Mutimodal Ranking Optimization for Heterogeneous Face Re-identification

0
🛠️
Sign in to get full access
Overview
- Proposes a multimodal fusion ranking optimization algorithm for heterogeneous face re-identification across visible light (VIS) and near-infrared (NIR) cameras
- Addresses the challenge of large domain discrepancy between NIR and VIS faces that degrades face re-identification performance
- Includes a heterogeneous face translation network to generate multimodal face pairs, and linear/non-linear fusion strategies to combine ranking lists for optimization
Plain English Explanation
The paper tackles the problem of matching faces captured by visible light (VIS) and near-infrared (NIR) cameras, known as heterogeneous face re-identification. This is an important challenge in video surveillance applications, as the visual differences between VIS and NIR faces can significantly degrade the performance of face matching algorithms.
To address this, the researchers propose a two-part solution. First, they develop a heterogeneous face translation network that can convert NIR face images into their VIS counterparts, and vice versa. This allows them to generate multimodal face pairs (NIR-VIS, NIR-NIR, VIS-VIS) that can be used for training and evaluation.
Second, the researchers propose fusion strategies to combine the initial ranking lists obtained from matching the different face modalities. This allows them to leverage the complementary information in the VIS and NIR face representations to optimize the final re-identification performance.
The key insight is that by translating between VIS and NIR face domains and fusing the resulting matchings, the algorithm can overcome the challenges posed by the large visual differences between the two modalities.
Technical Explanation
The paper first presents a heterogeneous face translation network that can perform mutual transformation between NIR and VIS face images. This allows the generation of multimodal face pairs (NIR-VIS, NIR-NIR, VIS-VIS) that can be used for training and evaluation.
The researchers then propose two fusion strategies to combine the initial ranking lists obtained from matching the different face modalities:
- Linear fusion: Applies a weighted sum to the ranking scores from the individual modalities.
- Non-linear fusion: Uses a neural network to learn a non-linear combination of the ranking scores.
By fusing the ranking lists in this way, the algorithm can leverage the complementary information in the VIS and NIR face representations to optimize the final re-identification performance.
The experiments conducted on the SCface dataset show that the proposed multimodal fusion ranking optimization algorithm outperforms several related methods, demonstrating the effectiveness of the approach.
Critical Analysis
The paper presents a well-designed solution to the challenging problem of heterogeneous face re-identification. The use of a translation network to generate multimodal face pairs is a clever way to address the domain gap between VIS and NIR modalities, and the fusion strategies effectively combine the complementary information from the different modalities.
However, the paper does not provide much discussion on the limitations of the proposed approach. For example, the performance of the translation network and the fusion strategies may degrade when dealing with more complex real-world scenarios, such as variations in lighting, pose, or occlusion. Additionally, the reliance on the SCface dataset, which is relatively small and may not capture the full complexity of real-world surveillance scenarios, could be a potential limitation.
Further research could explore unsupervised or dynamic approaches to address these challenges, or investigate the application of the proposed techniques to other cross-modal person re-identification problems.
Conclusion
This paper presents a novel multimodal fusion ranking optimization algorithm for heterogeneous face re-identification across VIS and NIR cameras. By leveraging a heterogeneous face translation network and fusion strategies, the proposed approach can effectively overcome the large domain discrepancy between the two modalities and optimize the face re-identification performance.
The research demonstrates the value of combining complementary information from different modalities to tackle challenging computer vision problems, and the insights gained could have broader applications in areas such as multi-sensor data fusion and cross-modal retrieval.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
Mutimodal Ranking Optimization for Heterogeneous Face Re-identification
Hui Hu, Jiawei Zhang, Zhen Han
Heterogeneous face re-identification, namely matching heterogeneous faces across disjoint visible light (VIS) and near-infrared (NIR) cameras, has become an important problem in video surveillance application. However, the large domain discrepancy between heterogeneous NIR-VIS faces makes the performance of face re-identification degraded dramatically. To solve this problem, a multimodal fusion ranking optimization algorithm for heterogeneous face re-identification is proposed in this paper. Firstly, we design a heterogeneous face translation network to obtain multimodal face pairs, including NIR-VIS/NIR-NIR/VIS-VIS face pairs, through mutual transformation between NIR-VIS faces. Secondly, we propose linear and non-linear fusion strategies to aggregate initial ranking lists of multimodal face pairs and acquire the optimized re-ranked list based on modal complementarity. The experimental results show that the proposed multimodal fusion ranking optimization algorithm can effectively utilize the complementarity and outperforms some relative methods on the SCface dataset.
Read more5/29/2024

0
Parameter Hierarchical Optimization for Visible-Infrared Person Re-Identification
Zeng YU, Yunxiao Shi
Visible-infrared person re-identification (VI-reID) aims at matching cross-modality pedestrian images captured by disjoint visible or infrared cameras. Existing methods alleviate the cross-modality discrepancies via designing different kinds of network architectures. Different from available methods, in this paper, we propose a novel parameter optimizing paradigm, parameter hierarchical optimization (PHO) method, for the task of VI-ReID. It allows part of parameters to be directly optimized without any training, which narrows the search space of parameters and makes the whole network more easier to be trained. Specifically, we first divide the parameters into different types, and then introduce a self-adaptive alignment strategy (SAS) to automatically align the visible and infrared images through transformation. Considering that features in different dimension have varying importance, we develop an auto-weighted alignment learning (AAL) module that can automatically weight features according to their importance. Importantly, in the alignment process of SAS and AAL, all the parameters are immediately optimized with optimization principles rather than training the whole network, which yields a better parameter training manner. Furthermore, we establish the cross-modality consistent learning (CCL) loss to extract discriminative person representations with translation consistency. We provide both theoretical justification and empirical evidence that our proposed PHO method outperform existing VI-reID approaches.
Read more4/12/2024
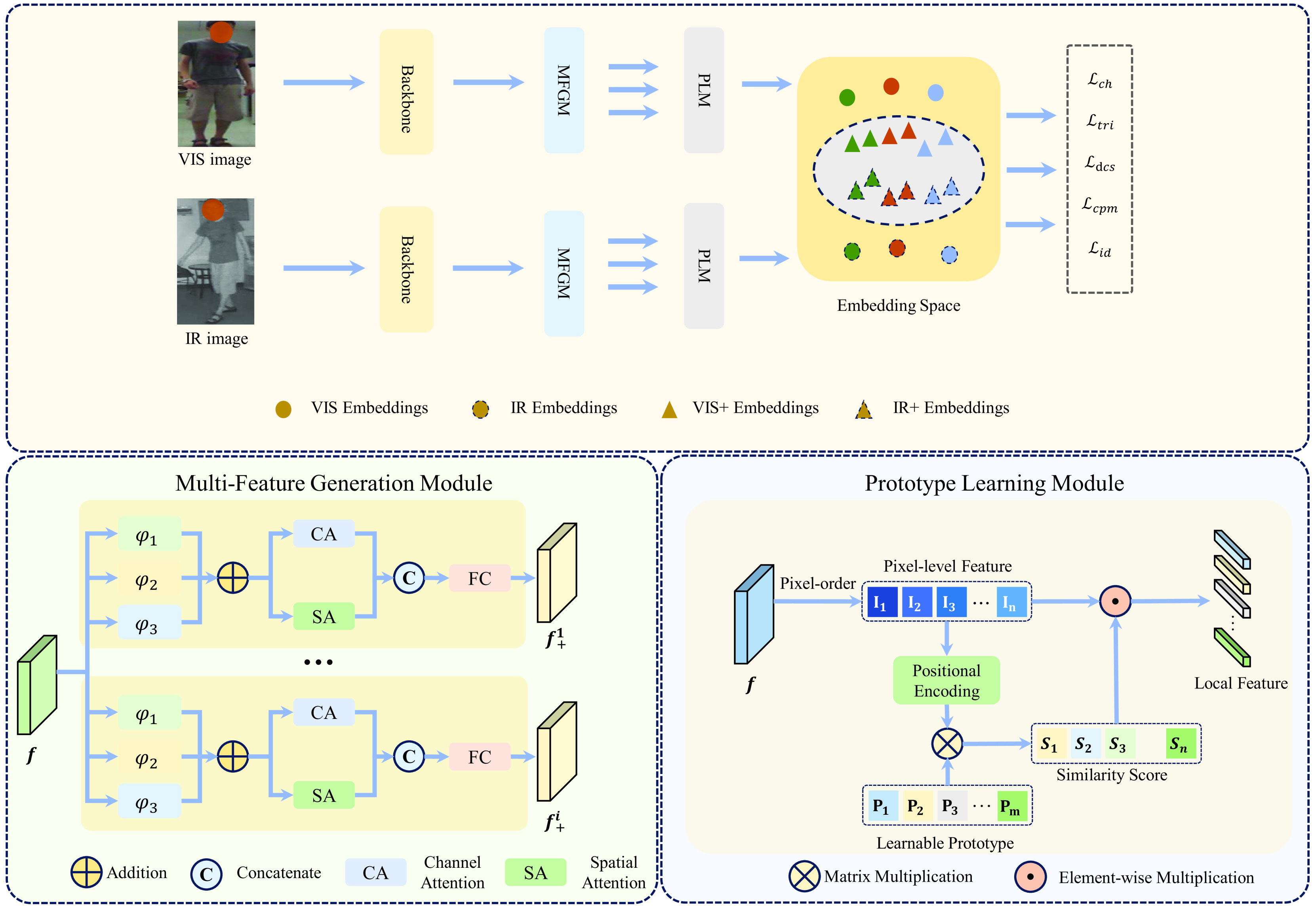
0
Prototype-Driven Multi-Feature Generation for Visible-Infrared Person Re-identification
Jiarui Li, Zhen Qiu, Yilin Yang, Yuqi Li, Zeyu Dong, Chuanguang Yang
The primary challenges in visible-infrared person re-identification arise from the differences between visible (vis) and infrared (ir) images, including inter-modal and intra-modal variations. These challenges are further complicated by varying viewpoints and irregular movements. Existing methods often rely on horizontal partitioning to align part-level features, which can introduce inaccuracies and have limited effectiveness in reducing modality discrepancies. In this paper, we propose a novel Prototype-Driven Multi-feature generation framework (PDM) aimed at mitigating cross-modal discrepancies by constructing diversified features and mining latent semantically similar features for modal alignment. PDM comprises two key components: Multi-Feature Generation Module (MFGM) and Prototype Learning Module (PLM). The MFGM generates diversity features closely distributed from modality-shared features to represent pedestrians. Additionally, the PLM utilizes learnable prototypes to excavate latent semantic similarities among local features between visible and infrared modalities, thereby facilitating cross-modal instance-level alignment. We introduce the cosine heterogeneity loss to enhance prototype diversity for extracting rich local features. Extensive experiments conducted on the SYSU-MM01 and LLCM datasets demonstrate that our approach achieves state-of-the-art performance. Our codes are available at https://github.com/mmunhappy/ICASSP2025-PDM.
Read more9/10/2024
🤷
0
Efficient Bilateral Cross-Modality Cluster Matching for Unsupervised Visible-Infrared Person ReID
De Cheng, Lingfeng He, Nannan Wang, Shizhou Zhang, Zhen Wang, Xinbo Gao
Unsupervised visible-infrared person re-identification (USL-VI-ReID) aims to match pedestrian images of the same identity from different modalities without annotations. Existing works mainly focus on alleviating the modality gap by aligning instance-level features of the unlabeled samples. However, the relationships between cross-modality clusters are not well explored. To this end, we propose a novel bilateral cluster matching-based learning framework to reduce the modality gap by matching cross-modality clusters. Specifically, we design a Many-to-many Bilateral Cross-Modality Cluster Matching (MBCCM) algorithm through optimizing the maximum matching problem in a bipartite graph. Then, the matched pairwise clusters utilize shared visible and infrared pseudo-labels during the model training. Under such a supervisory signal, a Modality-Specific and Modality-Agnostic (MSMA) contrastive learning framework is proposed to align features jointly at a cluster-level. Meanwhile, the cross-modality Consistency Constraint (CC) is proposed to explicitly reduce the large modality discrepancy. Extensive experiments on the public SYSU-MM01 and RegDB datasets demonstrate the effectiveness of the proposed method, surpassing state-of-the-art approaches by a large margin of 8.76% mAP on average.
Read more5/28/2024