The Mysterious Case of Neuron 1512: Injectable Realignment Architectures Reveal Internal Characteristics of Meta's Llama 2 Model

0

Sign in to get full access
Overview
- Explores the internal characteristics of Meta's Llama 2 language model through a technique called "injectable realignment architectures"
- Focuses on a peculiar neuron, Neuron 1512, which exhibits unique behavior
- Aims to uncover insights about the model's inner workings and potential biases
Plain English Explanation
The paper investigates the inner workings of Meta's Llama 2 language model, a powerful AI system used for tasks like natural language processing. The researchers used a technique called "injectable realignment architectures" to delve deeper into the model's behavior.
One particular neuron, known as Neuron 1512, caught their attention due to its unique characteristics. By analyzing this neuron, the researchers hoped to uncover insights about the model's underlying structure and potential biases.
Language models like Llama 2 are complex systems, and understanding their inner workings can be challenging. The researchers' goal was to shed light on how these models process and generate language, which could inform future model development and help address potential issues.
Technical Explanation
The paper presents a method called "injectable realignment architectures" to probe the internal characteristics of the Llama 2 model. This technique involves modifying the model's architecture by injecting additional layers or components, which can then be used to analyze the model's behavior in response to specific inputs or tasks.
The researchers focused their analysis on Neuron 1512, a particular neuron within the Llama 2 model that exhibited unusual behavior. By studying this neuron's activation patterns and responses to various inputs, the researchers aimed to uncover insights about the model's underlying structure and potential biases.
The paper provides detailed technical descriptions of the experimental setup, the injectable realignment architecture, and the analysis of Neuron 1512. The findings suggest that this neuron may play a significant role in the model's language processing capabilities and could be linked to specific biases or idiosyncrasies in the model's output.
Critical Analysis
The paper presents a novel and intriguing approach to understanding the internal workings of large language models like Llama 2. The injectable realignment architecture technique allows for targeted probing of the model's behavior, which could be a valuable tool for model developers and researchers.
However, the paper acknowledges the limitations of this approach, noting that the insights gained may be specific to the particular neuron studied and may not necessarily generalize to the model as a whole. Additionally, the paper does not address potential ethical considerations or societal implications of the research.
Further research could explore the applicability of this technique to other language models, investigate the presence and nature of biases in these models, and consider the broader implications of understanding their inner workings.
Conclusion
The paper presents a novel approach to studying the internal characteristics of the Llama 2 language model, with a focus on the peculiar behavior of Neuron 1512. The findings offer insights into the model's underlying structure and potential biases, which could inform future model development and help address important challenges in the field of natural language processing.
While the research is technical in nature, the authors have made an effort to present the key ideas and findings in a clear and accessible manner. The paper serves as a valuable contribution to the ongoing efforts to understand and improve large language models, with potential implications for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Mysterious Case of Neuron 1512: Injectable Realignment Architectures Reveal Internal Characteristics of Meta's Llama 2 Model
Brenden Smith, Dallin Baker, Clayton Chase, Myles Barney, Kaden Parker, Makenna Allred, Peter Hu, Alex Evans, Nancy Fulda
Large Language Models (LLMs) have an unrivaled and invaluable ability to align their output to a diverse range of human preferences, by mirroring them in the text they generate. The internal characteristics of such models, however, remain largely opaque. This work presents the Injectable Realignment Model (IRM) as a novel approach to language model interpretability and explainability. Inspired by earlier work on Neural Programming Interfaces, we construct and train a small network -- the IRM -- to induce emotion-based alignments within a 7B parameter LLM architecture. The IRM outputs are injected via layerwise addition at various points during the LLM's forward pass, thus modulating its behavior without changing the weights of the original model. This isolates the alignment behavior from the complex mechanisms of the transformer model. Analysis of the trained IRM's outputs reveals a curious pattern. Across more than 24 training runs and multiple alignment datasets, patterns of IRM activations align themselves in striations associated with a neuron's index within each transformer layer, rather than being associated with the layers themselves. Further, a single neuron index (1512) is strongly correlated with all tested alignments. This result, although initially counterintuitive, is directly attributable to design choices present within almost all commercially available transformer architectures, and highlights a potential weak point in Meta's pretrained Llama 2 models. It also demonstrates the value of the IRM architecture for language model analysis and interpretability. Our code and datasets are available at https://github.com/DRAGNLabs/injectable-alignment-model
Read more7/8/2024

0
Transformer Alignment in Large Language Models
Murdock Aubry, Haoming Meng, Anton Sugolov, Vardan Papyan
Large Language Models (LLMs) have made significant strides in natural language processing, and a precise understanding of the internal mechanisms driving their success is essential. We regard LLMs as transforming embeddings via a discrete, coupled, nonlinear, dynamical system in high dimensions. This perspective motivates tracing the trajectories of individual tokens as they pass through transformer blocks, and linearizing the system along these trajectories through their Jacobian matrices. In our analysis of 38 openly available LLMs, we uncover the alignment of top left and right singular vectors of Residual Jacobians, as well as the emergence of linearity and layer-wise exponential growth. Notably, we discover that increased alignment $textit{positively correlates}$ with model performance. Metrics evaluated post-training show significant improvement in comparison to measurements made with randomly initialized weights, highlighting the significant effects of training in transformers. These findings reveal a remarkable level of regularity that has previously been overlooked, reinforcing the dynamical interpretation and paving the way for deeper understanding and optimization of LLM architectures.
Read more7/11/2024
0
Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
Badr AlKhamissi, Greta Tuckute, Antoine Bosselut, Martin Schrimpf
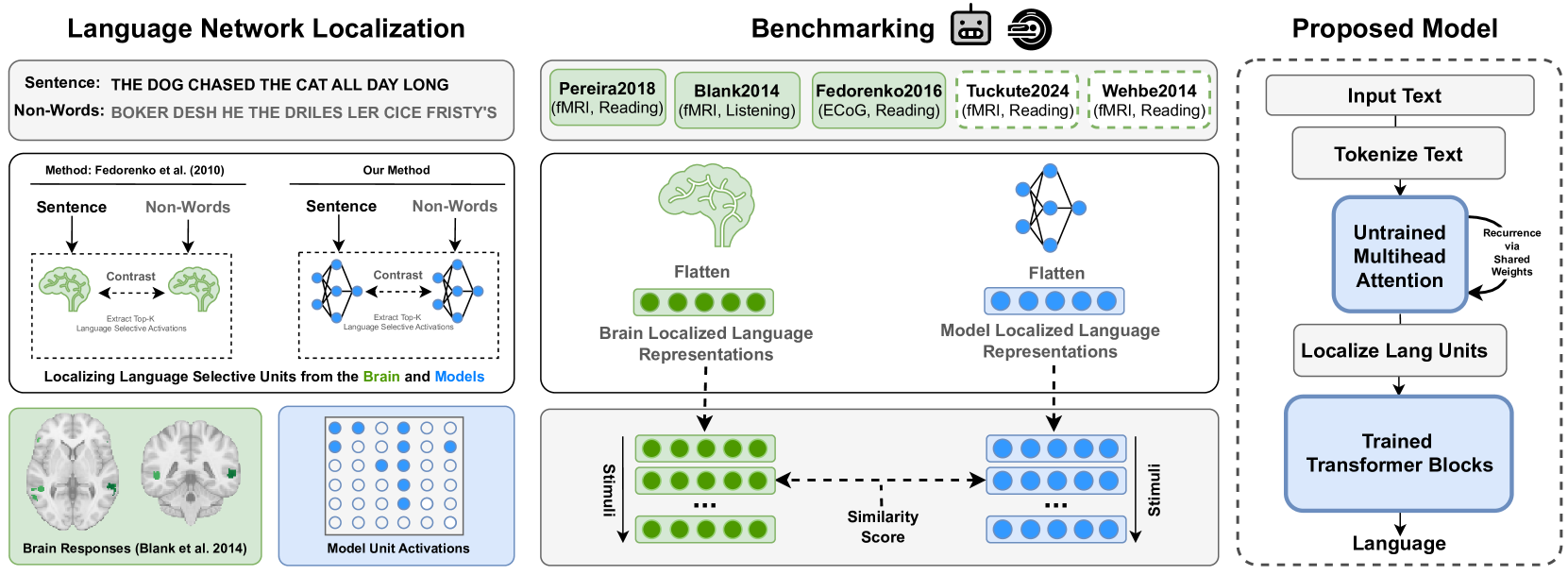
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
Read more6/24/2024
💬
4
Creativity Has Left the Chat: The Price of Debiasing Language Models
Behnam Mohammadi
Large Language Models (LLMs) have revolutionized natural language processing but can exhibit biases and may generate toxic content. While alignment techniques like Reinforcement Learning from Human Feedback (RLHF) reduce these issues, their impact on creativity, defined as syntactic and semantic diversity, remains unexplored. We investigate the unintended consequences of RLHF on the creativity of LLMs through three experiments focusing on the Llama-2 series. Our findings reveal that aligned models exhibit lower entropy in token predictions, form distinct clusters in the embedding space, and gravitate towards attractor states, indicating limited output diversity. Our findings have significant implications for marketers who rely on LLMs for creative tasks such as copywriting, ad creation, and customer persona generation. The trade-off between consistency and creativity in aligned models should be carefully considered when selecting the appropriate model for a given application. We also discuss the importance of prompt engineering in harnessing the creative potential of base models.
Read more6/11/2024