Multitask and Multimodal Neural Tuning for Large Models

0

Sign in to get full access
Overview
- The paper explores multitask and multimodal neural tuning techniques for improving the performance of large models.
- The authors investigate ways to fine-tune pre-trained models on multiple tasks and modalities to enhance their capabilities.
- Key ideas include using task-specific adapters, cross-modal attention, and multi-task learning to achieve better performance.
Plain English Explanation
The paper looks at how to make large artificial intelligence (AI) models even better by training them on multiple tasks and different types of data at the same time. These models are often trained on a single task, like text prediction or image recognition, but the researchers wanted to see if tuning them on a variety of tasks and data types could improve their overall performance.
Some of the key techniques they explored include using task-specific adapters - specialized components added to the model to handle different tasks. They also looked at using cross-modal attention, which lets the model focus on relevant information across text, images, and other data types. And they experimented with multi-task learning, training the model on multiple tasks simultaneously to build more versatile capabilities.
The goal was to find ways to take these powerful, but often narrowly-trained, large language and vision models and make them more adaptable and effective across a wider range of applications. By combining different tuning techniques, the researchers hoped to unlock new performance gains for these models.
Technical Explanation
The paper explores multitask and multimodal neural tuning as a method for improving the performance of large pre-trained models. The authors investigate ways to fine-tune these models on multiple tasks and data modalities to enhance their capabilities.
Key techniques explored in the paper include:
-
Task-Specific Adapters: The researchers add specialized adapter modules to the base model, allowing it to handle different tasks while preserving the core model parameters. This lets the model learn task-specific skills without forgetting its general capabilities.
-
Cross-Modal Attention: The authors incorporate cross-attention mechanisms that enable the model to focus on relevant information across text, images, and other modalities. This helps the model better integrate and leverage multimodal signals.
-
Multi-Task Learning: The researchers train the model on multiple tasks simultaneously, using a shared backbone but task-specific heads. This encourages the model to learn more versatile and generalizable representations.
Through a series of experiments, the paper demonstrates performance improvements on a variety of benchmarks by applying these multitask and multimodal tuning techniques to large language and vision models. The findings suggest that these methods can be an effective way to enhance the capabilities of powerful but narrowly-trained AI systems.
Critical Analysis
The paper provides a thorough investigation of multitask and multimodal tuning approaches for improving the performance of large pre-trained models. The techniques explored, such as task-specific adapters and cross-modal attention, are well-motivated and grounded in relevant literature.
That said, the paper does not address some potential limitations or areas for further research. For example, it does not explore the computational and memory overhead associated with these tuning methods, which could be a concern for deployment in resource-constrained environments. Additionally, the paper does not delve into the interpretability or explainability of the models produced by these techniques, which is an important consideration for many real-world applications.
Further research could also investigate the transfer learning capabilities of these multitask and multimodal models, examining how well they perform on novel tasks or data distributions compared to single-task or unimodal models. Exploring the robustness and reliability of these tuned models under distribution shift or adversarial attacks would also be valuable.
Overall, the paper presents a compelling approach to enhancing the capabilities of large AI models, but there are still open questions and areas for further exploration to fully understand the strengths and limitations of these techniques.
Conclusion
The paper introduces multitask and multimodal neural tuning as a promising approach for improving the performance of large pre-trained models. By fine-tuning these models on multiple tasks and data modalities, the researchers demonstrate gains in a variety of benchmarks, suggesting that these techniques can help unlock the full potential of powerful AI systems.
The key ideas, including task-specific adapters, cross-modal attention, and multi-task learning, offer a compelling direction for advancing the state-of-the-art in AI model development. As the field continues to produce increasingly capable but often narrowly-specialized models, techniques like those explored in this paper could be instrumental in creating more versatile and adaptable AI assistants and tools to tackle real-world challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multitask and Multimodal Neural Tuning for Large Models
Hao Sun, Yu Song, Jihong Hu, Yen-Wei Chen, Lanfen Lin
In recent years, large-scale multimodal models have demonstrated impressive capabilities across various domains. However, enabling these models to effectively perform multiple multimodal tasks simultaneously remains a significant challenge. To address this, we introduce a novel tuning method called neural tuning, designed to handle diverse multimodal tasks concurrently, including reasoning segmentation, referring segmentation, image captioning, and text-to-image generation. Neural tuning emulates sparse distributed representation in human brain, where only specific subsets of neurons are activated for each task. Additionally, we present a new benchmark, MMUD, where each sample is annotated with multiple task labels. By applying neural tuning to pretrained large models on the MMUD benchmark, we achieve simultaneous task handling in a streamlined and efficient manner. All models, code, and datasets will be publicly available after publication, facilitating further research and development in this field.
Read more8/7/2024
0
Multimodal Infusion Tuning for Large Models
Hao Sun, Yu Song, Xinyao Yu, Jiaqing Liu, Yen-Wei Chen, Lanfen Lin
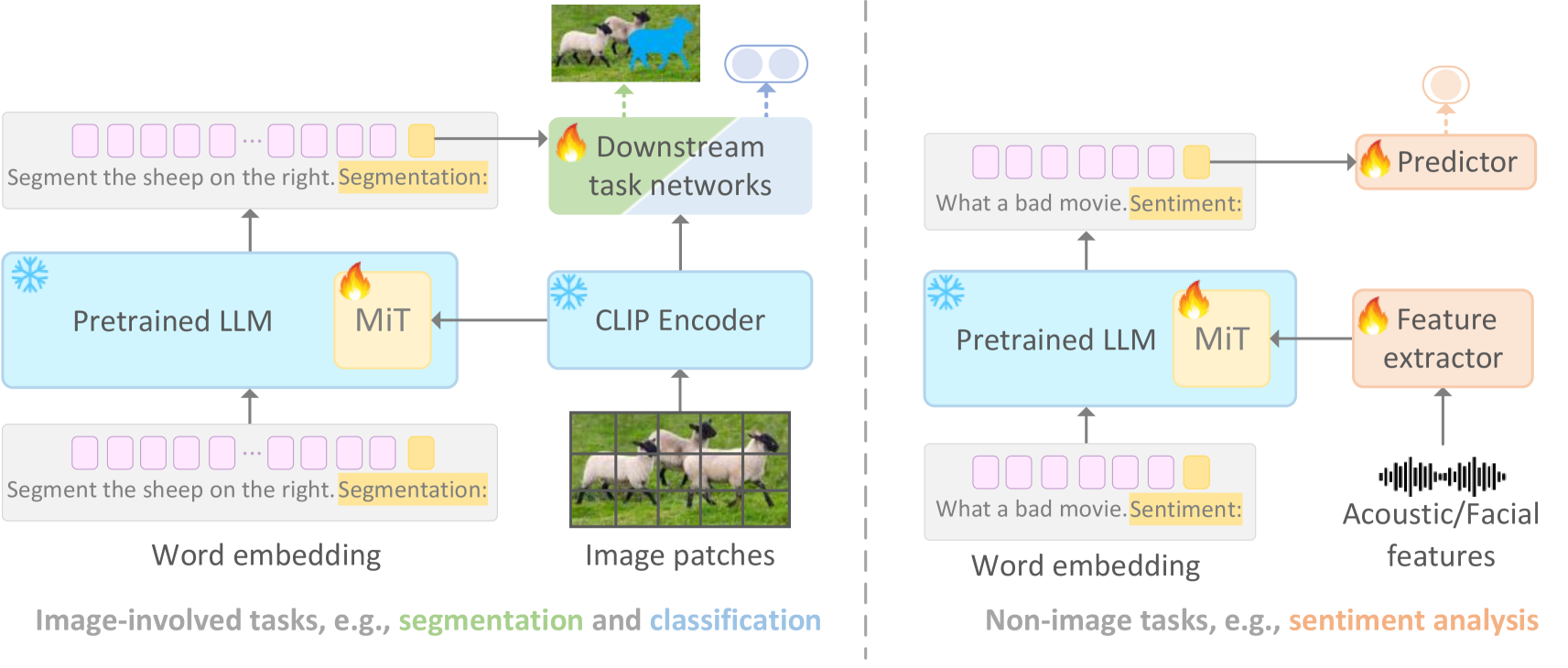
Recent advancements in large-scale models have showcased remarkable generalization capabilities in various tasks. However, integrating multimodal processing into these models presents a significant challenge, as it often comes with a high computational burden. To address this challenge, we introduce a new parameter-efficient multimodal tuning strategy for large models in this paper, referred to as Multimodal Infusion Tuning (MiT). MiT leverages decoupled self-attention mechanisms within large language models to effectively integrate information from diverse modalities such as images and acoustics. In MiT, we also design a novel adaptive rescaling strategy at the attention head level, which optimizes the representation of infused multimodal features. Notably, all foundation models are kept frozen during the tuning process to reduce the computational burden and only 2.5% parameters are tunable. We conduct experiments across a range of multimodal tasks, including image-related tasks like referring segmentation and non-image tasks such as sentiment analysis. Our results showcase that MiT achieves state-of-the-art performance in multimodal understanding while significantly reducing computational overhead(10% of previous methods). Moreover, our tuned model exhibits robust reasoning abilities even in complex scenarios.
Read more7/17/2024

0
Robust Latent Representation Tuning for Image-text Classification
Hao Sun, Yu Song
Large models have demonstrated exceptional generalization capabilities in computer vision and natural language processing. Recent efforts have focused on enhancing these models with multimodal processing abilities. However, addressing the challenges posed by scenarios where one modality is absent remains a significant hurdle. In response to this issue, we propose a robust latent representation tuning method for large models. Specifically, our approach introduces a modality latent translation module to maximize the correlation between modalities, resulting in a robust representation. Following this, a newly designed fusion module is employed to facilitate information interaction between the modalities. Within this framework, common semantics are refined during training, and robust performance is achieved even in the absence of one modality. Importantly, our method maintains the frozen state of the image and text foundation models to preserve their capabilities acquired through large-scale pretraining. We conduct experiments on several public datasets, and the results underscore the effectiveness of our proposed method.
Read more6/17/2024
🐍
0
Finding and Editing Multi-Modal Neurons in Pre-Trained Transformers
Haowen Pan, Yixin Cao, Xiaozhi Wang, Xun Yang, Meng Wang
Understanding the internal mechanisms by which multi-modal large language models (LLMs) interpret different modalities and integrate cross-modal representations is becoming increasingly critical for continuous improvements in both academia and industry. In this paper, we propose a novel method to identify key neurons for interpretability -- how multi-modal LLMs bridge visual and textual concepts for captioning. Our method improves conventional works upon efficiency and applied range by removing needs of costly gradient computation. Based on those identified neurons, we further design a multi-modal knowledge editing method, beneficial to mitigate sensitive words or hallucination. For rationale of our design, we provide theoretical assumption. For empirical evaluation, we have conducted extensive quantitative and qualitative experiments. The results not only validate the effectiveness of our methods, but also offer insightful findings that highlight three key properties of multi-modal neurons: sensitivity, specificity and causal-effect, to shed light for future research.
Read more6/12/2024