An Interactive Multi-modal Query Answering System with Retrieval-Augmented Large Language Models

0

Sign in to get full access
Overview
- This paper presents an interactive multi-modal query answering system that combines retrieval-augmented large language models.
- The system allows users to ask questions and receive answers that integrate information from both text and visual data.
- The key components include a retrieval module, a multi-modal fusion module, and a generation module.
Plain English Explanation
The researchers have developed an interactive system that can answer questions by combining information from text and images. This is a type of multi-modal question answering system.
Users can ask the system questions, and it will provide answers that draw upon relevant information from both text and visual sources. The system uses a retrieval module to find the most relevant information, a fusion module to combine the text and images, and a generation module to produce the final answer.
This allows the system to give more comprehensive and informative responses than if it only used text or images alone. For example, if a user asks about a specific object in an image, the system can retrieve relevant information from the text to provide a detailed answer.
Technical Explanation
The key components of the system are:
-
Retrieval Module: This module uses dense retrieval techniques to find the most relevant text and visual information from a knowledge base to answer the user's query.
-
Multi-modal Fusion Module: This module takes the retrieved text and visual information and combines them using multi-modal fusion techniques to produce a unified representation.
-
Generation Module: This module uses a large language model to generate the final answer to the user's query, drawing on the fused text and visual information.
The researchers evaluate the system's performance on several multi-modal question answering benchmarks. The results show that the retrieval-augmented approach outperforms standalone language models, demonstrating the value of integrating text and visual data.
Critical Analysis
The paper provides a solid technical foundation for the multi-modal query answering system, but there are a few potential limitations and areas for further research:
-
Knowledge Limitations: The system's performance is still dependent on the quality and coverage of the underlying knowledge base. Expanding the knowledge base and improving retrieval techniques could further enhance the system's capabilities.
-
Generalization Challenges: The paper primarily evaluates the system on specific benchmarks. More research is needed to understand how well the approach generalizes to real-world, open-ended multi-modal queries.
-
Explainability and Transparency: As with many large language model-based systems, the inner workings of the generation module may be difficult to interpret. Improving the explainability and transparency of the system's decision-making process could be an area for future work.
Conclusion
The interactive multi-modal query answering system presented in this paper combines retrieval-augmented large language models to provide users with answers that integrate information from both text and visual data.
The key technical innovations include a retrieval module, a multi-modal fusion module, and a generation module. The results show that this approach can outperform standalone language models, highlighting the value of integrating multiple modalities for more comprehensive and informative responses.
While the system has some limitations, this research represents an important step forward in the field of multi-modal question answering, with potential applications in education, information retrieval, and interactive assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Interactive Multi-modal Query Answering System with Retrieval-Augmented Large Language Models
Mengzhao Wang, Haotian Wu, Xiangyu Ke, Yunjun Gao, Xiaoliang Xu, Lu Chen
Retrieval-augmented Large Language Models (LLMs) have reshaped traditional query-answering systems, offering unparalleled user experiences. However, existing retrieval techniques often struggle to handle multi-modal query contexts. In this paper, we present an interactive Multi-modal Query Answering (MQA) system, empowered by our newly developed multi-modal retrieval framework and navigation graph index, integrated with cutting-edge LLMs. It comprises five core components: Data Preprocessing, Vector Representation, Index Construction, Query Execution, and Answer Generation, all orchestrated by a dedicated coordinator to ensure smooth data flow from input to answer generation. One notable aspect of MQA is its utilization of contrastive learning to assess the significance of different modalities, facilitating precise measurement of multi-modal information similarity. Furthermore, the system achieves efficient retrieval through our advanced navigation graph index, refined using computational pruning techniques. Another highlight of our system is its pluggable processing framework, allowing seamless integration of embedding models, graph indexes, and LLMs. This flexibility provides users diverse options for gaining insights from their multi-modal knowledge base. A preliminary video introduction of MQA is available at https://youtu.be/xvUuo2ZIqWk.
Read more7/8/2024
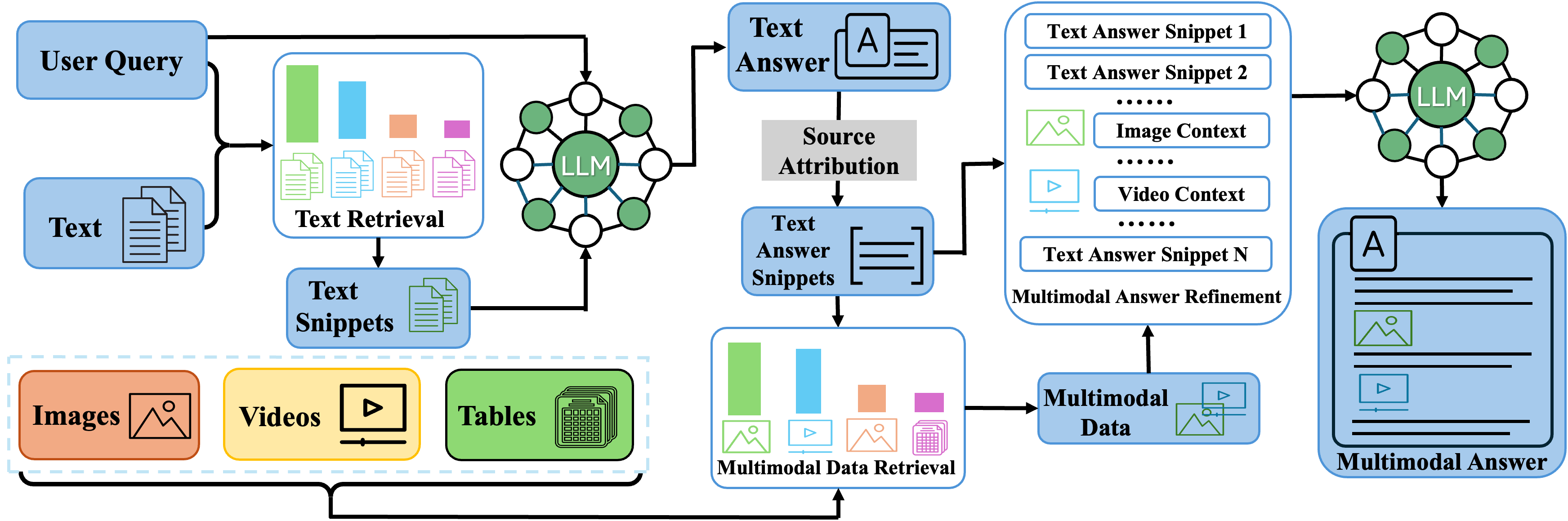
0
MuRAR: A Simple and Effective Multimodal Retrieval and Answer Refinement Framework for Multimodal Question Answering
Zhengyuan Zhu, Daniel Lee, Hong Zhang, Sai Sree Harsha, Loic Feujio, Akash Maharaj, Yunyao Li
Recent advancements in retrieval-augmented generation (RAG) have demonstrated impressive performance in the question-answering (QA) task. However, most previous works predominantly focus on text-based answers. While some studies address multimodal data, they still fall short in generating comprehensive multimodal answers, particularly for explaining concepts or providing step-by-step tutorials on how to accomplish specific goals. This capability is especially valuable for applications such as enterprise chatbots and settings such as customer service and educational systems, where the answers are sourced from multimodal data. In this paper, we introduce a simple and effective framework named MuRAR (Multimodal Retrieval and Answer Refinement). MuRAR enhances text-based answers by retrieving relevant multimodal data and refining the responses to create coherent multimodal answers. This framework can be easily extended to support multimodal answers in enterprise chatbots with minimal modifications. Human evaluation results indicate that multimodal answers generated by MuRAR are more useful and readable compared to plain text answers.
Read more8/19/2024
0
Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs
Davide Caffagni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, Rita Cucchiara
Multimodal LLMs are the natural evolution of LLMs, and enlarge their capabilities so as to work beyond the pure textual modality. As research is being carried out to design novel architectures and vision-and-language adapters, in this paper we concentrate on endowing such models with the capability of answering questions that require external knowledge. Our approach, termed Wiki-LLaVA, aims at integrating an external knowledge source of multimodal documents, which is accessed through a hierarchical retrieval pipeline. Relevant passages, using this approach, are retrieved from the external knowledge source and employed as additional context for the LLM, augmenting the effectiveness and precision of generated dialogues. We conduct extensive experiments on datasets tailored for visual question answering with external data and demonstrate the appropriateness of our approach.
Read more5/24/2024
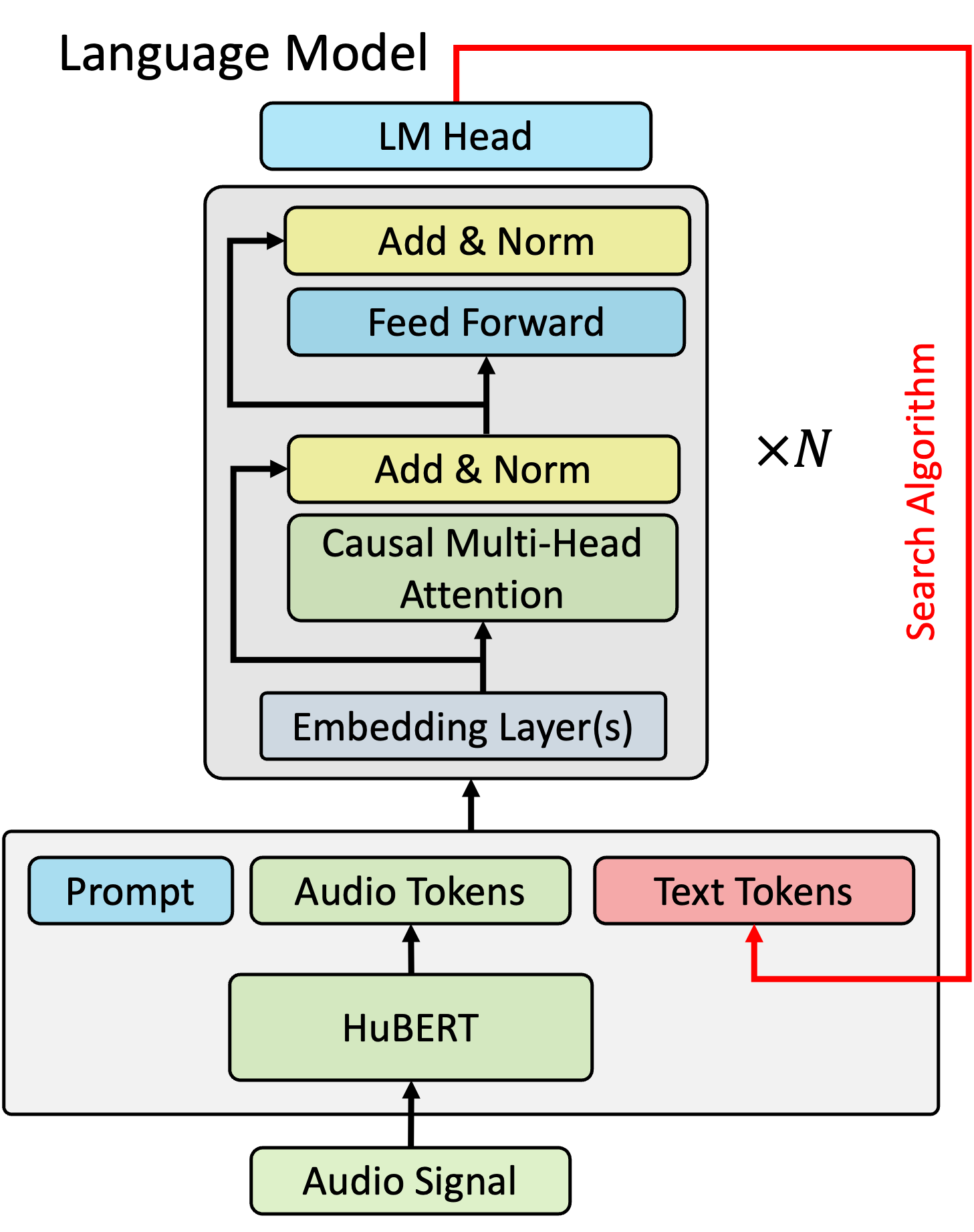
0
Multi-Modal Retrieval For Large Language Model Based Speech Recognition
Jari Kolehmainen, Aditya Gourav, Prashanth Gurunath Shivakumar, Yile Gu, Ankur Gandhe, Ariya Rastrow, Grant Strimel, Ivan Bulyko
Retrieval is a widely adopted approach for improving language models leveraging external information. As the field moves towards multi-modal large language models, it is important to extend the pure text based methods to incorporate other modalities in retrieval as well for applications across the wide spectrum of machine learning tasks and data types. In this work, we propose multi-modal retrieval with two approaches: kNN-LM and cross-attention techniques. We demonstrate the effectiveness of our retrieval approaches empirically by applying them to automatic speech recognition tasks with access to external information. Under this setting, we show that speech-based multi-modal retrieval outperforms text based retrieval, and yields up to 50 % improvement in word error rate over the multi-modal language model baseline. Furthermore, we achieve state-of-the-art recognition results on the Spoken-Squad question answering dataset.
Read more6/17/2024