datasets, posing significant privacy and data governance challenges. To address these concerns, this paper proposes a novel approach that leverages Federated Learning and parameter-efficient adapters, i.e., Low-Rank Adaptation (LoRA), to train VLMs. This methodology preserves data privacy by training models across decentralized data sources and ensures model adaptability and efficiency through LoRA's parameter-efficient fine-tuning. Our approach accelerates training time by up to 34.72 times and requires 2.47 times less memory usage than full fine-tuning.
4/24/2024

FDLoRA: Personalized Federated Learning of Large Language Model via Dual LoRA Tuning
Jiaxing QI, Zhongzhi Luan, Shaohan Huang, Carol Fung, Hailong Yang, Depei Qian
0
0
Large language models (LLMs) have emerged as important components across various fields, yet their training requires substantial computation resources and abundant labeled data. It poses a challenge to robustly training LLMs for individual users (clients). To tackle this challenge, the intuitive idea is to introduce federated learning (FL), which can collaboratively train models on distributed private data. However, existing methods suffer from the challenges of data heterogeneity, system heterogeneity, and model size, resulting in suboptimal performance and high costs. In this work, we proposed a variant of personalized federated learning (PFL) framework, namely FDLoRA, which allows the client to be a single device or a cluster and adopts low-rank adaptation (LoRA) tuning. FDLoRA sets dual LoRA modules on each client to capture personalized and global knowledge, respectively, and only the global LoRA module uploads parameters to the central server to aggregate cross-client knowledge. Finally, an adaptive fusion approach is employed to combine the parameters of the dual LoRAs. This enables FDLoRA to make effective use of private data distributed across different clients, thereby improving performance on the client without incurring high communication and computing costs. We conducted extensive experiments in two practice scenarios. The results demonstrate that FDLoRA outperforms six baselines in terms of performance, stability, robustness, computation cost, and communication cost.
6/13/2024
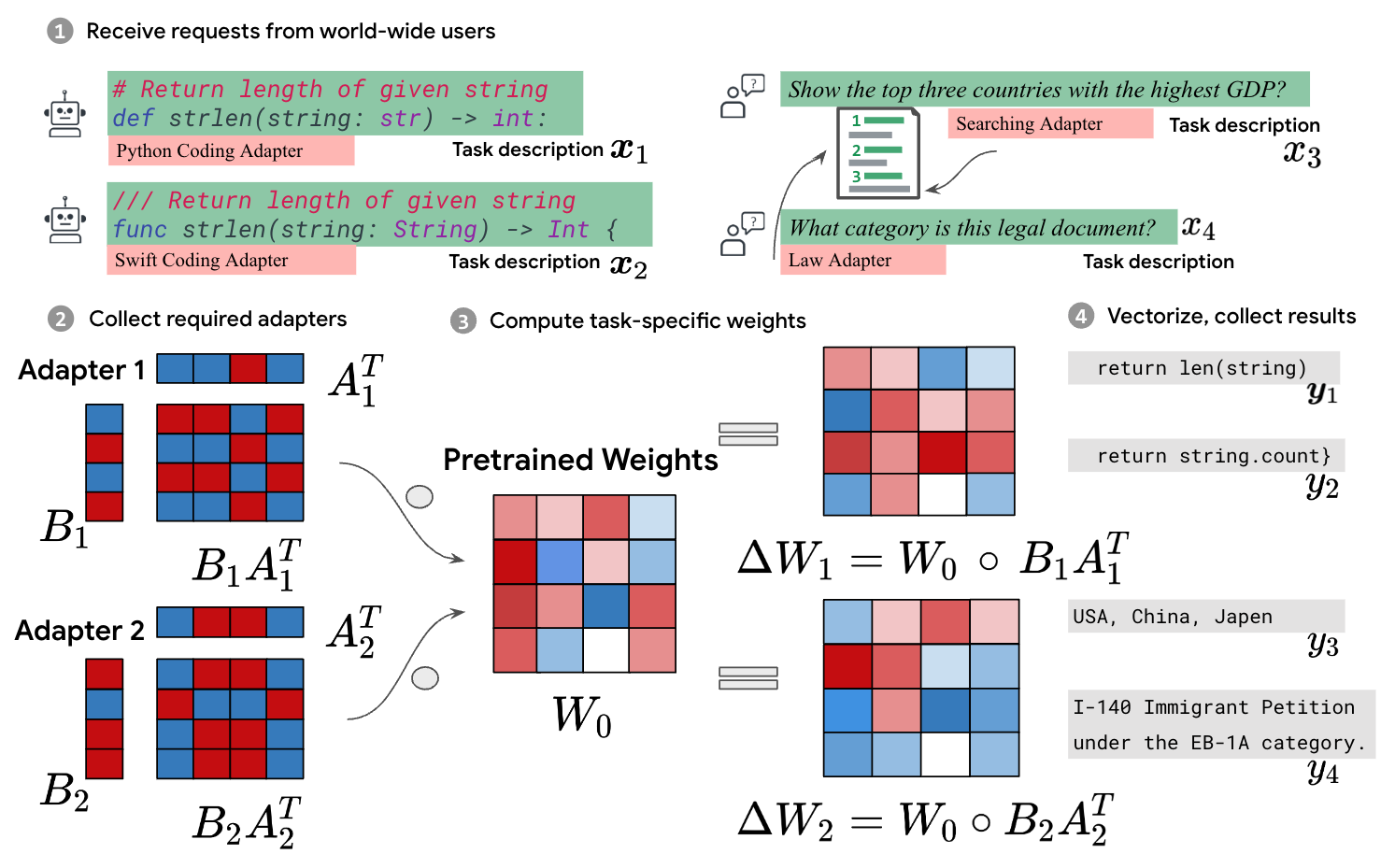
Batched Low-Rank Adaptation of Foundation Models
Yeming Wen, Swarat Chaudhuri
0
0
Low-Rank Adaptation (LoRA) has recently gained attention for fine-tuning foundation models by incorporating trainable low-rank matrices, thereby reducing the number of trainable parameters. While LoRA offers numerous advantages, its applicability for real-time serving to a diverse and global user base is constrained by its incapability to handle multiple task-specific adapters efficiently. This imposes a performance bottleneck in scenarios requiring personalized, task-specific adaptations for each incoming request. To mitigate this constraint, we introduce Fast LoRA (FLoRA), a framework in which each input example in a minibatch can be associated with its unique low-rank adaptation weights, allowing for efficient batching of heterogeneous requests. We empirically demonstrate that FLoRA retains the performance merits of LoRA, showcasing competitive results on the MultiPL-E code generation benchmark spanning over 8 languages and a multilingual speech recognition task across 6 languages.
4/29/2024

Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
Frank Palma Gomez, Ramon Sanabria, Yun-hsuan Sung, Daniel Cer, Siddharth Dalmia, Gustavo Hernandez Abrego
0
0
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
4/5/2024