Music Style Transfer With Diffusion Model
2404.14771
0
0
🔄
Abstract
Previous studies on music style transfer have mainly focused on one-to-one style conversion, which is relatively limited. When considering the conversion between multiple styles, previous methods required designing multiple modes to disentangle the complex style of the music, resulting in large computational costs and slow audio generation. The existing music style transfer methods generate spectrograms with artifacts, leading to significant noise in the generated audio. To address these issues, this study proposes a music style transfer framework based on diffusion models (DM) and uses spectrogram-based methods to achieve multi-to-multi music style transfer. The GuideDiff method is used to restore spectrograms to high-fidelity audio, accelerating audio generation speed and reducing noise in the generated audio. Experimental results show that our model has good performance in multi-mode music style transfer compared to the baseline and can generate high-quality audio in real-time on consumer-grade GPUs.
Create account to get full access
Overview
- Previous music style transfer methods focused on one-to-one style conversion, which is limited.
- Transferring between multiple styles requires complex models, resulting in high computational costs and slow audio generation.
- Existing methods generate spectrograms with artifacts, leading to noisy audio.
Plain English Explanation
The previous research on transferring the style of music from one type to another has mainly looked at converting between just two different styles. This is quite limiting, as music can have many complex and nuanced styles. When trying to transfer between multiple styles, the existing methods required designing very complicated models to separate out the different style elements. This made the process computationally expensive and slow to generate the new audio.
Additionally, the spectrograms (visual representations of the audio) produced by these existing methods had artifacts, or distortions, which then led to the final generated audio having a lot of unwanted noise and poor quality.
To address these issues, this new study proposes a music style transfer framework based on diffusion models. This allows for transferring between multiple music styles, while also using a technique called GuideDiff to restore the spectrograms to high quality, resulting in cleaner and faster generated audio.
Technical Explanation
This study introduces a music style transfer framework using diffusion models to enable multi-to-multi style conversion. Diffusion models are a type of generative model that can learn to transform noisy input data into high-quality output.
The proposed method uses spectrogram-based techniques to capture the complex musical styles. It then leverages the GuideDiff approach to efficiently convert the generated spectrograms back into high-fidelity audio. This improves the audio quality and generation speed compared to previous methods.
The experimental results demonstrate that this model can perform multi-style music transfer effectively, outperforming baseline approaches. Importantly, it is able to generate high-quality audio in real-time on consumer-grade GPUs, making it practical for real-world applications.
Critical Analysis
The paper acknowledges that while the proposed framework enables more flexible and efficient multi-style music transfer, there is still room for improvement. The authors mention the need to further enhance the model's ability to preserve the content and expressive details of the original music during the style transfer process.
Additionally, the evaluation is conducted on a limited dataset, so more comprehensive testing across diverse musical genres and styles would be valuable to fully assess the model's capabilities and limitations.
It would also be interesting to explore how this diffusion-based approach compares to other generative techniques, such as VAEs or GANs, in terms of audio quality, transfer fidelity, and computational efficiency.
Conclusion
This study presents an innovative music style transfer framework using diffusion models that addresses the limitations of previous one-to-one approaches. By enabling multi-to-multi style conversion and leveraging spectrogram-based techniques with the GuideDiff method, the model can generate high-quality, low-noise audio in real-time.
The findings suggest that diffusion models hold great promise for advancing the state-of-the-art in music style transfer, with potential applications in music production, entertainment, and creative industries. Further research to refine the model and expand the evaluation could lead to even more powerful and versatile tools for manipulating and transforming musical styles.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
On-the-fly Learning to Transfer Motion Style with Diffusion Models: A Semantic Guidance Approach
Lei Hu, Zihao Zhang, Yongjing Ye, Yiwen Xu, Shihong Xia
0
0
In recent years, the emergence of generative models has spurred development of human motion generation, among which the generation of stylized human motion has consistently been a focal point of research. The conventional approach for stylized human motion generation involves transferring the style from given style examples to new motions. Despite decades of research in human motion style transfer, it still faces three main challenges: 1) difficulties in decoupling the motion content and style; 2) generalization to unseen motion style. 3) requirements of dedicated motion style dataset; To address these issues, we propose an on-the-fly human motion style transfer learning method based on the diffusion model, which can learn a style transfer model in a few minutes of fine-tuning to transfer an unseen style to diverse content motions. The key idea of our method is to consider the denoising process of the diffusion model as a motion translation process that learns the difference between the style-neutral motion pair, thereby avoiding the challenge of style and content decoupling. Specifically, given an unseen style example, we first generate the corresponding neutral motion through the proposed Style-Neutral Motion Pair Generation module. We then add noise to the generated neutral motion and denoise it to be close to the style example to fine-tune the style transfer diffusion model. We only need one style example and a text-to-motion dataset with predominantly neutral motion (e.g. HumanML3D). The qualitative and quantitative evaluations demonstrate that our method can achieve state-of-the-art performance and has practical applications.
5/14/2024
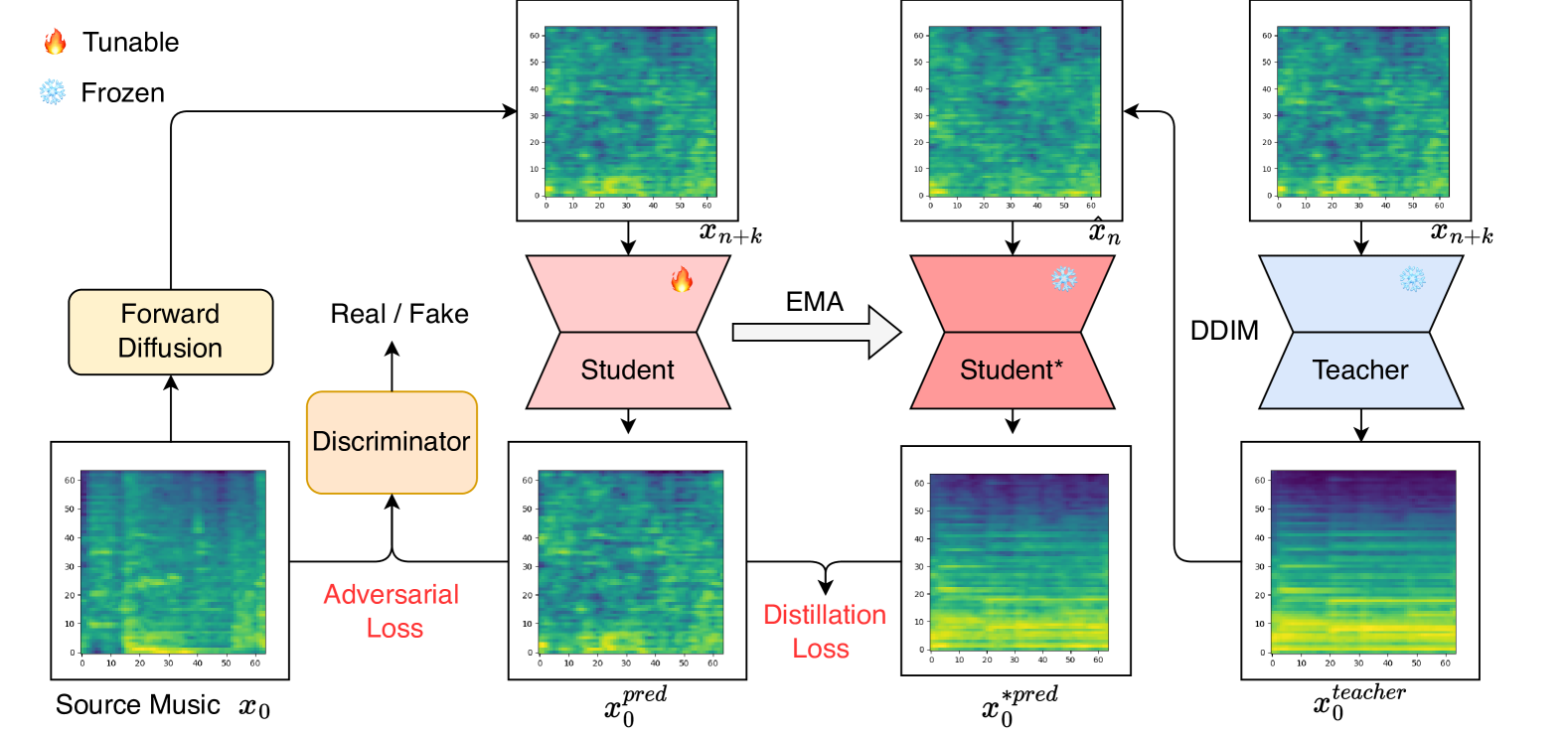
Music Consistency Models
Zhengcong Fei, Mingyuan Fan, Junshi Huang
0
0
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
4/23/2024
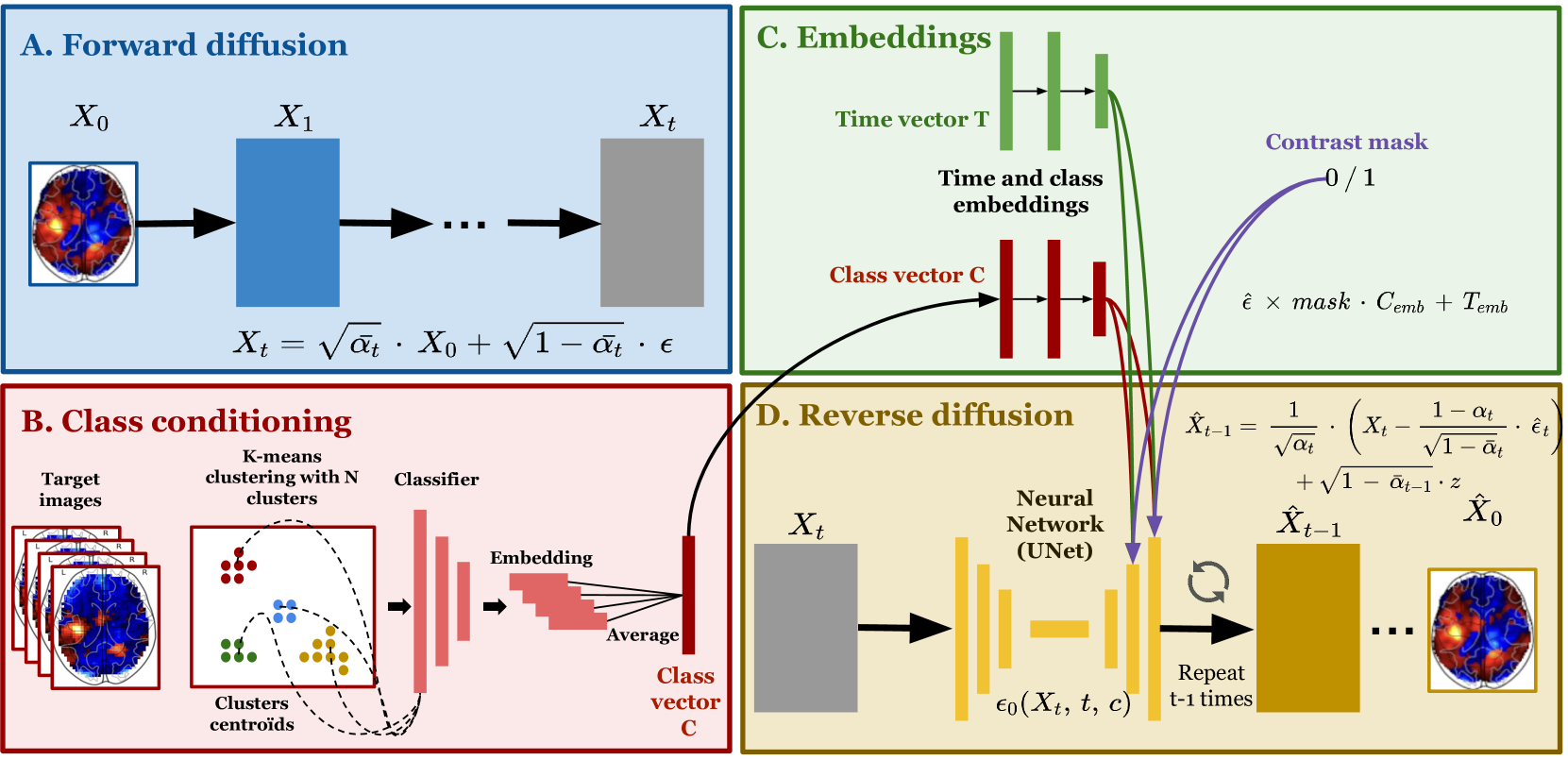
Mitigating analytical variability in fMRI results with style transfer
Elodie Germani (EMPENN, LACODAM), Elisa Fromont (LACODAM), Camille Maumet (EMPENN)
0
0
We propose a novel approach to improve the reproducibility of neuroimaging results by converting statistic maps across different functional MRI pipelines. We make the assumption that pipelines can be considered as a style component of data and propose to use different generative models, among which, Diffusion Models (DM) to convert data between pipelines. We design a new DM-based unsupervised multi-domain image-to-image transition framework and constrain the generation of 3D fMRI statistic maps using the latent space of an auxiliary classifier that distinguishes statistic maps from different pipelines. We extend traditional sampling techniques used in DM to improve the transition performance. Our experiments demonstrate that our proposed methods are successful: pipelines can indeed be transferred, providing an important source of data augmentation for future medical studies.
4/8/2024
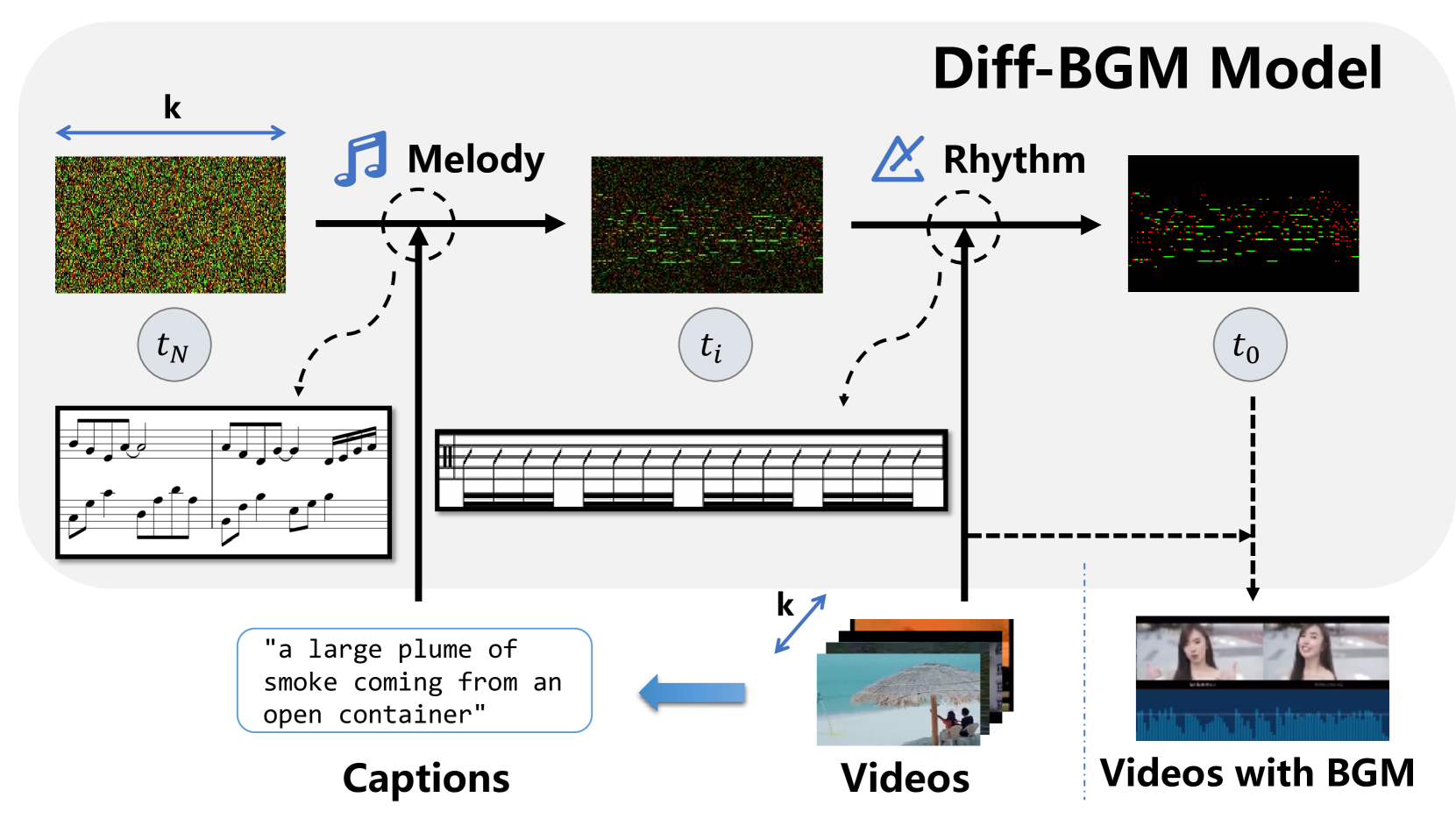
Diff-BGM: A Diffusion Model for Video Background Music Generation
Sizhe Li, Yiming Qin, Minghang Zheng, Xin Jin, Yang Liu
0
0
When editing a video, a piece of attractive background music is indispensable. However, video background music generation tasks face several challenges, for example, the lack of suitable training datasets, and the difficulties in flexibly controlling the music generation process and sequentially aligning the video and music. In this work, we first propose a high-quality music-video dataset BGM909 with detailed annotation and shot detection to provide multi-modal information about the video and music. We then present evaluation metrics to assess music quality, including music diversity and alignment between music and video with retrieval precision metrics. Finally, we propose the Diff-BGM framework to automatically generate the background music for a given video, which uses different signals to control different aspects of the music during the generation process, i.e., uses dynamic video features to control music rhythm and semantic features to control the melody and atmosphere. We propose to align the video and music sequentially by introducing a segment-aware cross-attention layer. Experiments verify the effectiveness of our proposed method. The code and models are available at https://github.com/sizhelee/Diff-BGM.
5/21/2024