Naturalistic Music Decoding from EEG Data via Latent Diffusion Models
2405.09062
0
0

Abstract
In this article, we explore the potential of using latent diffusion models, a family of powerful generative models, for the task of reconstructing naturalistic music from electroencephalogram (EEG) recordings. Unlike simpler music with limited timbres, such as MIDI-generated tunes or monophonic pieces, the focus here is on intricate music featuring a diverse array of instruments, voices, and effects, rich in harmonics and timbre. This study represents an initial foray into achieving general music reconstruction of high-quality using non-invasive EEG data, employing an end-to-end training approach directly on raw data without the need for manual pre-processing and channel selection. We train our models on the public NMED-T dataset and perform quantitative evaluation proposing neural embedding-based metrics. We additionally perform song classification based on the generated tracks. Our work contributes to the ongoing research in neural decoding and brain-computer interfaces, offering insights into the feasibility of using EEG data for complex auditory information reconstruction.
Create account to get full access
Overview
- The paper explores a novel approach to decoding naturalistic music from electroencephalography (EEG) data using latent diffusion models.
- The researchers developed a system that can reconstruct audio waveforms from neural activity recorded during listening to natural music.
- This task is challenging due to the complex, dynamic nature of music and the high-dimensional neural data.
- The proposed method involves using a diffusion probabilistic model to map EEG features to a latent music representation, which is then used to generate the audio waveform.
Plain English Explanation
The paper describes a new way to decode or "read" people's brain activity while they listen to music and then reconstruct the original music they heard. This is done using a type of machine learning model called a "latent diffusion model."
The key idea is that the model learns to map the complex patterns in the brain's electrical signals (recorded using EEG) to a more compact, hidden ("latent") representation of the music. From this latent representation, the model can then generate the actual audio waveform of the music that the person was listening to.
This is a challenging task because music is very complex, with constantly changing pitch, rhythm, and other features. And the brain's electrical signals measured by EEG are also very high-dimensional and difficult to interpret. But the researchers show that their latent diffusion model approach can effectively bridge the gap between the neural data and the music, allowing them to reconstruct the music from the brain activity.
Technical Explanation
The paper proposes a novel framework for decoding natural music from electroencephalography (EEG) data using a latent diffusion model. The key components include:
- EEG Feature Extraction: The researchers first extract relevant features from the raw EEG recordings, such as power spectral density and event-related potentials.
- Latent Diffusion Model: This is a type of generative model that learns to map the EEG features to a compressed, "latent" representation of the music. It does this by learning to add and remove noise from the latent space in a controlled way, which allows it to generate new music samples.
- Audio Waveform Generation: The latent representation is then used to generate the final audio waveform of the music, using an additional neural network component.
The model is trained end-to-end on a dataset of people listening to natural music while their EEG is recorded. The researchers show that this approach can successfully reconstruct the listened music, outperforming previous methods that used simpler models or hand-engineered features.
Critical Analysis
The paper presents a promising approach for decoding naturalistic music from EEG data, but there are some potential limitations and areas for further research:
- The dataset used is relatively small, with only 10 participants. Scaling up to larger and more diverse datasets could be challenging and impact performance.
- The evaluation is focused on objective measures of reconstruction quality, but does not assess the subjective perceptual fidelity of the generated audio. Listening tests would be important to fully validate the approach.
- The model is limited to reconstructing the music the participants listened to, and cannot generate completely novel music. Extending the model to open-ended music generation could be an interesting direction.
- The underlying mechanisms by which the brain encodes music information are still not fully understood. Further neuroscientific insights could help refine the model architecture and features.
Despite these potential limitations, the paper represents an important step in the field of EEG-based music decoding and reconstruction, demonstrating the potential of latent diffusion models to bridge the gap between neural signals and complex audio representations.
Conclusion
This paper presents a novel approach to decoding naturalistic music from EEG data using latent diffusion models. The researchers developed a system that can successfully reconstruct audio waveforms from neural activity recorded during listening to natural music.
This work advances the state-of-the-art in EEG-based music decoding and has potential applications in brain-computer interfaces, music therapy, and the study of how the brain processes music. While there are some limitations that warrant further research, the paper represents an important step forward in our understanding of how the brain encodes and represents complex auditory information.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

R&B -- Rhythm and Brain: Cross-subject Decoding of Music from Human Brain Activity
Matteo Ferrante, Matteo Ciferri, Nicola Toschi
0
0
Music is a universal phenomenon that profoundly influences human experiences across cultures. This study investigates whether music can be decoded from human brain activity measured with functional MRI (fMRI) during its perception. Leveraging recent advancements in extensive datasets and pre-trained computational models, we construct mappings between neural data and latent representations of musical stimuli. Our approach integrates functional and anatomical alignment techniques to facilitate cross-subject decoding, addressing the challenges posed by the low temporal resolution and signal-to-noise ratio (SNR) in fMRI data. Starting from the GTZan fMRI dataset, where five participants listened to 540 musical stimuli from 10 different genres while their brain activity was recorded, we used the CLAP (Contrastive Language-Audio Pretraining) model to extract latent representations of the musical stimuli and developed voxel-wise encoding models to identify brain regions responsive to these stimuli. By applying a threshold to the association between predicted and actual brain activity, we identified specific regions of interest (ROIs) which can be interpreted as key players in music processing. Our decoding pipeline, primarily retrieval-based, employs a linear map to project brain activity to the corresponding CLAP features. This enables us to predict and retrieve the musical stimuli most similar to those that originated the fMRI data. Our results demonstrate state-of-the-art identification accuracy, with our methods significantly outperforming existing approaches. Our findings suggest that neural-based music retrieval systems could enable personalized recommendations and therapeutic applications. Future work could use higher temporal resolution neuroimaging and generative models to improve decoding accuracy and explore the neural underpinnings of music perception and emotion.
6/26/2024

Long-form music generation with latent diffusion
Zach Evans, Julian D. Parker, CJ Carr, Zack Zukowski, Josiah Taylor, Jordi Pons
0
0
Audio-based generative models for music have seen great strides recently, but so far have not managed to produce full-length music tracks with coherent musical structure. We show that by training a generative model on long temporal contexts it is possible to produce long-form music of up to 4m45s. Our model consists of a diffusion-transformer operating on a highly downsampled continuous latent representation (latent rate of 21.5Hz). It obtains state-of-the-art generations according to metrics on audio quality and prompt alignment, and subjective tests reveal that it produces full-length music with coherent structure.
4/17/2024
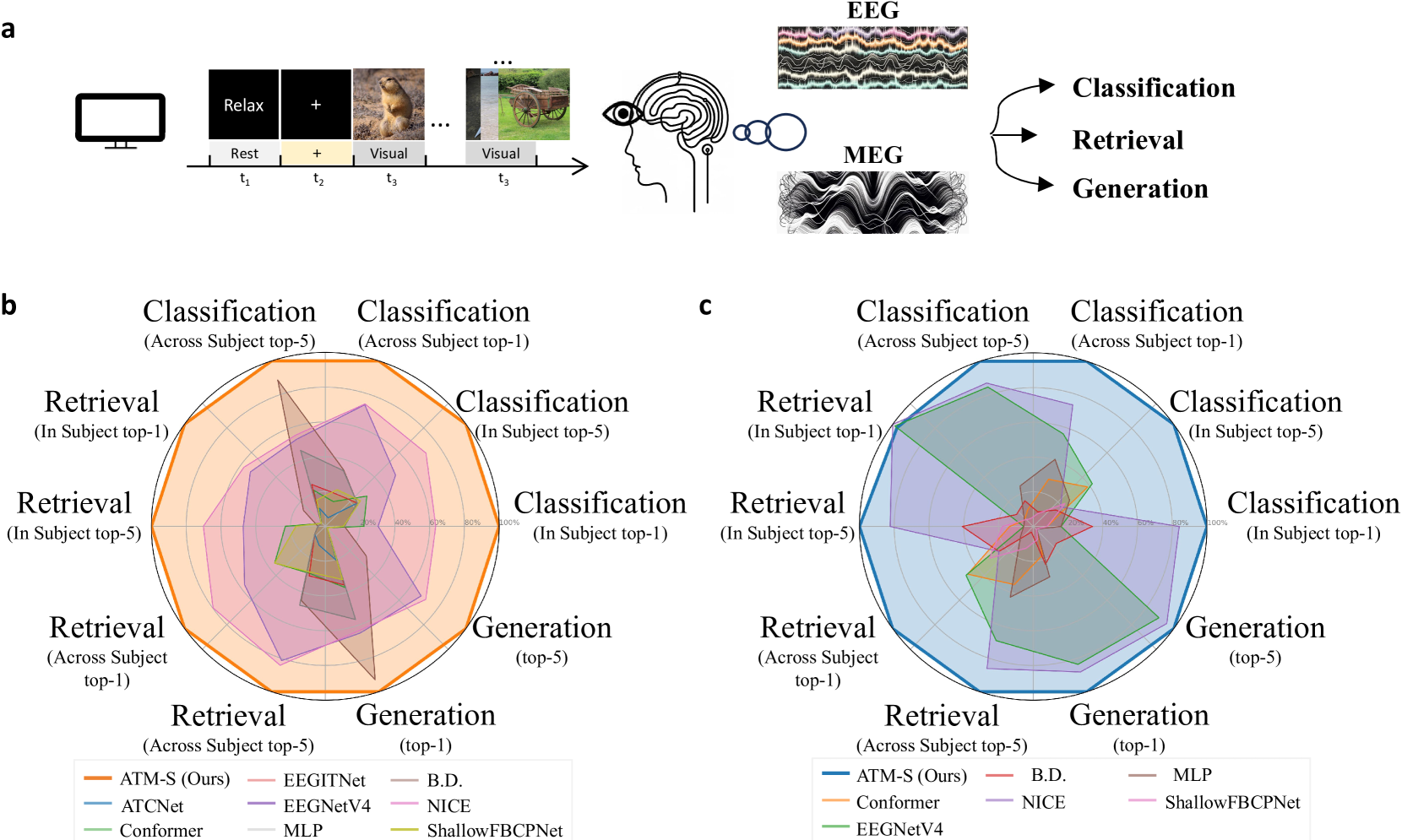
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Dongyang Li, Chen Wei, Shiying Li, Jiachen Zou, Quanying Liu
0
0
How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
4/8/2024
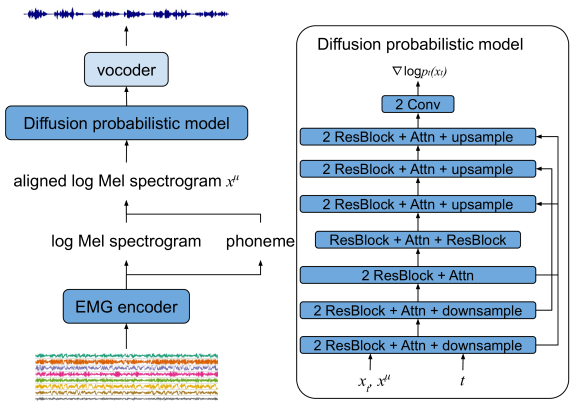
Diff-ETS: Learning a Diffusion Probabilistic Model for Electromyography-to-Speech Conversion
Zhao Ren, Kevin Scheck, Qinhan Hou, Stefano van Gogh, Michael Wand, Tanja Schultz
0
0
Electromyography-to-Speech (ETS) conversion has demonstrated its potential for silent speech interfaces by generating audible speech from Electromyography (EMG) signals during silent articulations. ETS models usually consist of an EMG encoder which converts EMG signals to acoustic speech features, and a vocoder which then synthesises the speech signals. Due to an inadequate amount of available data and noisy signals, the synthesised speech often exhibits a low level of naturalness. In this work, we propose Diff-ETS, an ETS model which uses a score-based diffusion probabilistic model to enhance the naturalness of synthesised speech. The diffusion model is applied to improve the quality of the acoustic features predicted by an EMG encoder. In our experiments, we evaluated fine-tuning the diffusion model on predictions of a pre-trained EMG encoder, and training both models in an end-to-end fashion. We compared Diff-ETS with a baseline ETS model without diffusion using objective metrics and a listening test. The results indicated the proposed Diff-ETS significantly improved speech naturalness over the baseline.
5/15/2024