Multimodal Unlearnable Examples: Protecting Data against Multimodal Contrastive Learning

0
Sign in to get full access
Overview
- Introduces the concept of "multimodal unlearnable examples" to protect data against multimodal contrastive learning
- Proposes a framework for generating such examples to prevent models from learning sensitive information
- Demonstrates the effectiveness of the approach through experiments on various datasets and tasks
Plain English Explanation
Multimodal contrastive learning is a powerful machine learning technique that can extract meaningful information from data with multiple modalities, such as images and text. However, this same capability can also be a vulnerability, as it allows models to potentially learn sensitive or private information from the data.
The researchers behind this paper have developed a novel approach called "multimodal unlearnable examples" to address this issue. The core idea is to generate synthetic examples that are indistinguishable from the real data, but contain no meaningful information that the model can learn. By mixing these unlearnable examples with the actual data during training, the researchers were able to effectively protect the sensitive information while still allowing the model to learn useful patterns from the remaining data.
Through a series of experiments on various datasets and tasks, the researchers demonstrated the effectiveness of their approach in preventing the model from learning sensitive information, while maintaining the model's overall performance. This work represents an important step towards developing machine learning systems that can reap the benefits of multimodal data without compromising privacy and security.
Technical Explanation
The paper introduces a framework for generating "multimodal unlearnable examples" to protect data against multimodal contrastive learning. The key components of this framework include:
-
Multimodal Data Representation: The researchers use a multimodal encoder to jointly represent the different modalities (e.g., image and text) in a shared latent space.
-
Unlearnable Example Generation: They then train a generator model to produce synthetic examples that are indistinguishable from the real data in the shared latent space, but contain no meaningful information that the target model can learn.
-
Adversarial Training: The researchers train the target model (e.g., a multimodal contrastive learning model) to learn from a mixture of real data and the unlearnable examples, effectively preventing the model from learning sensitive information while still allowing it to extract useful patterns from the remaining data.
The researchers evaluate their approach on various datasets and tasks, including image-text matching, visual question answering, and image classification. They demonstrate that their method can significantly reduce the target model's ability to learn sensitive information, while maintaining its overall performance on the primary task.
Critical Analysis
The researchers acknowledge several limitations and potential areas for further research:
-
Scalability: The proposed framework may not scale well to large-scale, high-dimensional datasets due to the computational complexity of the unlearnable example generation process.
-
Threat Model: The paper focuses on protecting against multimodal contrastive learning, but the threat model could be extended to consider other types of machine learning models and attacks.
-
Real-world Applicability: The researchers use synthetic datasets and simulated scenarios to evaluate their approach. More research is needed to understand the practical implications and challenges of deploying this framework in real-world applications.
-
Interpretability: The paper does not provide much insight into the characteristics of the generated unlearnable examples or the specific mechanisms by which they prevent the target model from learning sensitive information.
Overall, this work represents an important step towards developing more secure and privacy-preserving multimodal machine learning systems. However, further research is needed to address the identified limitations and to explore the broader implications of this approach.
Conclusion
The paper introduces the concept of "multimodal unlearnable examples" as a novel approach to protecting data against multimodal contrastive learning. By generating synthetic examples that are indistinguishable from the real data but contain no meaningful information, the researchers were able to effectively prevent the target model from learning sensitive information while still allowing it to extract useful patterns from the remaining data.
The experiments conducted in this paper demonstrate the effectiveness of the proposed framework and highlight its potential to improve the privacy and security of multimodal machine learning systems. As the use of such systems continues to grow, this work represents an important contribution to the ongoing efforts to address the challenges of data protection in the era of powerful AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multimodal Unlearnable Examples: Protecting Data against Multimodal Contrastive Learning
Xinwei Liu, Xiaojun Jia, Yuan Xun, Siyuan Liang, Xiaochun Cao
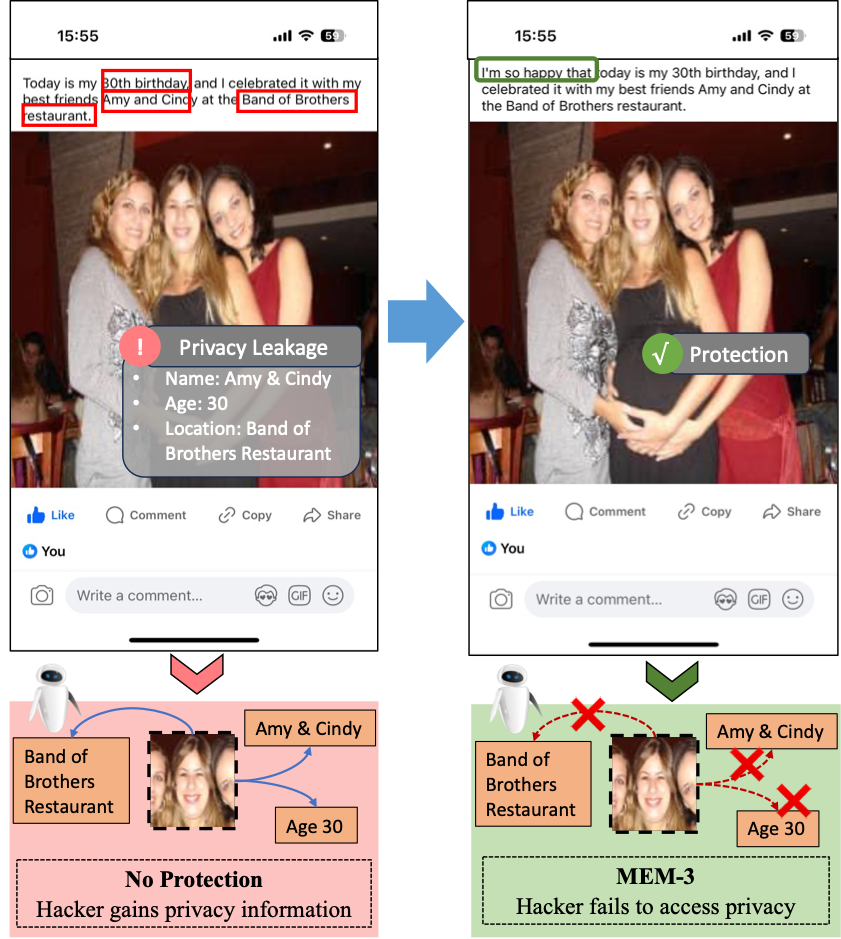
Multimodal contrastive learning (MCL) has shown remarkable advances in zero-shot classification by learning from millions of image-caption pairs crawled from the Internet. However, this reliance poses privacy risks, as hackers may unauthorizedly exploit image-text data for model training, potentially including personal and privacy-sensitive information. Recent works propose generating unlearnable examples by adding imperceptible perturbations to training images to build shortcuts for protection. However, they are designed for unimodal classification, which remains largely unexplored in MCL. We first explore this context by evaluating the performance of existing methods on image-caption pairs, and they do not generalize effectively to multimodal data and exhibit limited impact to build shortcuts due to the lack of labels and the dispersion of pairs in MCL. In this paper, we propose Multi-step Error Minimization (MEM), a novel optimization process for generating multimodal unlearnable examples. It extends the Error-Minimization (EM) framework to optimize both image noise and an additional text trigger, thereby enlarging the optimized space and effectively misleading the model to learn the shortcut between the noise features and the text trigger. Specifically, we adopt projected gradient descent to solve the noise minimization problem and use HotFlip to approximate the gradient and replace words to find the optimal text trigger. Extensive experiments demonstrate the effectiveness of MEM, with post-protection retrieval results nearly half of random guessing, and its high transferability across different models. Our code is available on the https://github.com/thinwayliu/Multimodal-Unlearnable-Examples
Read more7/29/2024
0
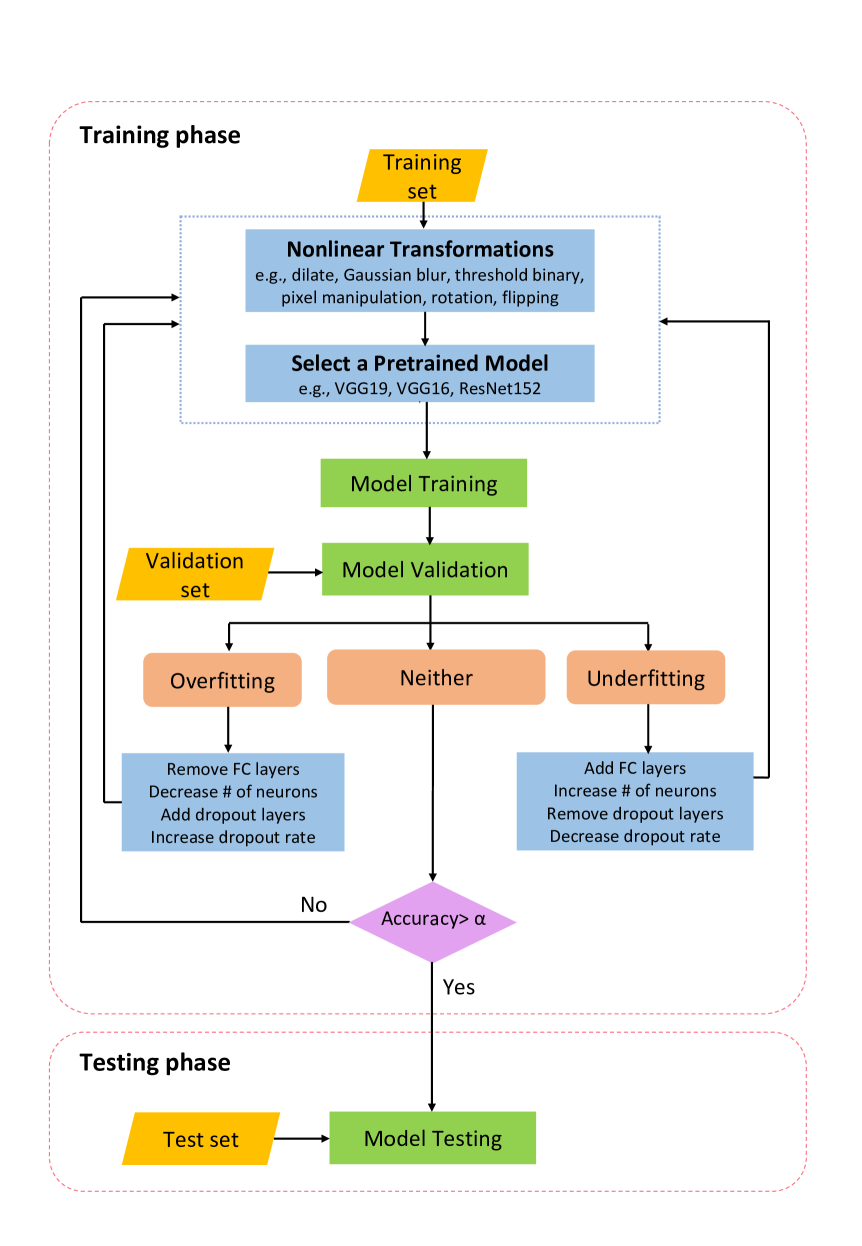
Nonlinear Transformations Against Unlearnable Datasets
Thushari Hapuarachchi, Jing Lin, Kaiqi Xiong, Mohamed Rahouti, Gitte Ost
Automated scraping stands out as a common method for collecting data in deep learning models without the authorization of data owners. Recent studies have begun to tackle the privacy concerns associated with this data collection method. Notable approaches include Deepconfuse, error-minimizing, error-maximizing (also known as adversarial poisoning), Neural Tangent Generalization Attack, synthetic, autoregressive, One-Pixel Shortcut, Self-Ensemble Protection, Entangled Features, Robust Error-Minimizing, Hypocritical, and TensorClog. The data generated by those approaches, called unlearnable examples, are prevented learning by deep learning models. In this research, we investigate and devise an effective nonlinear transformation framework and conduct extensive experiments to demonstrate that a deep neural network can effectively learn from the data/examples traditionally considered unlearnable produced by the above twelve approaches. The resulting approach improves the ability to break unlearnable data compared to the linear separable technique recently proposed by researchers. Specifically, our extensive experiments show that the improvement ranges from 0.34% to 249.59% for the unlearnable CIFAR10 datasets generated by those twelve data protection approaches, except for One-Pixel Shortcut. Moreover, the proposed framework achieves over 100% improvement of test accuracy for Autoregressive and REM approaches compared to the linear separable technique. Our findings suggest that these approaches are inadequate in preventing unauthorized uses of data in machine learning models. There is an urgent need to develop more robust protection mechanisms that effectively thwart an attacker from accessing data without proper authorization from the owners.
Read more6/6/2024

0
Learning the Unlearned: Mitigating Feature Suppression in Contrastive Learning
Jihai Zhang, Xiang Lan, Xiaoye Qu, Yu Cheng, Mengling Feng, Bryan Hooi
Self-Supervised Contrastive Learning has proven effective in deriving high-quality representations from unlabeled data. However, a major challenge that hinders both unimodal and multimodal contrastive learning is feature suppression, a phenomenon where the trained model captures only a limited portion of the information from the input data while overlooking other potentially valuable content. This issue often leads to indistinguishable representations for visually similar but semantically different inputs, adversely affecting downstream task performance, particularly those requiring rigorous semantic comprehension. To address this challenge, we propose a novel model-agnostic Multistage Contrastive Learning (MCL) framework. Unlike standard contrastive learning which inherently captures one single biased feature distribution, MCL progressively learns previously unlearned features through feature-aware negative sampling at each stage, where the negative samples of an anchor are exclusively selected from the cluster it was assigned to in preceding stages. Meanwhile, MCL preserves the previously well-learned features by cross-stage representation integration, integrating features across all stages to form final representations. Our comprehensive evaluation demonstrates MCL's effectiveness and superiority across both unimodal and multimodal contrastive learning, spanning a range of model architectures from ResNet to Vision Transformers (ViT). Remarkably, in tasks where the original CLIP model has shown limitations, MCL dramatically enhances performance, with improvements up to threefold on specific attributes in the recently proposed MMVP benchmark.
Read more7/16/2024
📊
0
Unlearnable Examples for Diffusion Models: Protect Data from Unauthorized Exploitation
Zhengyue Zhao, Jinhao Duan, Xing Hu, Kaidi Xu, Chenan Wang, Rui Zhang, Zidong Du, Qi Guo, Yunji Chen
Diffusion models have demonstrated remarkable performance in image generation tasks, paving the way for powerful AIGC applications. However, these widely-used generative models can also raise security and privacy concerns, such as copyright infringement, and sensitive data leakage. To tackle these issues, we propose a method, Unlearnable Diffusion Perturbation, to safeguard images from unauthorized exploitation. Our approach involves designing an algorithm to generate sample-wise perturbation noise for each image to be protected. This imperceptible protective noise makes the data almost unlearnable for diffusion models, i.e., diffusion models trained or fine-tuned on the protected data cannot generate high-quality and diverse images related to the protected training data. Theoretically, we frame this as a max-min optimization problem and introduce EUDP, a noise scheduler-based method to enhance the effectiveness of the protective noise. We evaluate our methods on both Denoising Diffusion Probabilistic Model and Latent Diffusion Models, demonstrating that training diffusion models on the protected data lead to a significant reduction in the quality of the generated images. Especially, the experimental results on Stable Diffusion demonstrate that our method effectively safeguards images from being used to train Diffusion Models in various tasks, such as training specific objects and styles. This achievement holds significant importance in real-world scenarios, as it contributes to the protection of privacy and copyright against AI-generated content.
Read more6/26/2024