MuRAR: A Simple and Effective Multimodal Retrieval and Answer Refinement Framework for Multimodal Question Answering

0
Sign in to get full access
Overview
- Presents a simple and effective multimodal retrieval and answer refinement framework called MuRAR for multimodal question answering
- Combines language and vision models to retrieve relevant information and refine the final answer
- Achieves state-of-the-art results on challenging multimodal question answering benchmarks
Plain English Explanation
The paper introduces MuRAR, a new approach for answering questions that involve both text and images. The key idea is to combine language and vision models to first retrieve relevant information, and then refine the final answer.
The framework works as follows:
-
Retrieve Relevant Information: When a user asks a question, the system uses both the text of the question and any related images to find the most relevant information from a large database of documents and images.
-
Refine the Answer: Once the relevant information has been retrieved, the system analyzes this information in more detail to come up with the best answer to the original question.
By using both text and visual information, MuRAR is able to outperform other state-of-the-art models on challenging multimodal question answering benchmarks. This suggests that integrating language and vision is crucial for answering real-world questions that involve both text and images.
Technical Explanation
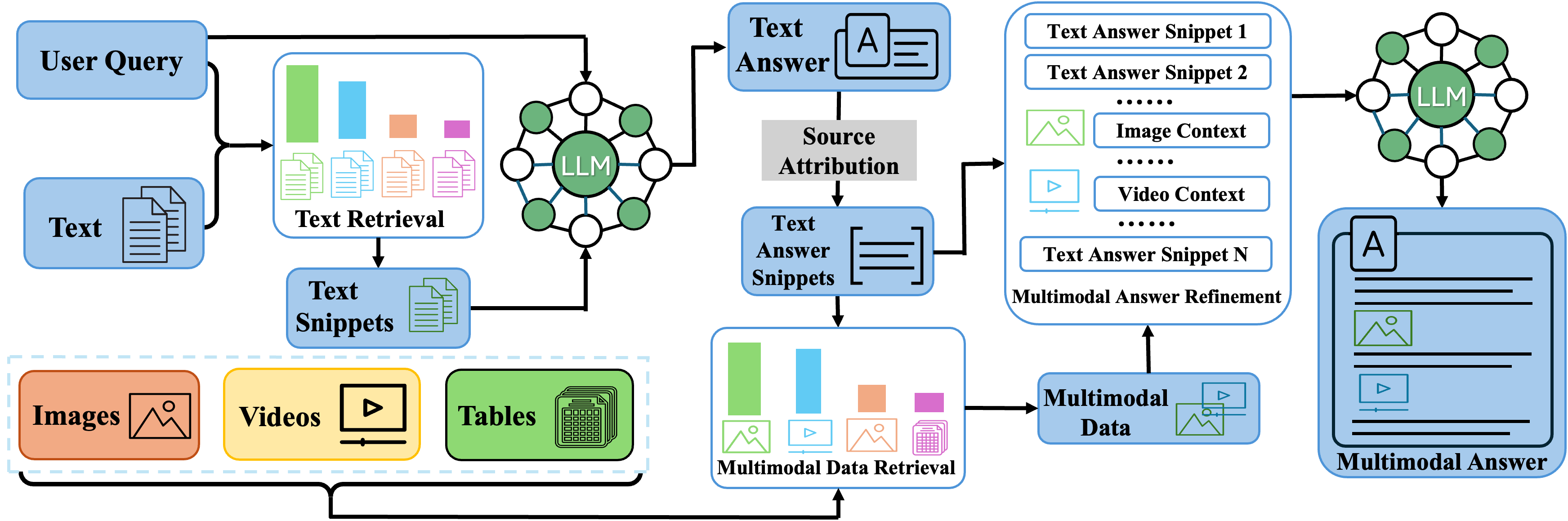
The paper presents the design and evaluation of MuRAR, a multimodal retrieval and answer refinement framework for question answering. The key components are:
-
Multimodal Retrieval: MuRAR uses a dual-encoder architecture to encode both the question text and any related images. It then retrieves the most relevant passages and images from a large database using cross-modal similarity.
-
Answer Refinement: The retrieved information is then processed by a question-answering model that generates an answer by attending to the relevant passages and images.
-
Evaluation: The authors evaluate MuRAR on two challenging multimodal question answering datasets, VQAv2 and OK-VQA, and show that it outperforms other state-of-the-art models.
The core insight is that integrating language and vision is crucial for multimodal question answering. By leveraging both textual and visual information, MuRAR is able to better understand and answer real-world questions that require reasoning about both modalities.
Critical Analysis
The paper provides a simple yet effective approach for multimodal question answering, and the experimental results demonstrate the benefits of the proposed framework. However, there are a few potential limitations and areas for further research:
-
Scalability: The authors mention that MuRAR's retrieval component relies on an exhaustive search over a large database, which may not be scalable to very large corpora. Exploring more efficient retrieval methods could be an interesting direction.
-
Robustness: The paper focuses on evaluating MuRAR on two specific multimodal datasets. It would be valuable to assess its generalization and robustness on a wider range of multimodal tasks and datasets.
-
Interpretability: The authors do not provide much insight into how the framework makes its decisions or what types of reasoning it is performing. Improving the interpretability of the model could make it more useful for real-world applications.
Overall, the MuRAR framework represents an important step forward in multimodal question answering, and the ideas presented in the paper could inspire further research in this area.
Conclusion
This paper introduces MuRAR, a simple yet effective multimodal retrieval and answer refinement framework for question answering. By integrating language and vision models, MuRAR is able to outperform other state-of-the-art approaches on challenging multimodal benchmarks.
The key ideas behind MuRAR, such as cross-modal retrieval and answer refinement, could have broader implications for other multimodal tasks beyond question answering. As AI systems become more capable of understanding and reasoning about the world using both text and images, frameworks like MuRAR will likely play an important role in building more intelligent and versatile question-answering systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MuRAR: A Simple and Effective Multimodal Retrieval and Answer Refinement Framework for Multimodal Question Answering
Zhengyuan Zhu, Daniel Lee, Hong Zhang, Sai Sree Harsha, Loic Feujio, Akash Maharaj, Yunyao Li
Recent advancements in retrieval-augmented generation (RAG) have demonstrated impressive performance in the question-answering (QA) task. However, most previous works predominantly focus on text-based answers. While some studies address multimodal data, they still fall short in generating comprehensive multimodal answers, particularly for explaining concepts or providing step-by-step tutorials on how to accomplish specific goals. This capability is especially valuable for applications such as enterprise chatbots and settings such as customer service and educational systems, where the answers are sourced from multimodal data. In this paper, we introduce a simple and effective framework named MuRAR (Multimodal Retrieval and Answer Refinement). MuRAR enhances text-based answers by retrieving relevant multimodal data and refining the responses to create coherent multimodal answers. This framework can be easily extended to support multimodal answers in enterprise chatbots with minimal modifications. Human evaluation results indicate that multimodal answers generated by MuRAR are more useful and readable compared to plain text answers.
Read more8/19/2024

0
An Interactive Multi-modal Query Answering System with Retrieval-Augmented Large Language Models
Mengzhao Wang, Haotian Wu, Xiangyu Ke, Yunjun Gao, Xiaoliang Xu, Lu Chen
Retrieval-augmented Large Language Models (LLMs) have reshaped traditional query-answering systems, offering unparalleled user experiences. However, existing retrieval techniques often struggle to handle multi-modal query contexts. In this paper, we present an interactive Multi-modal Query Answering (MQA) system, empowered by our newly developed multi-modal retrieval framework and navigation graph index, integrated with cutting-edge LLMs. It comprises five core components: Data Preprocessing, Vector Representation, Index Construction, Query Execution, and Answer Generation, all orchestrated by a dedicated coordinator to ensure smooth data flow from input to answer generation. One notable aspect of MQA is its utilization of contrastive learning to assess the significance of different modalities, facilitating precise measurement of multi-modal information similarity. Furthermore, the system achieves efficient retrieval through our advanced navigation graph index, refined using computational pruning techniques. Another highlight of our system is its pluggable processing framework, allowing seamless integration of embedding models, graph indexes, and LLMs. This flexibility provides users diverse options for gaining insights from their multi-modal knowledge base. A preliminary video introduction of MQA is available at https://youtu.be/xvUuo2ZIqWk.
Read more7/8/2024

0
Retrieval Meets Reasoning: Even High-school Textbook Knowledge Benefits Multimodal Reasoning
Cheng Tan, Jingxuan Wei, Linzhuang Sun, Zhangyang Gao, Siyuan Li, Bihui Yu, Ruifeng Guo, Stan Z. Li
Large language models equipped with retrieval-augmented generation (RAG) represent a burgeoning field aimed at enhancing answering capabilities by leveraging external knowledge bases. Although the application of RAG with language-only models has been extensively explored, its adaptation into multimodal vision-language models remains nascent. Going beyond mere answer generation, the primary goal of multimodal RAG is to cultivate the models' ability to reason in response to relevant queries. To this end, we introduce a novel multimodal RAG framework named RMR (Retrieval Meets Reasoning). The RMR framework employs a bi-modal retrieval module to identify the most relevant question-answer pairs, which then serve as scaffolds for the multimodal reasoning process. This training-free approach not only encourages the model to engage deeply with the reasoning processes inherent in the retrieved content but also facilitates the generation of answers that are precise and richly interpretable. Surprisingly, utilizing solely the ScienceQA dataset, collected from elementary and high school science curricula, RMR significantly boosts the performance of various vision-language models across a spectrum of benchmark datasets, including A-OKVQA, MMBench, and SEED. These outcomes highlight the substantial potential of our multimodal retrieval and reasoning mechanism to improve the reasoning capabilities of vision-language models.
Read more6/3/2024
🧪
0
MemeMQA: Multimodal Question Answering for Memes via Rationale-Based Inferencing
Siddhant Agarwal, Shivam Sharma, Preslav Nakov, Tanmoy Chakraborty
Memes have evolved as a prevalent medium for diverse communication, ranging from humour to propaganda. With the rising popularity of image-focused content, there is a growing need to explore its potential harm from different aspects. Previous studies have analyzed memes in closed settings - detecting harm, applying semantic labels, and offering natural language explanations. To extend this research, we introduce MemeMQA, a multimodal question-answering framework aiming to solicit accurate responses to structured questions while providing coherent explanations. We curate MemeMQACorpus, a new dataset featuring 1,880 questions related to 1,122 memes with corresponding answer-explanation pairs. We further propose ARSENAL, a novel two-stage multimodal framework that leverages the reasoning capabilities of LLMs to address MemeMQA. We benchmark MemeMQA using competitive baselines and demonstrate its superiority - ~18% enhanced answer prediction accuracy and distinct text generation lead across various metrics measuring lexical and semantic alignment over the best baseline. We analyze ARSENAL's robustness through diversification of question-set, confounder-based evaluation regarding MemeMQA's generalizability, and modality-specific assessment, enhancing our understanding of meme interpretation in the multimodal communication landscape.
Read more5/21/2024