Music Consistency Models
2404.13358
0
0
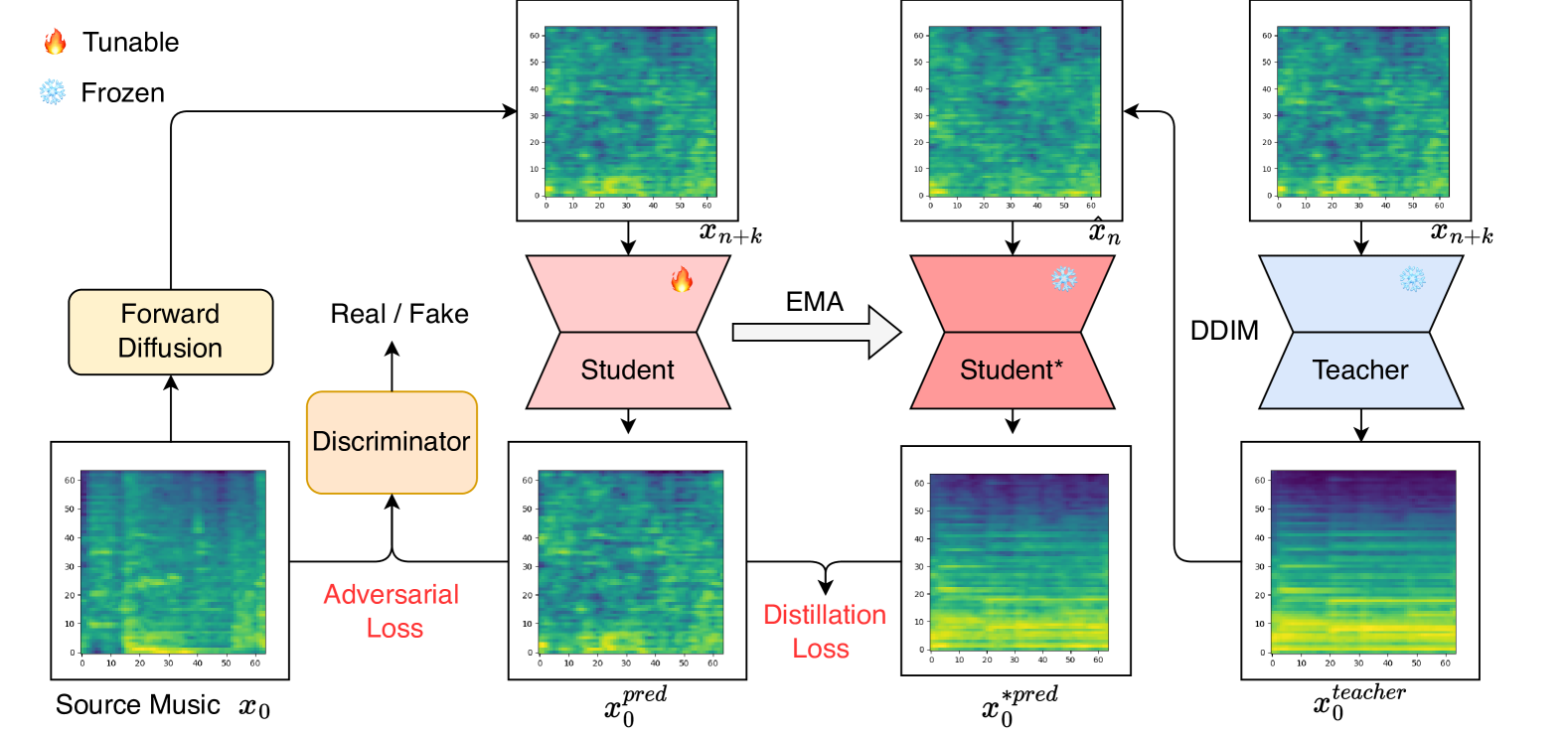
Abstract
Consistency models have exhibited remarkable capabilities in facilitating efficient image/video generation, enabling synthesis with minimal sampling steps. It has proven to be advantageous in mitigating the computational burdens associated with diffusion models. Nevertheless, the application of consistency models in music generation remains largely unexplored. To address this gap, we present Music Consistency Models (texttt{MusicCM}), which leverages the concept of consistency models to efficiently synthesize mel-spectrogram for music clips, maintaining high quality while minimizing the number of sampling steps. Building upon existing text-to-music diffusion models, the texttt{MusicCM} model incorporates consistency distillation and adversarial discriminator training. Moreover, we find it beneficial to generate extended coherent music by incorporating multiple diffusion processes with shared constraints. Experimental results reveal the effectiveness of our model in terms of computational efficiency, fidelity, and naturalness. Notable, texttt{MusicCM} achieves seamless music synthesis with a mere four sampling steps, e.g., only one second per minute of the music clip, showcasing the potential for real-time application.
Create account to get full access
Overview
- This paper explores "Music Consistency Models" - a novel approach to generating high-quality, consistent music using diffusion models.
- The authors propose several techniques to improve the consistency and coherence of generated music, including a "semantic approach to quantifying consistency" and a reinforcement learning-based method for faster model training.
- The research aims to address key challenges in long-form music generation, such as maintaining thematic and harmonic continuity, and accelerating the training of diffusion models used for this task.
Plain English Explanation
The researchers in this paper are working on a problem called "long-form music generation". This means using AI to create full, coherent musical compositions, rather than just short snippets or loops.
One of the key challenges with this is making sure the music stays consistent and coherent throughout the entire piece. It's easy for AI systems to generate music that starts off good but then gets disjointed or loses its theme as it goes on.
To address this, the researchers propose several new "Music Consistency Models". These are techniques that help the AI system keep the music sounding cohesive and thematically unified from start to finish.
For example, they developed a way to mathematically measure how "consistent" the generated music is, based on its semantic and harmonic properties. This allows the system to monitor its own consistency and make adjustments.
They also tried speeding up the training process for the AI models that generate the music, using a reinforcement learning approach. This makes the models train faster, which could allow for more experimentation and refinement to improve consistency.
Overall, the goal is to make AI-generated music sound more like it was composed by a skilled human musician, with a clear musical narrative and intentionality, rather than just random notes put together. This could have big implications for things like procedurally generated music in video games, or AI songwriting assistants.
Technical Explanation
The paper presents several novel approaches to improving the consistency and coherence of long-form music generation using diffusion models.
First, the authors introduce a "Semantic Approach to Quantifying Consistency" for diffusion models. This involves defining a set of semantic and harmonic features that characterize the "consistency" of a generated musical sequence. The model can then be trained to optimize for these consistency metrics, helping to maintain thematic and harmonic unity throughout the generated composition.
The researchers also propose a "Reinforcement Learning Consistency Model" that uses RL to accelerate the training of diffusion models for long-form music generation. By incorporating consistency rewards directly into the training process, this approach can lead to faster convergence and more coherent final outputs.
Additionally, the paper explores techniques for "Accelerating Diffusion Models" through methods like stochastic consistency distillation. These can reduce training time and computational cost without sacrificing the quality of the generated music.
Overall, the innovations presented in this work aim to advance the state-of-the-art in AI-generated music, making it more consistent, coherent and purposeful - characteristics that are critical for long-form musical compositions.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper. One key challenge they identify is the difficulty of objectively evaluating the "consistency" of generated music, as this is a somewhat subjective quality. The proposed semantic metrics provide one approach, but further research may be needed to develop more robust and nuanced consistency measures.
Additionally, while the reinforcement learning and acceleration techniques show promising results, the authors note that they may be sensitive to hyperparameter choices and architectural details. Expanding the evaluation to a wider range of music generation tasks and datasets could help validate the generalizability of these methods.
It's also worth considering potential biases or limitations introduced by the training data and model architectures used. As with any AI system, the outputs will be shaped by the characteristics of the data and modeling choices, which may not fully capture the rich complexities of human-composed music.
Nonetheless, this work represents an important step forward in addressing crucial challenges in long-form music generation. The proposed "Music Consistency Models" offer a principled and innovative approach that could have significant implications for AI-powered music creation and interaction.
Conclusion
This paper presents novel techniques for improving the consistency and coherence of AI-generated music, a critical requirement for creating high-quality, long-form musical compositions.
By developing methods to quantify and optimize for "consistency" based on semantic and harmonic features, as well as accelerating the training of diffusion models through reinforcement learning and other techniques, the researchers have made meaningful progress toward overcoming key limitations in this domain.
While further research is needed to fully address the challenges of AI music generation, this work represents an important step forward. The insights and innovations described could pave the way for more purposeful, expressive and human-like AI-composed music, with applications ranging from procedural content generation in games to AI-assisted songwriting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SoundCTM: Uniting Score-based and Consistency Models for Text-to-Sound Generation
Koichi Saito, Dongjun Kim, Takashi Shibuya, Chieh-Hsin Lai, Zhi Zhong, Yuhta Takida, Yuki Mitsufuji
0
0
Sound content is an indispensable element for multimedia works such as video games, music, and films. Recent high-quality diffusion-based sound generation models can serve as valuable tools for the creators. However, despite producing high-quality sounds, these models often suffer from slow inference speeds. This drawback burdens creators, who typically refine their sounds through trial and error to align them with their artistic intentions. To address this issue, we introduce Sound Consistency Trajectory Models (SoundCTM). Our model enables flexible transitioning between high-quality 1-step sound generation and superior sound quality through multi-step generation. This allows creators to initially control sounds with 1-step samples before refining them through multi-step generation. While CTM fundamentally achieves flexible 1-step and multi-step generation, its impressive performance heavily depends on an additional pretrained feature extractor and an adversarial loss, which are expensive to train and not always available in other domains. Thus, we reframe CTM's training framework and introduce a novel feature distance by utilizing the teacher's network for a distillation loss. Additionally, while distilling classifier-free guided trajectories, we train conditional and unconditional student models simultaneously and interpolate between these models during inference. We also propose training-free controllable frameworks for SoundCTM, leveraging its flexible sampling capability. SoundCTM achieves both promising 1-step and multi-step real-time sound generation without using any extra off-the-shelf networks. Furthermore, we demonstrate SoundCTM's capability of controllable sound generation in a training-free manner. Our codes, pretrained models, and audio samples are available at https://github.com/sony/soundctm.
6/12/2024

Consistency Models Made Easy
Zhengyang Geng, Ashwini Pokle, William Luo, Justin Lin, J. Zico Kolter
0
0
Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point. But this target leads to resource-intensive training: for example, as of 2024, training a SoTA CM on CIFAR-10 takes one week on 8 GPUs. In this work, we propose an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, we argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. Owing to this computational efficiency, we investigate the scaling law of CMs under ECT, showing that they seem to obey classic power law scaling, hinting at their ability to improve efficiency and performance at larger scales. Code (https://github.com/locuslab/ect) is available.
6/21/2024
📈
Phased Consistency Model
Fu-Yun Wang, Zhaoyang Huang, Alexander William Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, Hongsheng Li, Xiaogang Wang
0
0
The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.
5/29/2024
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Huadai Liu, Rongjie Huang, Yang Liu, Hengyuan Cao, Jialei Wang, Xize Cheng, Siqi Zheng, Zhou Zhao
0
0
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
6/4/2024