A Multimodal Object-level Contrast Learning Method for Cancer Survival Risk Prediction

0

Sign in to get full access
Overview
- The research paper proposes a multimodal object-level contrast learning method for predicting cancer survival risk.
- The method combines pathological images and clinical data to learn discriminative visual and semantic features.
- The key ideas are object-level contrast learning and multimodal fusion to improve survival prediction performance.
Plain English Explanation
The paper focuses on using medical images and patient data to predict a cancer patient's risk of survival. Traditionally, this type of prediction has been done using either just the medical images or just the patient data. However, the researchers in this paper believe that combining both types of information - the images and the data - can lead to more accurate predictions.
The core idea is to learn discriminative visual and semantic features by looking at the individual objects or regions within the medical images, rather than just the overall image. This "object-level contrast learning" allows the model to focus on the most important visual cues for predicting survival.
Additionally, the model fuses the visual and semantic information from the images and patient data to make the final survival prediction. This "multimodal" approach capitalizes on the complementary strengths of the two data sources.
Technical Explanation
The researchers propose a novel object-level contrast learning method that learns discriminative visual features from pathological images. Rather than just looking at the overall image, the model examines individual objects or regions within the image and learns to contrast them based on their relevance to predicting cancer survival.
This object-level learning is combined with multimodal fusion that integrates the visual features from the images with clinical data about the patients, such as their demographic information and medical history. The multimodal fusion allows the model to leverage the complementary strengths of the visual and semantic data sources to make more accurate survival predictions.
The researchers evaluate their multimodal object-level contrast learning method on several cancer survival prediction datasets and demonstrate significant performance improvements over existing unimodal and multimodal approaches. The insights gained from this work could advance head and neck cancer survival prediction and other cancer-related applications.
Critical Analysis
The paper presents a compelling approach that leverages the unique strengths of both visual and semantic data sources for cancer survival prediction. The object-level contrast learning is a novel and intuitive way to extract the most relevant visual features from pathological images.
However, the paper does not provide much detail on the specific object detection and segmentation algorithms used, nor the architectural details of the multimodal fusion component. Readers may be interested in understanding these technical details to fully appreciate the novelty and effectiveness of the proposed method.
Additionally, the paper only evaluates the approach on a limited number of cancer types and datasets. While the results are promising, it would be valuable to see how the method generalizes to a wider range of cancer types and patient populations.
Finally, the paper does not address potential ethical considerations around the use of AI for sensitive medical predictions, such as data privacy, algorithmic bias, and the responsible deployment of such systems in clinical practice.
Conclusion
This research paper introduces a multimodal object-level contrast learning method that outperforms existing approaches for predicting cancer survival risk. By combining discriminative visual features from pathological images with complementary clinical data, the proposed technique demonstrates significant improvements in survival prediction accuracy.
The core innovations of object-level learning and multimodal fusion could have broader implications for medical image analysis and multimodal machine learning applied to other healthcare challenges. As the field of AI-assisted cancer diagnosis and prognosis continues to evolve, this work represents an important step forward in leveraging the power of visual and semantic data sources to improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Multimodal Object-level Contrast Learning Method for Cancer Survival Risk Prediction
Zekang Yang, Hong Liu, Xiangdong Wang
Computer-aided cancer survival risk prediction plays an important role in the timely treatment of patients. This is a challenging weakly supervised ordinal regression task associated with multiple clinical factors involved such as pathological images, genomic data and etc. In this paper, we propose a new training method, multimodal object-level contrast learning, for cancer survival risk prediction. First, we construct contrast learning pairs based on the survival risk relationship among the samples in the training sample set. Then we introduce the object-level contrast learning method to train the survival risk predictor. We further extend it to the multimodal scenario by applying cross-modal constrast. Considering the heterogeneity of pathological images and genomics data, we construct a multimodal survival risk predictor employing attention-based and self-normalizing based nerural network respectively. Finally, the survival risk predictor trained by our proposed method outperforms state-of-the-art methods on two public multimodal cancer datasets for survival risk prediction.
Read more9/5/2024
🔮
0
FORESEE: Multimodal and Multi-view Representation Learning for Robust Prediction of Cancer Survival
Liangrui Pan, Yijun Peng, Yan Li, Yiyi Liang, Liwen Xu, Qingchun Liang, Shaoliang Peng
Integrating the different data modalities of cancer patients can significantly improve the predictive performance of patient survival. However, most existing methods ignore the simultaneous utilization of rich semantic features at different scales in pathology images. When collecting multimodal data and extracting features, there is a likelihood of encountering intra-modality missing data, introducing noise into the multimodal data. To address these challenges, this paper proposes a new end-to-end framework, FORESEE, for robustly predicting patient survival by mining multimodal information. Specifically, the cross-fusion transformer effectively utilizes features at the cellular level, tissue level, and tumor heterogeneity level to correlate prognosis through a cross-scale feature cross-fusion method. This enhances the ability of pathological image feature representation. Secondly, the hybrid attention encoder (HAE) uses the denoising contextual attention module to obtain the contextual relationship features and local detail features of the molecular data. HAE's channel attention module obtains global features of molecular data. Furthermore, to address the issue of missing information within modalities, we propose an asymmetrically masked triplet masked autoencoder to reconstruct lost information within modalities. Extensive experiments demonstrate the superiority of our method over state-of-the-art methods on four benchmark datasets in both complete and missing settings.
Read more5/14/2024

0
Cohort-Individual Cooperative Learning for Multimodal Cancer Survival Analysis
Huajun Zhou, Fengtao Zhou, Hao Chen
Recently, we have witnessed impressive achievements in cancer survival analysis by integrating multimodal data, e.g., pathology images and genomic profiles. However, the heterogeneity and high dimensionality of these modalities pose significant challenges for extracting discriminative representations while maintaining good generalization. In this paper, we propose a Cohort-individual Cooperative Learning (CCL) framework to advance cancer survival analysis by collaborating knowledge decomposition and cohort guidance. Specifically, first, we propose a Multimodal Knowledge Decomposition (MKD) module to explicitly decompose multimodal knowledge into four distinct components: redundancy, synergy and uniqueness of the two modalities. Such a comprehensive decomposition can enlighten the models to perceive easily overlooked yet important information, facilitating an effective multimodal fusion. Second, we propose a Cohort Guidance Modeling (CGM) to mitigate the risk of overfitting task-irrelevant information. It can promote a more comprehensive and robust understanding of the underlying multimodal data, while avoiding the pitfalls of overfitting and enhancing the generalization ability of the model. By cooperating the knowledge decomposition and cohort guidance methods, we develop a robust multimodal survival analysis model with enhanced discrimination and generalization abilities. Extensive experimental results on five cancer datasets demonstrate the effectiveness of our model in integrating multimodal data for survival analysis.
Read more4/4/2024
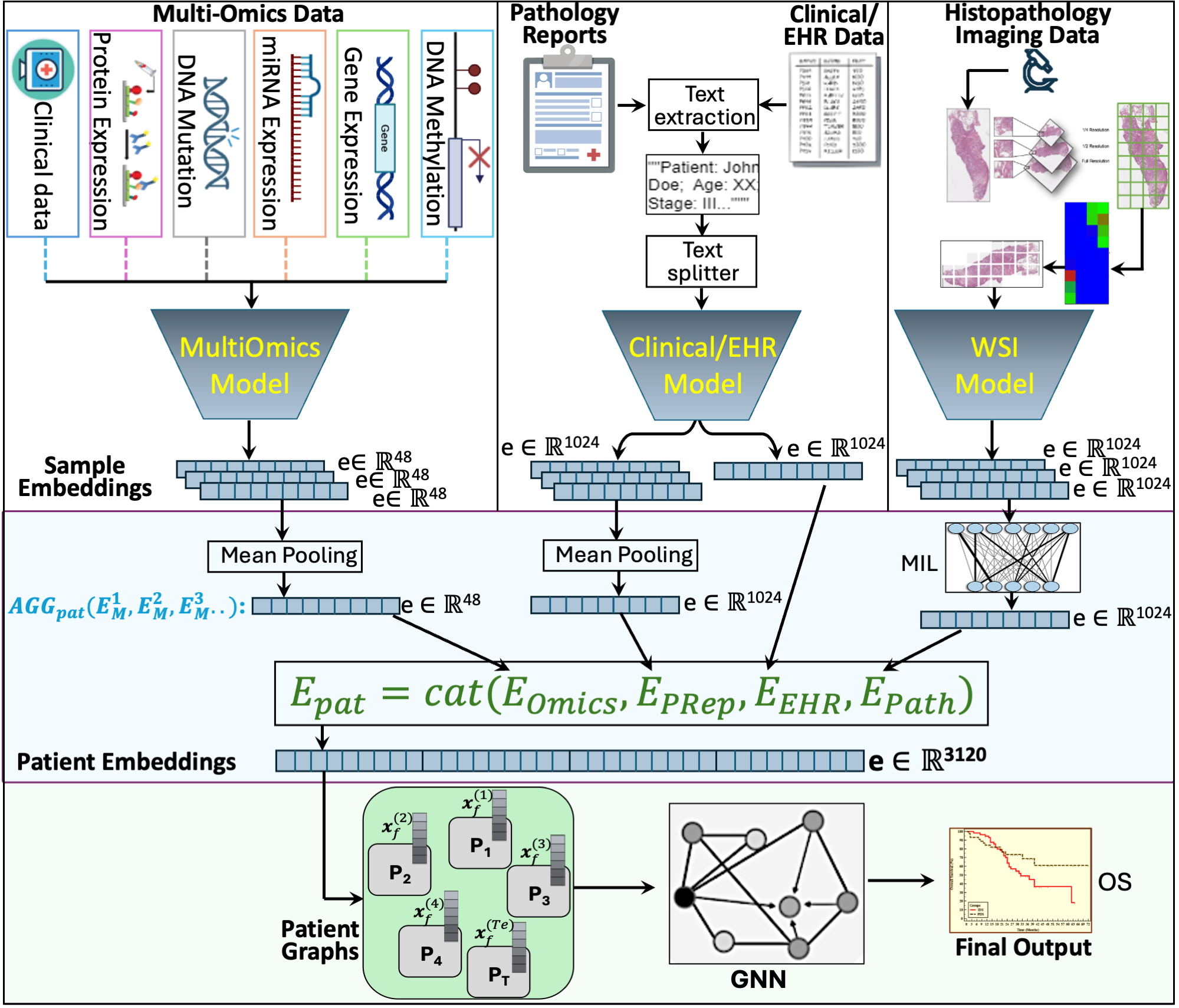
0
Embedding-based Multimodal Learning on Pan-Squamous Cell Carcinomas for Improved Survival Outcomes
Asim Waqas, Aakash Tripathi, Paul Stewart, Mia Naeini, Ghulam Rasool
Cancer clinics capture disease data at various scales, from genetic to organ level. Current bioinformatic methods struggle to handle the heterogeneous nature of this data, especially with missing modalities. We propose PARADIGM, a Graph Neural Network (GNN) framework that learns from multimodal, heterogeneous datasets to improve clinical outcome prediction. PARADIGM generates embeddings from multi-resolution data using foundation models, aggregates them into patient-level representations, fuses them into a unified graph, and enhances performance for tasks like survival analysis. We train GNNs on pan-Squamous Cell Carcinomas and validate our approach on Moffitt Cancer Center lung SCC data. Multimodal GNN outperforms other models in patient survival prediction. Converging individual data modalities across varying scales provides a more insightful disease view. Our solution aims to understand the patient's circumstances comprehensively, offering insights on heterogeneous data integration and the benefits of converging maximum data views.
Read more6/14/2024