NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Prompts
2405.04520
0
0
🚀
Abstract
Large language models (LLMs) have manifested strong ability to generate codes for productive activities. However, current benchmarks for code synthesis, such as HumanEval, MBPP, and DS-1000, are predominantly oriented towards introductory tasks on algorithm and data science, insufficiently satisfying challenging requirements prevalent in real-world coding. To fill this gap, we propose NaturalCodeBench (NCB), a challenging code benchmark designed to mirror the complexity and variety of scenarios in real coding tasks. NCB comprises 402 high-quality problems in Python and Java, meticulously selected from natural user queries from online coding services, covering 6 different domains. Noting the extraordinary difficulty in creating testing cases for real-world queries, we also introduce a semi-automated pipeline to enhance the efficiency of test case construction. Comparing with manual solutions, it achieves an efficiency increase of more than 4 times. Our systematic experiments on 39 LLMs find that performance gaps on NCB between models with close HumanEval scores could still be significant, indicating a lack of focus on practical code synthesis scenarios or over-specified optimization on HumanEval. On the other hand, even the best-performing GPT-4 is still far from satisfying on NCB. The evaluation toolkit and development set are available at https://github.com/THUDM/NaturalCodeBench.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Large language models (LLMs) have shown strong capabilities in generating code for various tasks.
- However, current benchmarks for code synthesis, such as HumanEval, MBPP, and DS-1000, are primarily focused on introductory algorithm and data science problems, which may not adequately represent the complexity and variety of real-world coding scenarios.
- To address this gap, the researchers propose a new benchmark called NaturalCodeBench (NCB) that aims to reflect the challenges and diversity of real-world coding tasks.
Plain English Explanation
Large language models (LLMs) are advanced artificial intelligence systems that can generate human-like text, including code. While current benchmarks for testing LLMs' code generation abilities, such as HumanEval, MBPP, and DS-1000, are useful for evaluating basic coding skills, they don't capture the full complexity and diversity of real-world coding tasks that developers face.
To address this, the researchers created a new benchmark called NaturalCodeBench (NCB) that includes 402 high-quality coding problems in Python and Java, selected from actual user queries on online coding services. These problems cover a wide range of domains, from data analysis to web development, and are designed to be more representative of the challenges that professional developers encounter in their daily work.
Additionally, the researchers developed a semi-automated pipeline to help efficiently create test cases for these real-world coding problems, which can be a time-consuming and challenging task. This pipeline allows them to generate test cases more quickly and reliably than manual methods.
By evaluating a variety of LLMs on this new NCB benchmark, the researchers found that even the best-performing models, like GPT-4, still struggle to solve many of the problems, indicating that there is still significant room for improvement in developing LLMs that can truly excel at practical, real-world coding tasks.
Technical Explanation
The researchers propose a new benchmark called NaturalCodeBench (NCB) to better evaluate the code synthesis capabilities of large language models (LLMs). Unlike existing benchmarks like HumanEval, MBPP, and DS-1000, which focus on introductory algorithm and data science problems, NCB comprises 402 high-quality coding problems in Python and Java that are drawn from real-world user queries on online coding services.
These problems cover a wide range of domains, including data analysis, web development, and problem-solving, and are designed to be more representative of the complex and diverse scenarios that professional developers encounter in their work. To enhance the efficiency of test case construction for these real-world queries, the researchers also introduce a semi-automated pipeline, which they show can achieve a more than 4-fold increase in efficiency compared to manual solutions.
The researchers evaluate 39 different LLMs on the NCB benchmark and find that even the best-performing model, GPT-4, still struggles to solve many of the problems. This suggests that current LLMs, while adept at generating code for basic tasks, are not yet fully equipped to handle the complexity and variety of real-world coding scenarios. The researchers also observe that performance gaps between models with similar scores on the HumanEval benchmark can be significant, indicating that the HumanEval benchmark may not be sufficient for capturing the full range of practical code synthesis capabilities.
The NCB evaluation toolkit and development set are made publicly available at https://github.com/THUDM/NaturalCodeBench, allowing other researchers and developers to further explore and improve the code generation abilities of LLMs.
Critical Analysis
The researchers have made a valuable contribution by developing the NaturalCodeBench (NCB), a more challenging and representative benchmark for evaluating the code synthesis capabilities of large language models (LLMs). By drawing from real-world user queries, NCB reflects the complexity and diversity of coding tasks that professional developers face, going beyond the introductory problems found in existing benchmarks like HumanEval and MBPP.
However, the researchers acknowledge the significant challenge in creating appropriate test cases for these real-world queries, which can be time-consuming and error-prone. While their semi-automated pipeline helps to improve efficiency, it is unclear how the quality and representativeness of the generated test cases compare to manually curated ones.
Additionally, the researchers' systematic experiments on 39 LLMs, including the cutting-edge GPT-4, reveal that even the best-performing models still struggle to solve many of the problems in the NCB benchmark. This suggests that current LLMs, while adept at generating code for basic tasks, are not yet ready to handle the full complexity and diversity of real-world coding scenarios.
Further research is needed to understand the specific limitations of LLMs in this domain and to develop more robust and versatile code synthesis capabilities. Potential areas for exploration include improving the quality of prompts used for code generation, enhancing the models' ability to understand and reason about code, and generating more comprehensive and scalable test cases.
Conclusion
The NaturalCodeBench (NCB) proposed by the researchers represents a significant step forward in benchmarking the code synthesis capabilities of large language models (LLMs). By incorporating real-world coding problems that cover a wide range of domains and complexity levels, NCB provides a more comprehensive and representative evaluation of LLMs' practical abilities, going beyond the limitations of existing benchmarks.
The researchers' findings suggest that even the most advanced LLMs, such as GPT-4, still have significant room for improvement when it comes to handling the full range of coding challenges that professional developers face. This underscores the need for continued research and development to enhance the code synthesis capabilities of LLMs, which could have far-reaching implications for fields like software engineering, data analysis, and scientific computing.
The open-source availability of the NCB evaluation toolkit and development set will enable other researchers and developers to further explore and push the boundaries of LLM-based code generation, ultimately contributing to the advancement of this critical technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
The RealHumanEval: Evaluating Large Language Models' Abilities to Support Programmers
Hussein Mozannar, Valerie Chen, Mohammed Alsobay, Subhro Das, Sebastian Zhao, Dennis Wei, Manish Nagireddy, Prasanna Sattigeri, Ameet Talwalkar, David Sontag
0
0
Evaluation of large language models (LLMs) for code has primarily relied on static benchmarks, including HumanEval (Chen et al., 2021), which measure the ability of LLMs to generate complete code that passes unit tests. As LLMs are increasingly used as programmer assistants, we study whether gains on existing benchmarks translate to gains in programmer productivity when coding with LLMs, including time spent coding. In addition to static benchmarks, we investigate the utility of preference metrics that might be used as proxies to measure LLM helpfulness, such as code acceptance or copy rates. To do so, we introduce RealHumanEval, a web interface to measure the ability of LLMs to assist programmers, through either autocomplete or chat support. We conducted a user study (N=213) using RealHumanEval in which users interacted with six LLMs of varying base model performance. Despite static benchmarks not incorporating humans-in-the-loop, we find that improvements in benchmark performance lead to increased programmer productivity; however gaps in benchmark versus human performance are not proportional -- a trend that holds across both forms of LLM support. In contrast, we find that programmer preferences do not correlate with their actual performance, motivating the need for better, human-centric proxy signals. We also open-source RealHumanEval to enable human-centric evaluation of new models and the study data to facilitate efforts to improve code models.
4/4/2024
🏅
PythonSaga: Redefining the Benchmark to Evaluate Code Generating LLM
Ankit Yadav, Mayank Singh
0
0
Driven by the surge in code generation using large language models (LLMs), numerous benchmarks have emerged to evaluate these LLMs capabilities. We conducted a large-scale human evaluation of HumanEval and MBPP, two popular benchmarks for Python code generation, analyzing their diversity and difficulty. Our findings unveil a critical bias towards a limited set of programming concepts, neglecting most of the other concepts entirely. Furthermore, we uncover a worrying prevalence of easy tasks, potentially inflating model performance estimations. To address these limitations, we propose a novel benchmark, PythonSaga, featuring 185 hand-crafted prompts on a balanced representation of 38 programming concepts across diverse difficulty levels.
4/29/2024
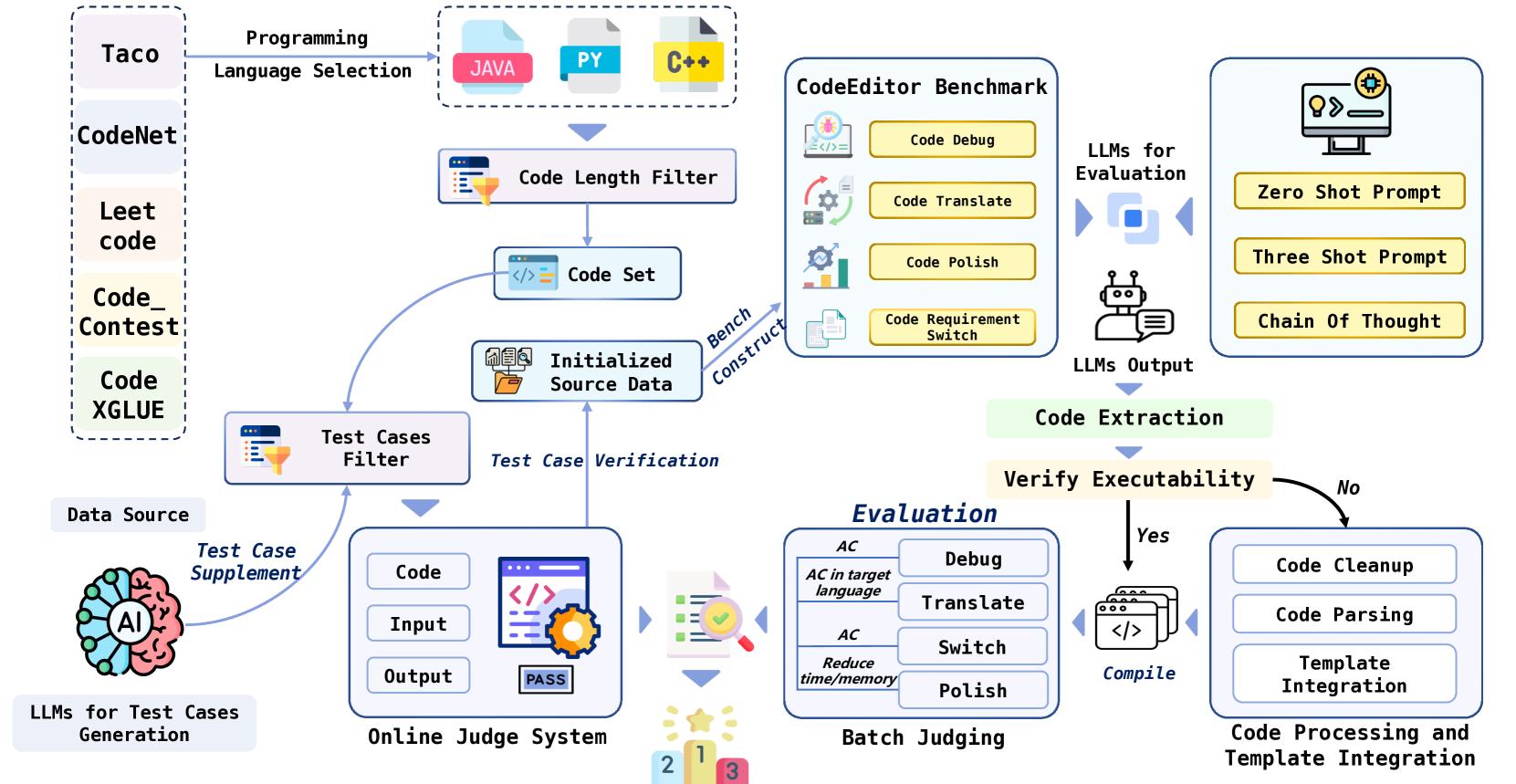
CodeEditorBench: Evaluating Code Editing Capability of Large Language Models
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, Jie Fu
0
0
Large Language Models (LLMs) for code are rapidly evolving, with code editing emerging as a critical capability. We introduce CodeEditorBench, an evaluation framework designed to rigorously assess the performance of LLMs in code editing tasks, including debugging, translating, polishing, and requirement switching. Unlike existing benchmarks focusing solely on code generation, CodeEditorBench emphasizes real-world scenarios and practical aspects of software development. We curate diverse coding challenges and scenarios from five sources, covering various programming languages, complexity levels, and editing tasks. Evaluation of 19 LLMs reveals that closed-source models (particularly Gemini-Ultra and GPT-4), outperform open-source models in CodeEditorBench, highlighting differences in model performance based on problem types and prompt sensitivities. CodeEditorBench aims to catalyze advancements in LLMs by providing a robust platform for assessing code editing capabilities. We will release all prompts and datasets to enable the community to expand the dataset and benchmark emerging LLMs. By introducing CodeEditorBench, we contribute to the advancement of LLMs in code editing and provide a valuable resource for researchers and practitioners.
4/9/2024
🛸
Quality Assessment of Prompts Used in Code Generation
Mohammed Latif Siddiq, Simantika Dristi, Joy Saha, Joanna C. S. Santos
0
0
Large Language Models (LLMs) are gaining popularity among software engineers. A crucial aspect of developing effective code-generation LLMs is to evaluate these models using a robust benchmark. Evaluation benchmarks with quality issues can provide a false sense of performance. In this work, we conduct the first-of-its-kind study of the quality of prompts within benchmarks used to compare the performance of different code generation models. To conduct this study, we analyzed 3,566 prompts from 9 code generation benchmarks to identify quality issues in them. We also investigated whether fixing the identified quality issues in the benchmarks' prompts affects a model's performance. We also studied memorization issues of the evaluation dataset, which can put into question a benchmark's trustworthiness. We found that code generation evaluation benchmarks mainly focused on Python and coding exercises and had very limited contextual dependencies to challenge the model. These datasets and the developers' prompts suffer from quality issues like spelling and grammatical errors, unclear sentences to express developers' intent, and not using proper documentation style. Fixing all these issues in the benchmarks can lead to a better performance for Python code generation, but not a significant improvement was observed for Java code generation. We also found evidence that GPT-3.5-Turbo and CodeGen-2.5 models possibly have data contamination issues.
4/17/2024