Multimodal Infusion Tuning for Large Models
2403.05060
0
0
Abstract
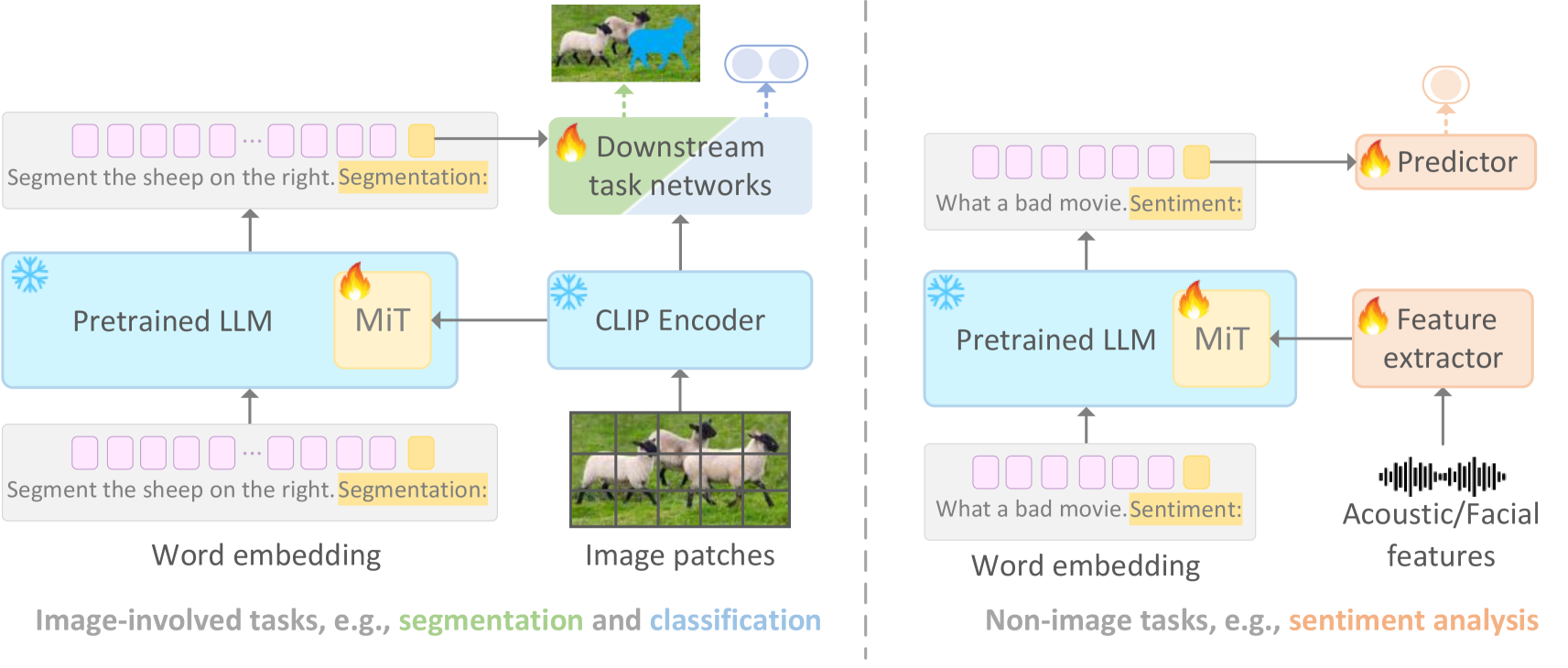
Recent advancements in large-scale models have showcased remarkable generalization capabilities in various tasks. However, integrating multimodal processing into these models presents a significant challenge, as it often comes with a high computational burden. To address this challenge, we introduce a new parameter-efficient multimodal tuning strategy for large models in this paper, referred to as Multimodal Infusion Tuning (MiT). MiT leverages decoupled self-attention mechanisms within large language models to effectively integrate information from diverse modalities such as images and acoustics. In MiT, we also design a novel adaptive rescaling strategy at the attention head level, which optimizes the representation of infused multimodal features. Notably, all foundation models are kept frozen during the tuning process to reduce the computational burden and only 2.5% parameters are tunable. We conduct experiments across a range of multimodal tasks, including image-related tasks like referring segmentation and non-image tasks such as sentiment analysis. Our results showcase that MiT achieves state-of-the-art performance in multimodal understanding while significantly reducing computational overhead(10% of previous methods). Moreover, our tuned model exhibits robust reasoning abilities even in complex scenarios.
Create account to get full access
Overview
- This paper explores "Multimodal Infusion Tuning", a technique for fine-tuning large language models on multimodal data.
- The authors demonstrate how this approach can improve the performance of these models on a variety of tasks, including image-text classification and cross-modal fine-tuning.
- The paper builds upon previous work on multimodal large language and vision models and instruction tuning for multimodal tasks.
Plain English Explanation
The paper focuses on a technique called "Multimodal Infusion Tuning" which is used to fine-tune large language models on data that combines text, images, and other modalities. These large models, like GPT-3 or BERT, are powerful but can be further improved for specific tasks by training them on relevant multimodal data.
The key idea is to gradually "infuse" the model with multimodal information during the fine-tuning process, rather than just training on text or images alone. This allows the model to learn how to effectively leverage the connections between different modalities, such as how visual information can inform the meaning of text.
The authors show that this approach can lead to better performance on a range of tasks that involve understanding and reasoning about multimodal data, like classifying images based on accompanying text or transferring knowledge between text and images. This builds on previous work in multimodal models and instruction tuning.
Technical Explanation
The paper proposes a "Multimodal Infusion Tuning" approach for fine-tuning large language models on multimodal data. This involves gradually incorporating different modalities (e.g., images, text, etc.) into the fine-tuning process, rather than just training on one modality at a time.
The authors experiment with several variants of this technique, including:
- Progressive Infusion: Gradually increasing the amount of multimodal data used during fine-tuning.
- Adaptive Infusion: Dynamically adjusting the weighting of different modalities based on the model's performance.
- Parallel Infusion: Simultaneously fine-tuning the model on text and image data.
They evaluate these approaches on a range of multimodal tasks, including image-text classification and cross-modal fine-tuning. The results demonstrate that Multimodal Infusion Tuning can outperform traditional fine-tuning methods, especially on tasks that require a deep understanding of the relationships between different modalities.
Critical Analysis
The paper presents a compelling approach for improving the performance of large language models on multimodal tasks. However, the authors acknowledge several limitations and areas for future research:
- The impact of Multimodal Infusion Tuning may depend on the specific architecture and pre-training of the base language model, and the technique may not be equally effective across all models.
- The paper focuses on a relatively limited set of tasks and datasets, and further evaluation on a wider range of multimodal benchmarks would be valuable.
- The underlying mechanisms and optimal hyperparameters for the different infusion variants are not fully explored, leaving room for further refinement and optimization of the approach.
Additionally, one could question whether the benefits of Multimodal Infusion Tuning outweigh the increased computational and data requirements compared to traditional fine-tuning methods. The trade-offs between performance gains and resource costs should be carefully considered in practical applications.
Conclusion
This paper introduces a novel "Multimodal Infusion Tuning" approach for fine-tuning large language models on multimodal data. The results demonstrate that this technique can significantly improve model performance on a variety of tasks that involve understanding and reasoning about the relationships between different modalities, such as image-text classification and cross-modal fine-tuning.
The work builds upon previous research on multimodal large language and vision models and instruction tuning, showcasing the potential for leveraging diverse data sources to enhance the capabilities of these powerful language models. While the paper identifies some areas for further refinement, the Multimodal Infusion Tuning approach represents an important step forward in developing more robust and versatile multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Robust Latent Representation Tuning for Image-text Classification
Hao Sun, Yu Song
0
0
Large models have demonstrated exceptional generalization capabilities in computer vision and natural language processing. Recent efforts have focused on enhancing these models with multimodal processing abilities. However, addressing the challenges posed by scenarios where one modality is absent remains a significant hurdle. In response to this issue, we propose a robust latent representation tuning method for large models. Specifically, our approach introduces a modality latent translation module to maximize the correlation between modalities, resulting in a robust representation. Following this, a newly designed fusion module is employed to facilitate information interaction between the modalities. Within this framework, common semantics are refined during training, and robust performance is achieved even in the absence of one modality. Importantly, our method maintains the frozen state of the image and text foundation models to preserve their capabilities acquired through large-scale pretraining. We conduct experiments on several public datasets, and the results underscore the effectiveness of our proposed method.
6/17/2024
Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Lincan Cai, Shuang Li, Wenxuan Ma, Jingxuan Kang, Binhui Xie, Zixun Sun, Chengwei Zhu
0
0
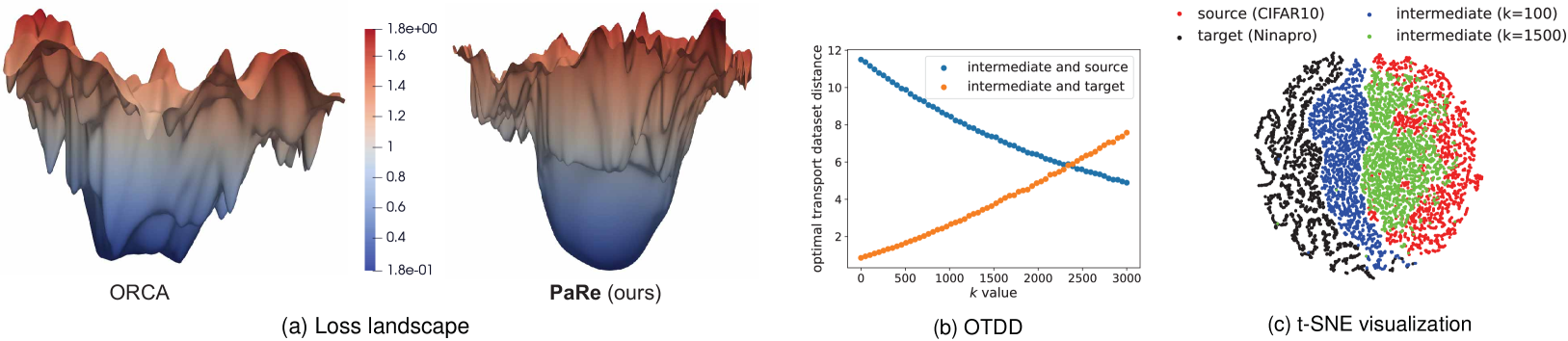
Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
6/14/2024

Minimal Interaction Edge Tuning: A New Paradigm for Visual Adaptation
Ningyuan Tang, Minghao Fu, Jianxin Wu
0
0
The rapid scaling of large vision pretrained models makes fine-tuning tasks more and more difficult on edge devices with low computational resources. We explore a new visual adaptation paradigm called edge tuning, which treats large pretrained models as standalone feature extractors that run on powerful cloud servers. The fine-tuning carries out on edge devices with small networks which require low computational resources. Existing methods that are potentially suitable for our edge tuning paradigm are discussed. But, three major drawbacks hinder their application in edge tuning: low adaptation capability, large adapter network, and high information transfer overhead. To address these issues, we propose Minimal Interaction Edge Tuning, or MIET, which reveals that the sum of intermediate features from pretrained models not only has minimal information transfer but also has high adaptation capability. With a lightweight attention-based adaptor network, MIET achieves information transfer efficiency, parameter efficiency, computational and memory efficiency, and at the same time demonstrates competitive results on various visual adaptation benchmarks.
6/27/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024