MuxServe: Flexible Multiplexing for Efficient Multiple LLM Serving

0
🤔
Sign in to get full access
Overview
- Large language models (LLMs) have demonstrated impressive capabilities, leading organizations to provide access to various LLM sizes for use cases like chat, programming, and search.
- Efficiently serving multiple LLMs poses significant challenges due to their varying popularity.
- The paper introduces MuxServe, a system designed to address these challenges through spatial-temporal multiplexing.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can perform a wide range of tasks, from answering questions to generating text. Businesses and organizations are eager to make these models available to their customers, providing access to LLMs of different sizes and capabilities to suit various needs.
However, serving multiple LLMs simultaneously is a complex challenge. Some LLMs are more popular than others, meaning they receive a higher volume of requests. This can lead to inefficiencies in how the available computing resources are used to handle those requests.
The researchers behind this paper have developed a system called MuxServe that aims to address this problem. MuxServe uses a technique called "spatial-temporal multiplexing" to more efficiently manage the resources needed to serve multiple LLMs. The key idea is to group together LLMs that are used similarly, allowing the system to better utilize the available memory and computing power.
By carefully coordinating the way LLMs are deployed and the order in which requests are processed, MuxServe can achieve significant improvements in throughput and response times, helping organizations make the most of their LLM investments.
Technical Explanation
The paper presents MuxServe, a system designed to efficiently serve multiple LLMs by leveraging spatial-temporal multiplexing. The key insights behind MuxServe are:
-
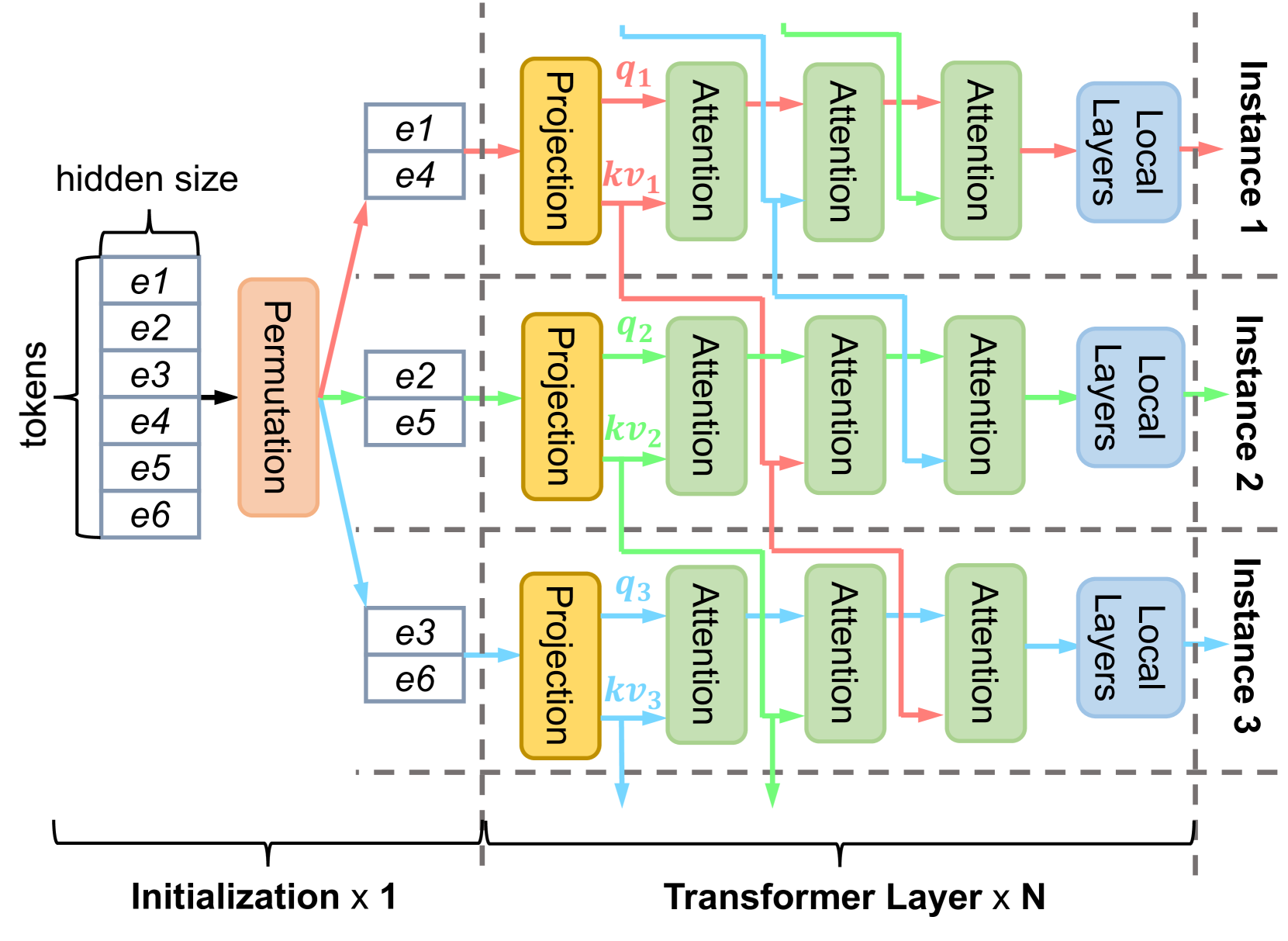
Colocation based on Popularity: MuxServe colocates LLMs with similar popularity to multiplex memory resources effectively.
-
Separating Prefill and Decoding: MuxServe separates the prefill and decoding phases of LLM serving, allowing it to flexibly colocate these phases to multiplex computation resources.
MuxServe formulates the multiplexing problem and proposes a novel placement algorithm and adaptive batch scheduling strategy to optimize colocation and maximize resource utilization. The system also includes a unified resource manager to enable flexible and efficient multiplexing.
Evaluation results show that MuxServe can achieve up to 1.8x higher throughput or process 2.9x more requests within a 99% service-level objective (SLO) attainment.
Critical Analysis
The paper presents a compelling approach to addressing the challenges of efficiently serving multiple LLMs. The insights around colocating LLMs based on popularity and separating the prefill and decoding phases are innovative and well-grounded.
However, the paper does not discuss potential limitations or edge cases that may arise in real-world deployments. For example, the impact of sudden shifts in LLM popularity or the handling of diverse request patterns is not explored. Additionally, the paper does not address the computational and memory overhead associated with the placement algorithm and adaptive batch scheduling.
Further research could investigate the scalability of MuxServe as the number of LLMs and requests continues to grow, as well as the generalizability of the approach to other types of machine learning models beyond LLMs.
Conclusion
The MuxServe system presented in this paper offers a promising solution to the challenge of efficiently serving multiple large language models. By leveraging spatial-temporal multiplexing techniques, the system can significantly improve throughput and response times, making better use of available computing resources.
While the paper demonstrates the effectiveness of the MuxServe approach, further exploration of its limitations and potential extensions could help advance the state of the art in large-scale LLM serving. Overall, this research represents an important step forward in enabling organizations to harness the power of large language models more effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
0
MuxServe: Flexible Multiplexing for Efficient Multiple LLM Serving
Jiangfei Duan, Runyu Lu, Haojie Duanmu, Xiuhong Li, Xingcheng Zhang, Dahua Lin, Ion Stoica, Hao Zhang
Large language models (LLMs) have demonstrated remarkable performance, and organizations are racing to serve LLMs of varying sizes as endpoints for use-cases like chat, programming and search. However, efficiently serving multiple LLMs poses significant challenges for existing approaches due to varying popularity of LLMs. In the paper, we present MuxServe, a flexible spatial-temporal multiplexing system for efficient multiple LLM serving. The key insight behind is to colocate LLMs considering their popularity to multiplex memory resources, and leverage the characteristics of prefill and decoding phases to separate and flexibly colocate them to multiplex computation resources. MuxServe formally formulates the multiplexing problem, and proposes a novel placement algorithm and adaptive batch scheduling strategy to identify optimal colocations and maximize utilization. MuxServe designs a unified resource manager to enable flexible and efficient multiplexing. Evaluation results show that MuxServe can achieves up to $1.8times$ higher throughput or processes $2.9times$ more requests within $99%$ SLO attainment. The code is available at: url{https://github.com/hao-ai-lab/MuxServe}.
Read more6/14/2024

0
ScaleLLM: A Resource-Frugal LLM Serving Framework by Optimizing End-to-End Efficiency
Yuhang Yao, Han Jin, Alay Dilipbhai Shah, Shanshan Han, Zijian Hu, Yide Ran, Dimitris Stripelis, Zhaozhuo Xu, Salman Avestimehr, Chaoyang He
Large language models (LLMs) have surged in popularity and are extensively used in commercial applications, where the efficiency of model serving is crucial for the user experience. Most current research focuses on optimizing individual sub-procedures, e.g. local inference and communication, however, there is no comprehensive framework that provides a holistic system view for optimizing LLM serving in an end-to-end manner. In this work, we conduct a detailed analysis to identify major bottlenecks that impact end-to-end latency in LLM serving systems. Our analysis reveals that a comprehensive LLM serving endpoint must address a series of efficiency bottlenecks that extend beyond LLM inference. We then propose ScaleLLM, an optimized system for resource-efficient LLM serving. Our extensive experiments reveal that with 64 concurrent requests, ScaleLLM achieves a 4.3x speed up over vLLM and outperforms state-of-the-arts with 1.5x higher throughput.
Read more9/12/2024
0
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, Xin Jin
The context window of large language models (LLMs) is rapidly increasing, leading to a huge variance in resource usage between different requests as well as between different phases of the same request. Restricted by static parallelism strategies, existing LLM serving systems cannot efficiently utilize the underlying resources to serve variable-length requests in different phases. To address this problem, we propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances. Our evaluation under diverse real-world datasets shows that LoongServe improves the maximum throughput by up to 3.85$times$ compared to the chunked prefill and 5.81$times$ compared to the prefill-decoding disaggregation.
Read more4/16/2024
🤯
0
Fast Distributed Inference Serving for Large Language Models
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, Xin Jin
Large language models (LLMs) power a new generation of interactive AI applications exemplified by ChatGPT. The interactive nature of these applications demands low latency for LLM inference. Existing LLM serving systems use run-to-completion processing for inference jobs, which suffers from head-of-line blocking and long latency. We present FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize latency with a novel skip-join Multi-Level Feedback Queue scheduler. Based on the new semi-information-agnostic setting of LLM inference, the scheduler leverages the input length information to assign an appropriate initial queue for each arrival job to join. The higher priority queues than the joined queue are skipped to reduce demotions. We design an efficient GPU memory management mechanism that proactively offloads and uploads intermediate state between GPU memory and host memory for LLM inference. We build a system prototype of FastServe and experimental results show that compared to the state-of-the-art solution vLLM, FastServe improves the throughput by up to 31.4x and 17.9x under the same average and tail latency requirements, respectively.
Read more9/26/2024