Prototype-Driven Multi-Feature Generation for Visible-Infrared Person Re-identification

0
Sign in to get full access
Overview
- Visible-infrared person re-identification is a challenging task due to modality discrepancies between visible and infrared images
- This paper proposes a novel "Prototype-Driven Multi-Feature Generation" (PDMFG) approach to address this challenge
- The key idea is to leverage instance-level alignment between visible and infrared features to generate complementary features for improved re-identification performance
Plain English Explanation
The paper addresses the problem of visible-infrared person re-identification, which is identifying the same person across visible (normal) and infrared (heat-sensing) camera images. This is challenging because the two types of images can look quite different, making it hard to match people between them.
The researchers developed a new method called "Prototype-Driven Multi-Feature Generation" (PDMFG) to tackle this challenge. The key idea is to first find instances (examples) of the same person in both visible and infrared images, and use these to generate additional complementary features that help distinguish people across the two modalities.
By aligning the features at the instance level, the model can learn the commonalities and differences between visible and infrared images of the same person. This allows it to generate new features that capture information unique to each modality, improving the overall person re-identification performance.
Technical Explanation
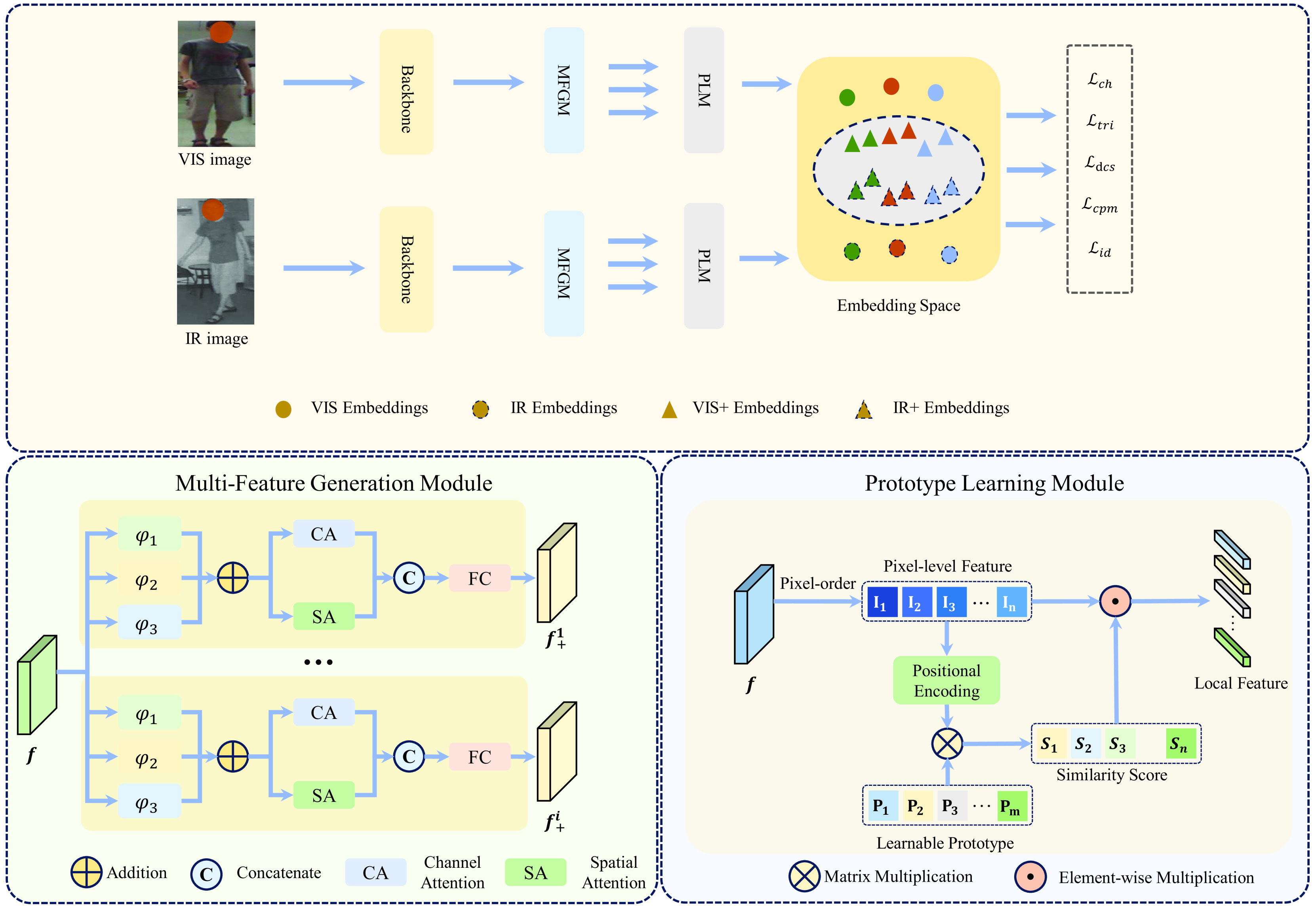
The PDMFG approach consists of three main components:
-
Prototype Generation: This step identifies instance-level correspondences between visible and infrared images of the same person. It does this by clustering the features of the two modalities and finding the best matching pairs.
-
Multi-Feature Generation: Using the aligned prototypes, the model generates supplementary features that capture both the commonalities and differences between the visible and infrared representations of each person.
-
Feature Fusion and Re-identification: The original and generated features are combined and fed into the final re-identification network, which learns to match people across the two modalities.
The key innovation is the use of instance-level alignment to drive the multi-feature generation process. This allows the model to better handle the modality discrepancies between visible and infrared images, leading to improved re-identification performance.
Critical Analysis
The paper provides a novel and effective solution to the challenging visible-infrared person re-identification problem. However, some potential limitations and areas for future work are:
-
The prototype generation step relies on clustering, which can be sensitive to hyperparameters and the underlying data distribution. More robust instance-level alignment methods could be explored.
-
The multi-feature generation process is not deeply analyzed, and its inner workings could be further investigated and potentially improved.
-
The experiments are conducted on a single dataset, so the generalizability of the approach to other visible-infrared re-identification benchmarks is unclear and could be studied further.
-
While the proposed PDMFG method outperforms existing techniques, there is still room for improvement in overall re-identification accuracy, especially in more realistic and challenging scenarios.
Overall, the paper presents a compelling and promising direction for addressing visible-infrared person re-identification, but additional research is needed to fully understand and refine the approach.
Conclusion
This paper introduces a novel "Prototype-Driven Multi-Feature Generation" (PDMFG) method to tackle the challenging problem of visible-infrared person re-identification. By leveraging instance-level alignment between the two modalities, the approach is able to generate complementary features that capture both the commonalities and differences, leading to improved re-identification performance.
The key technical contributions include the prototype generation and multi-feature generation components, which work together to address the modality discrepancies inherent in visible and infrared person images. While the paper demonstrates the effectiveness of the PDMFG method, there are also opportunities for further refinement and exploration of its broader applicability.
Overall, this research represents an important step forward in the field of visible-infrared person re-identification, with potential real-world applications in areas such as surveillance, security, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Prototype-Driven Multi-Feature Generation for Visible-Infrared Person Re-identification
Jiarui Li, Zhen Qiu, Yilin Yang, Yuqi Li, Zeyu Dong, Chuanguang Yang
The primary challenges in visible-infrared person re-identification arise from the differences between visible (vis) and infrared (ir) images, including inter-modal and intra-modal variations. These challenges are further complicated by varying viewpoints and irregular movements. Existing methods often rely on horizontal partitioning to align part-level features, which can introduce inaccuracies and have limited effectiveness in reducing modality discrepancies. In this paper, we propose a novel Prototype-Driven Multi-feature generation framework (PDM) aimed at mitigating cross-modal discrepancies by constructing diversified features and mining latent semantically similar features for modal alignment. PDM comprises two key components: Multi-Feature Generation Module (MFGM) and Prototype Learning Module (PLM). The MFGM generates diversity features closely distributed from modality-shared features to represent pedestrians. Additionally, the PLM utilizes learnable prototypes to excavate latent semantic similarities among local features between visible and infrared modalities, thereby facilitating cross-modal instance-level alignment. We introduce the cosine heterogeneity loss to enhance prototype diversity for extracting rich local features. Extensive experiments conducted on the SYSU-MM01 and LLCM datasets demonstrate that our approach achieves state-of-the-art performance. Our codes are available at https://github.com/mmunhappy/ICASSP2025-PDM.
Read more9/10/2024
🏷️
0
Visible-Infrared Person Re-Identification via Patch-Mixed Cross-Modality Learning
Zhihao Qian, Yutian Lin, Bo Du
Visible-infrared person re-identification (VI-ReID) aims to retrieve images of the same pedestrian from different modalities, where the challenges lie in the significant modality discrepancy. To alleviate the modality gap, recent methods generate intermediate images by GANs, grayscaling, or mixup strategies. However, these methods could introduce extra data distribution, and the semantic correspondence between the two modalities is not well learned. In this paper, we propose a Patch-Mixed Cross-Modality framework (PMCM), where two images of the same person from two modalities are split into patches and stitched into a new one for model learning. A part-alignment loss is introduced to regularize representation learning, and a patch-mixed modality learning loss is proposed to align between the modalities. In this way, the model learns to recognize a person through patches of different styles, thereby the modality semantic correspondence can be inferred. In addition, with the flexible image generation strategy, the patch-mixed images freely adjust the ratio of different modality patches, which could further alleviate the modality imbalance problem. On two VI-ReID datasets, we report new state-of-the-art performance with the proposed method.
Read more5/1/2024

0
Learning Commonality, Divergence and Variety for Unsupervised Visible-Infrared Person Re-identification
Jiangming Shi, Xiangbo Yin, Yaoxing Wang, Xiaofeng Liu, Yuan Xie, Yanyun Qu
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match specified people in infrared images to visible images without annotation, and vice versa. USVI-ReID is a challenging yet under-explored task. Most existing methods address the USVI-ReID problem using cluster-based contrastive learning, which simply employs the cluster center as a representation of a person. However, the cluster center primarily focuses on shared information, overlooking disparity. To address the problem, we propose a Progressive Contrastive Learning with Multi-Prototype (PCLMP) method for USVI-ReID. In brief, we first generate the hard prototype by selecting the sample with the maximum distance from the cluster center. This hard prototype is used in the contrastive loss to emphasize disparity. Additionally, instead of rigidly aligning query images to a specific prototype, we generate the dynamic prototype by randomly picking samples within a cluster. This dynamic prototype is used to retain the natural variety of features while reducing instability in the simultaneous learning of both common and disparate information. Finally, we introduce a progressive learning strategy to gradually shift the model's attention towards hard samples, avoiding cluster deterioration. Extensive experiments conducted on the publicly available SYSU-MM01 and RegDB datasets validate the effectiveness of the proposed method. PCLMP outperforms the existing state-of-the-art method with an average mAP improvement of 3.9%. The source codes will be released.
Read more5/28/2024

0
Unsupervised Visible-Infrared ReID via Pseudo-label Correction and Modality-level Alignment
Yexin Liu, Weiming Zhang, Athanasios V. Vasilakos, Lin Wang
Unsupervised visible-infrared person re-identification (UVI-ReID) has recently gained great attention due to its potential for enhancing human detection in diverse environments without labeling. Previous methods utilize intra-modality clustering and cross-modality feature matching to achieve UVI-ReID. However, there exist two challenges: 1) noisy pseudo labels might be generated in the clustering process, and 2) the cross-modality feature alignment via matching the marginal distribution of visible and infrared modalities may misalign the different identities from two modalities. In this paper, we first conduct a theoretic analysis where an interpretable generalization upper bound is introduced. Based on the analysis, we then propose a novel unsupervised cross-modality person re-identification framework (PRAISE). Specifically, to address the first challenge, we propose a pseudo-label correction strategy that utilizes a Beta Mixture Model to predict the probability of mis-clustering based network's memory effect and rectifies the correspondence by adding a perceptual term to contrastive learning. Next, we introduce a modality-level alignment strategy that generates paired visible-infrared latent features and reduces the modality gap by aligning the labeling function of visible and infrared features to learn identity discriminative and modality-invariant features. Experimental results on two benchmark datasets demonstrate that our method achieves state-of-the-art performance than the unsupervised visible-ReID methods.
Read more4/11/2024