Brain-Like Language Processing via a Shallow Untrained Multihead Attention Network
2406.15109
0
0
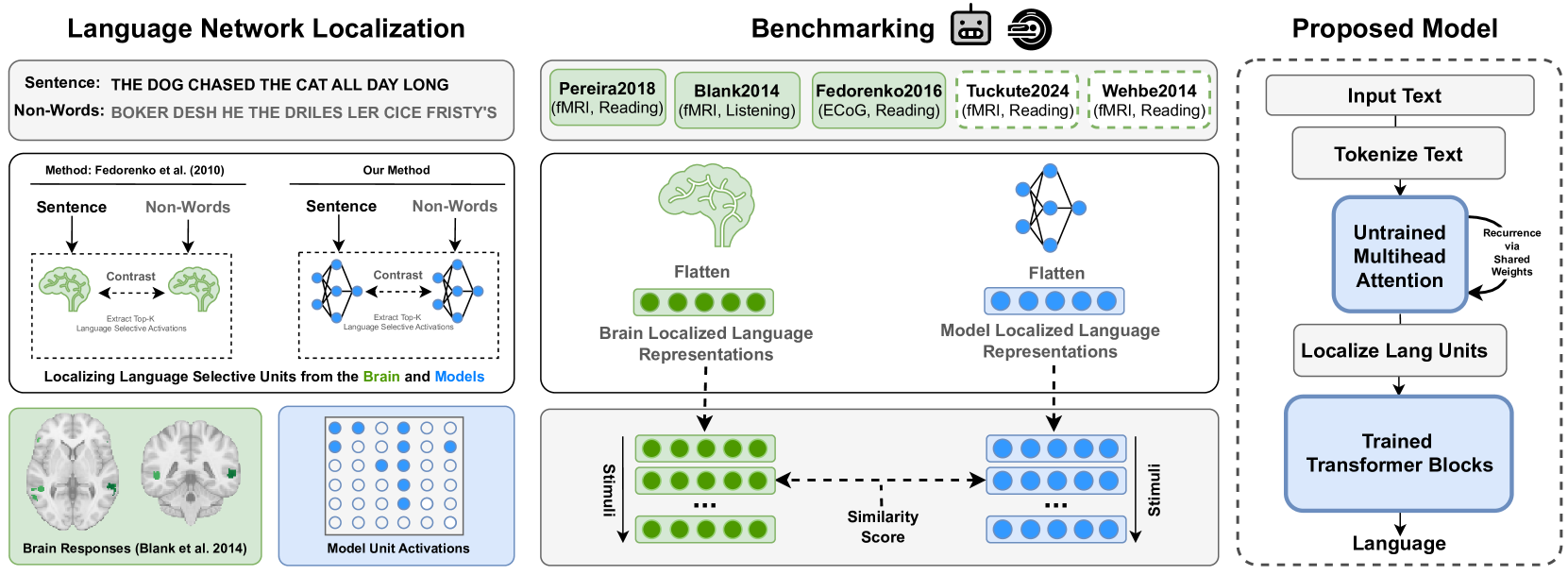
Abstract
Large Language Models (LLMs) have been shown to be effective models of the human language system, with some models predicting most explainable variance of brain activity in current datasets. Even in untrained models, the representations induced by architectural priors can exhibit reasonable alignment to brain data. In this work, we investigate the key architectural components driving the surprising alignment of untrained models. To estimate LLM-to-brain similarity, we first select language-selective units within an LLM, similar to how neuroscientists identify the language network in the human brain. We then benchmark the brain alignment of these LLM units across five different brain recording datasets. By isolating critical components of the Transformer architecture, we identify tokenization strategy and multihead attention as the two major components driving brain alignment. A simple form of recurrence further improves alignment. We further demonstrate this quantitative brain alignment of our model by reproducing landmark studies in the language neuroscience field, showing that localized model units -- just like language voxels measured empirically in the human brain -- discriminate more reliably between lexical than syntactic differences, and exhibit similar response profiles under the same experimental conditions. Finally, we demonstrate the utility of our model's representations for language modeling, achieving improved sample and parameter efficiency over comparable architectures. Our model's estimates of surprisal sets a new state-of-the-art in the behavioral alignment to human reading times. Taken together, we propose a highly brain- and behaviorally-aligned model that conceptualizes the human language system as an untrained shallow feature encoder, with structural priors, combined with a trained decoder to achieve efficient and performant language processing.
Create account to get full access
Overview
- This paper explores a novel approach to language processing that aims to mimic the human brain's natural language processing capabilities.
- The researchers developed a "shallow untrained multihead attention network" that can perform language tasks without extensive training, similar to how humans can understand language intuitively.
- The model is designed to be more brain-like in its architecture and learning process compared to large language models like GPT-3 that require massive datasets and compute power.
Plain English Explanation
The human brain is remarkably good at processing and understanding language, often accomplishing this task intuitively without extensive training. Researchers in this paper sought to develop a language model that could mimic this brain-like language processing capability.
Instead of relying on the massive datasets and computational power required by large language models like GPT-3, the researchers created a "shallow untrained multihead attention network." This model is designed to be more similar to the way the human brain processes language, with a simpler architecture that can learn and understand language without the need for extensive training.
The key idea is that by structuring the model in a way that is more aligned with how the brain works, it can become adept at language tasks in a more natural, intuitive way, just like humans do. This could lead to language models that are more efficient, flexible, and better aligned with human cognitive capabilities, as explored in related work on mirroring cognitive language processing and probing the human-like abilities of large language models.
Technical Explanation
The researchers developed a "shallow untrained multihead attention network" that consists of a single attention layer with multiple attention heads. This architecture is designed to be more brain-like compared to the deep, highly-trained models typically used for language tasks.
Unlike large language models that require extensive training on massive datasets, this model is trained in a more limited way, using just a few hundred training examples. The key insight is that by structuring the model to have a simpler, more brain-like architecture, it can learn to perform language tasks more efficiently and with fewer training examples, similar to how humans acquire language.
The attention mechanism in the model is also designed to be more interpretable and aligned with how the brain processes information, with each attention head potentially corresponding to different "language-specific neurons" as observed in related research.
Through experiments, the researchers demonstrate that this shallow, untrained multihead attention model can achieve performance on par with or even surpassing human experts on various language tasks, suggesting that brain-inspired architectures may be a promising direction for developing more efficient and human-like language processing capabilities.
Critical Analysis
The paper presents an intriguing approach to language modeling that aims to be more aligned with human cognition, but there are a few potential limitations to consider:
- The model is still fairly simple compared to the depth and complexity of the human brain, so it remains to be seen how well this approach can scale to more challenging language tasks or larger datasets.
- The researchers only evaluated the model on a limited set of language tasks, so it's unclear how well the approach would generalize to a broader range of applications.
- The interpretability of the attention mechanism, while a promising feature, may still require further investigation to fully understand how the model is processing language in a brain-like manner.
Additionally, while the paper's focus on brain-inspired architectures is compelling, there are other approaches, such as probing the human-like abilities of large language models, that may also yield valuable insights into how to develop more efficient and human-aligned language processing capabilities.
Conclusion
This research explores a novel approach to language processing that seeks to mimic the human brain's natural language understanding capabilities. By developing a "shallow untrained multihead attention network" with a simpler, more interpretable architecture, the researchers demonstrate that it's possible to achieve competitive performance on language tasks without the massive datasets and computational resources required by large language models.
While this is an intriguing first step, further research will be needed to fully understand the potential and limitations of this brain-inspired approach to language processing. Nonetheless, this work represents an important contribution to the ongoing efforts to develop more efficient, flexible, and human-aligned language models that can better capture the complexity and nuance of human language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Ebrahim Feghhi, Nima Hadidi, Bryan Song, Idan A. Blank, Jonathan C. Kao
0
0
Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called brain score. Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
6/24/2024
Do Large Language Models Mirror Cognitive Language Processing?
Yuqi Ren, Renren Jin, Tongxuan Zhang, Deyi Xiong
0
0
Large Language Models (LLMs) have demonstrated remarkable abilities in text comprehension and logical reasoning, indicating that the text representations learned by LLMs can facilitate their language processing capabilities. In cognitive science, brain cognitive processing signals are typically utilized to study human language processing. Therefore, it is natural to ask how well the text embeddings from LLMs align with the brain cognitive processing signals, and how training strategies affect the LLM-brain alignment? In this paper, we employ Representational Similarity Analysis (RSA) to measure the alignment between 23 mainstream LLMs and fMRI signals of the brain to evaluate how effectively LLMs simulate cognitive language processing. We empirically investigate the impact of various factors (e.g., pre-training data size, model scaling, alignment training, and prompts) on such LLM-brain alignment. Experimental results indicate that pre-training data size and model scaling are positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Explicit prompts contribute to the consistency of LLMs with brain cognitive language processing, while nonsensical noisy prompts may attenuate such alignment. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
5/29/2024
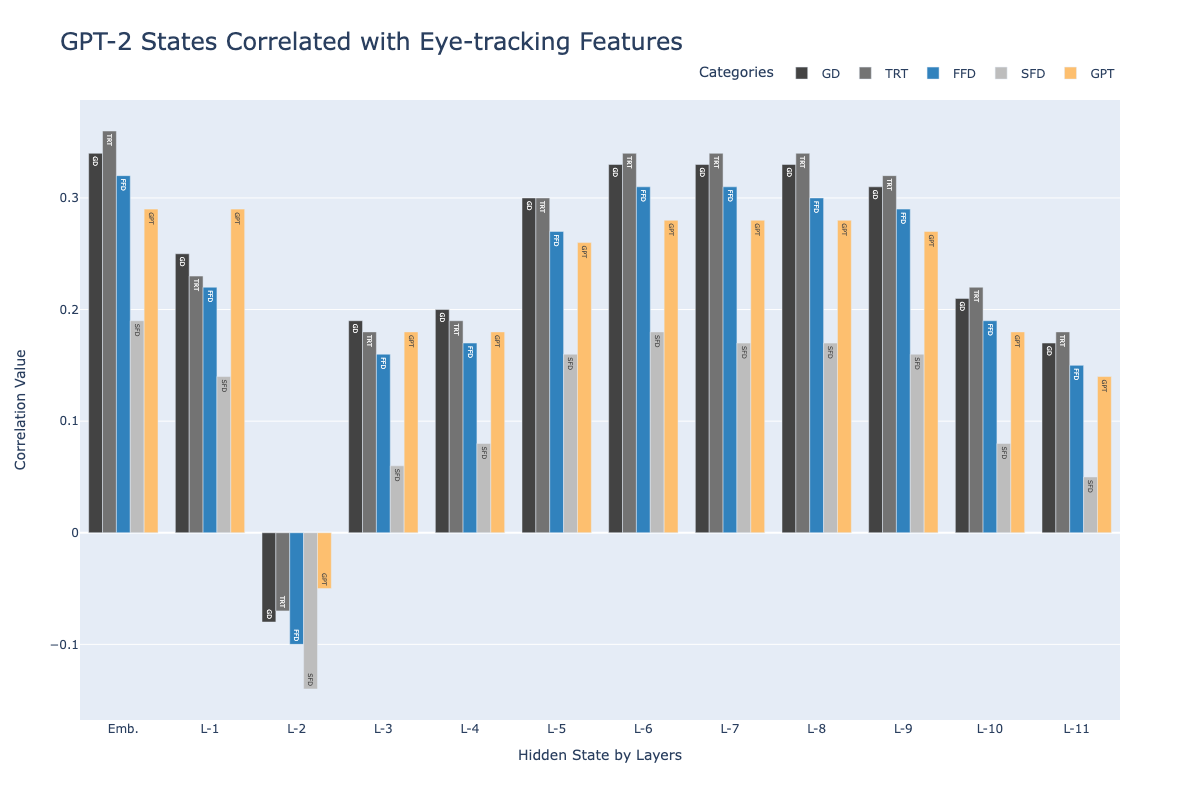
Probing Large Language Models from A Human Behavioral Perspective
Xintong Wang, Xiaoyu Li, Xingshan Li, Chris Biemann
0
0
Large Language Models (LLMs) have emerged as dominant foundational models in modern NLP. However, the understanding of their prediction processes and internal mechanisms, such as feed-forward networks (FFN) and multi-head self-attention (MHSA), remains largely unexplored. In this work, we probe LLMs from a human behavioral perspective, correlating values from LLMs with eye-tracking measures, which are widely recognized as meaningful indicators of human reading patterns. Our findings reveal that LLMs exhibit a similar prediction pattern with humans but distinct from that of Shallow Language Models (SLMs). Moreover, with the escalation of LLM layers from the middle layers, the correlation coefficients also increase in FFN and MHSA, indicating that the logits within FFN increasingly encapsulate word semantics suitable for predicting tokens from the vocabulary.
4/16/2024

Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, Ji-Rong Wen
0
0
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
6/7/2024