MUVO: A Multimodal World Model with Spatial Representations for Autonomous Driving

0
📈
Sign in to get full access
Overview
- The paper proposes a new approach called MUVO (MUltimodal World Model with spatial VOxel representations) to learn unsupervised world models for autonomous driving.
- Current systems mostly focus on sensor data alone, neglecting the physical attributes of the world.
- MUVO utilizes raw camera and lidar data to learn a sensor-agnostic geometric representation of the world.
- The system demonstrates multimodal future predictions and shows that the spatial representation improves the prediction quality of both camera images and lidar point clouds.
Plain English Explanation
The paper introduces a new way to help self-driving cars better understand the world around them. Current systems often focus only on the sensor data, like camera images and lidar scans, without considering the physical properties of the real-world environment. The proposed MUVO approach uses both camera and lidar data to create a more comprehensive and realistic 3D representation of the world. This spatial model allows the self-driving system to make better predictions about the future, such as how objects might move or change over time. By considering the physical world, rather than just sensor inputs, MUVO has the potential to significantly improve the reasoning and decision-making capabilities of autonomous driving systems.
Technical Explanation
The paper presents MUVO, a MUltimodal World Model that uses spatial VOxel representations to learn an unsupervised model of the physical world for autonomous driving. The key innovation is the use of both camera and lidar data to build a sensor-agnostic geometric representation of the environment.
The system takes raw camera images and lidar point clouds as input and learns to predict future states of the scene, including both camera images and lidar point clouds. This multimodal prediction task encourages the model to build a rich, holistic understanding of the 3D world.
The spatial voxel representation allows the model to capture the physical structure and properties of the environment, beyond just the sensor data. This spatial awareness is shown to improve the quality of both camera image and lidar point cloud predictions, compared to models that only consider sensor inputs.
Critical Analysis
The paper presents a promising approach to building more sophisticated world models for autonomous driving, but there are a few potential limitations and areas for further research:
- The experiments are conducted on a single dataset, CARLA, which is a simulated environment. It will be important to evaluate the approach on real-world data to ensure the findings translate to the more complex and noisy conditions of the physical world.
- The paper does not address how the learned world model could be integrated into the broader decision-making and control systems of an autonomous vehicle. Exploring this integration and its impact on overall driving performance would be a valuable next step.
- While the spatial voxel representation is shown to improve prediction quality, the paper does not provide a deep analysis of how this representation facilitates reasoning about the physical properties of the environment. Further research could investigate the specific advantages and limitations of this approach.
Despite these potential areas for improvement, the MUVO approach represents an important step forward in developing more sophisticated and holistic world models for autonomous driving. By considering the physical attributes of the environment, in addition to sensor data, the system has the potential to significantly enhance the reasoning and decision-making capabilities of self-driving cars.
Conclusion
The paper introduces MUVO, a novel approach to learning unsupervised world models for autonomous driving. By leveraging both camera and lidar data, MUVO constructs a sensor-agnostic spatial representation of the environment that captures the physical properties of the world. This spatial awareness allows the system to make improved multimodal predictions, which could lead to better decision-making and control in self-driving vehicles.
While the research is still in the early stages, the MUVO approach represents an important step towards developing more sophisticated and holistic world models for autonomous driving, with the potential to significantly enhance the reasoning capabilities of today's systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
MUVO: A Multimodal World Model with Spatial Representations for Autonomous Driving
Daniel Bogdoll, Yitian Yang, Tim Joseph, J. Marius Zollner
Learning unsupervised world models for autonomous driving has the potential to improve the reasoning capabilities of today's systems dramatically. However, most work neglects the physical attributes of the world and focuses on sensor data alone. We propose MUVO, a MUltimodal World Model with spatial VOxel representations, to address this challenge. We utilize raw camera and lidar data to learn a sensor-agnostic geometric representation of the world. We demonstrate multimodal future predictions and show that our spatial representation improves the prediction quality of both camera images and lidar point clouds.
Read more7/29/2024

0
BEVWorld: A Multimodal World Model for Autonomous Driving via Unified BEV Latent Space
Yumeng Zhang, Shi Gong, Kaixin Xiong, Xiaoqing Ye, Xiao Tan, Fan Wang, Jizhou Huang, Hua Wu, Haifeng Wang
World models are receiving increasing attention in autonomous driving for their ability to predict potential future scenarios. In this paper, we present BEVWorld, a novel approach that tokenizes multimodal sensor inputs into a unified and compact Bird's Eye View (BEV) latent space for environment modeling. The world model consists of two parts: the multi-modal tokenizer and the latent BEV sequence diffusion model. The multi-modal tokenizer first encodes multi-modality information and the decoder is able to reconstruct the latent BEV tokens into LiDAR and image observations by ray-casting rendering in a self-supervised manner. Then the latent BEV sequence diffusion model predicts future scenarios given action tokens as conditions. Experiments demonstrate the effectiveness of BEVWorld in autonomous driving tasks, showcasing its capability in generating future scenes and benefiting downstream tasks such as perception and motion prediction. Code will be available at https://github.com/zympsyche/BevWorld.
Read more7/19/2024

0
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
Yu Yang, Jianbiao Mei, Yukai Ma, Siliang Du, Wenqing Chen, Yijie Qian, Yuxiang Feng, Yong Liu
World models envision potential future states based on various ego actions. They embed extensive knowledge about the driving environment, facilitating safe and scalable autonomous driving. Most existing methods primarily focus on either data generation or the pretraining paradigms of world models. Unlike the aforementioned prior works, we propose Drive-OccWorld, which adapts a vision-centric 4D forecasting world model to end-to-end planning for autonomous driving. Specifically, we first introduce a semantic and motion-conditional normalization in the memory module, which accumulates semantic and dynamic information from historical BEV embeddings. These BEV features are then conveyed to the world decoder for future occupancy and flow forecasting, considering both geometry and spatiotemporal modeling. Additionally, we propose injecting flexible action conditions, such as velocity, steering angle, trajectory, and commands, into the world model to enable controllable generation and facilitate a broader range of downstream applications. Furthermore, we explore integrating the generative capabilities of the 4D world model with end-to-end planning, enabling continuous forecasting of future states and the selection of optimal trajectories using an occupancy-based cost function. Extensive experiments on the nuScenes dataset demonstrate that our method can generate plausible and controllable 4D occupancy, opening new avenues for driving world generation and end-to-end planning.
Read more8/27/2024
0
Probing Multimodal LLMs as World Models for Driving
Shiva Sreeram, Tsun-Hsuan Wang, Alaa Maalouf, Guy Rosman, Sertac Karaman, Daniela Rus
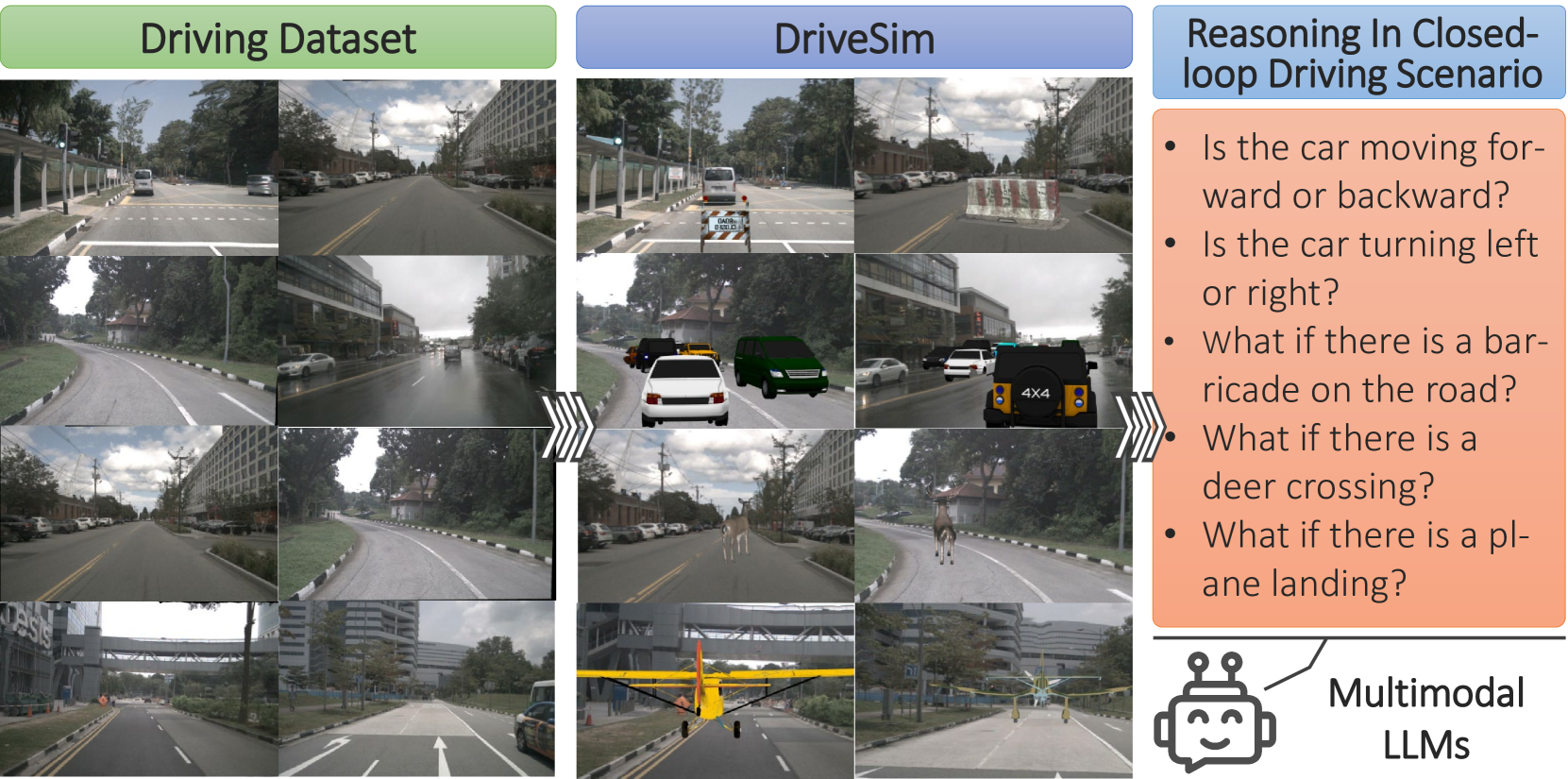
We provide a sober look at the application of Multimodal Large Language Models (MLLMs) within the domain of autonomous driving and challenge/verify some common assumptions, focusing on their ability to reason and interpret dynamic driving scenarios through sequences of images/frames in a closed-loop control environment. Despite the significant advancements in MLLMs like GPT-4V, their performance in complex, dynamic driving environments remains largely untested and presents a wide area of exploration. We conduct a comprehensive experimental study to evaluate the capability of various MLLMs as world models for driving from the perspective of a fixed in-car camera. Our findings reveal that, while these models proficiently interpret individual images, they struggle significantly with synthesizing coherent narratives or logical sequences across frames depicting dynamic behavior. The experiments demonstrate considerable inaccuracies in predicting (i) basic vehicle dynamics (forward/backward, acceleration/deceleration, turning right or left), (ii) interactions with other road actors (e.g., identifying speeding cars or heavy traffic), (iii) trajectory planning, and (iv) open-set dynamic scene reasoning, suggesting biases in the models' training data. To enable this experimental study we introduce a specialized simulator, DriveSim, designed to generate diverse driving scenarios, providing a platform for evaluating MLLMs in the realms of driving. Additionally, we contribute the full open-source code and a new dataset, Eval-LLM-Drive, for evaluating MLLMs in driving. Our results highlight a critical gap in the current capabilities of state-of-the-art MLLMs, underscoring the need for enhanced foundation models to improve their applicability in real-world dynamic environments.
Read more5/10/2024