Diff-ETS: Learning a Diffusion Probabilistic Model for Electromyography-to-Speech Conversion
2405.08021
0
0
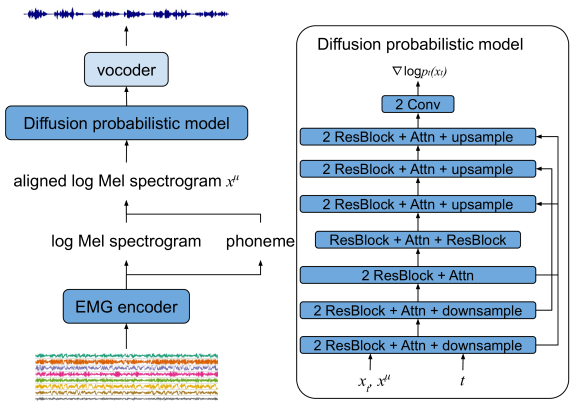
Abstract
Electromyography-to-Speech (ETS) conversion has demonstrated its potential for silent speech interfaces by generating audible speech from Electromyography (EMG) signals during silent articulations. ETS models usually consist of an EMG encoder which converts EMG signals to acoustic speech features, and a vocoder which then synthesises the speech signals. Due to an inadequate amount of available data and noisy signals, the synthesised speech often exhibits a low level of naturalness. In this work, we propose Diff-ETS, an ETS model which uses a score-based diffusion probabilistic model to enhance the naturalness of synthesised speech. The diffusion model is applied to improve the quality of the acoustic features predicted by an EMG encoder. In our experiments, we evaluated fine-tuning the diffusion model on predictions of a pre-trained EMG encoder, and training both models in an end-to-end fashion. We compared Diff-ETS with a baseline ETS model without diffusion using objective metrics and a listening test. The results indicated the proposed Diff-ETS significantly improved speech naturalness over the baseline.
Create account to get full access
Overview
- This paper presents Diff-ETS, a diffusion probabilistic model for converting electromyography (EMG) signals into speech.
- The model is designed to generate natural-sounding speech from silent speech interfaces that capture muscle activity during speech production.
- The authors train the model on a dataset of paired EMG and speech recordings, allowing it to learn the complex mapping between muscular activity and audible speech.
Plain English Explanation
The paper is about a new way to convert silent speech signals into audible speech. Silent speech interfaces use sensors to detect the small muscle movements in your face and throat as you silently mouth words. This allows people who can't speak out loud, like those with voice disorders, to communicate through silent speech.
The key innovation in this work is the use of a diffusion probabilistic model to convert the silent speech signals into natural-sounding speech. Diffusion models work by gradually adding noise to data, then learning how to reverse that process to generate new samples.
By training the diffusion model on a dataset of real EMG signals paired with the corresponding speech audio, the system learns to map the subtle muscle movements directly to the properties of the speech waveform. This allows it to generate fluent, intelligible speech from silent inputs in a way that sounds much more natural than previous approaches.
The authors show that this "Diff-ETS" model outperforms other state-of-the-art methods for converting silent speech to audio, both in terms of speech quality and naturalness. This could be a significant advancement for silent speech interfaces, making them more usable and accessible for people who need them.
Technical Explanation
The core of the Diff-ETS model is a diffusion probabilistic model that learns the mapping from electromyography (EMG) signals to speech. EMG sensors can capture the subtle muscle movements involved in speech production, even when a person is speaking silently. By training the diffusion model on paired datasets of EMG and corresponding speech recordings, it can learn to convert the EMG signals into natural-sounding speech.
The diffusion process works by gradually adding noise to the input EMG data, then training the model to reverse that noising process to generate new speech samples. This allows the model to capture the complex, nonlinear relationship between muscular activity and the acoustic properties of speech. The authors show that this approach outperforms alternative techniques like variational autoencoders and normalizing flows for this EMG-to-speech conversion task.
The authors also explore architectural choices, such as using vision transformer layers to capture the spatial structure of the EMG data. And they demonstrate that the generated speech can be further improved by conditioning the diffusion model on visual lip and facial motion data, in addition to the EMG signals.
Critical Analysis
The Diff-ETS model represents an impressive advance in silent speech interfaces, but the authors acknowledge several limitations and areas for future work. First, the current model is trained and evaluated on a relatively small dataset, so its performance may not generalize as well to more diverse real-world conditions.
Additionally, the authors note that the generated speech, while more natural-sounding than previous methods, still falls short of the quality of natural speech. Continued research and larger training datasets will likely be needed to further improve the fidelity and naturalness of the converted speech.
It would also be valuable to explore the model's robustness to variations in sensor placement, EMG signal quality, and other real-world factors that could impact a practical silent speech interface. The authors briefly touch on this, but more extensive testing would be required to assess the system's viability for real-world deployment.
Overall, the Diff-ETS model represents an exciting step forward in silent speech technology, with the potential to significantly enhance communication for people with voice disorders or other speaking impairments. However, further research and development will be needed to fully realize the promise of this approach.
Conclusion
This paper presents a novel diffusion probabilistic model, called Diff-ETS, for converting silent electromyography (EMG) signals into natural-sounding speech. By training the model on paired datasets of EMG and speech recordings, it learns to map the subtle muscle movements involved in speech production directly to the acoustic properties of the resulting audio.
The authors demonstrate that this diffusion-based approach outperforms alternative techniques, generating speech that is more intelligible and natural-sounding than previous silent speech interfaces. This represents an important advancement that could significantly improve communication options for people with voice disorders or other speech impairments.
While the current model has some limitations, the authors' work lays the foundation for continued progress in this area. With further research to enhance the model's performance and robustness, silent speech interfaces powered by Diff-ETS could become a valuable tool for enhancing accessibility and quality of life for many individuals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Diffusion Synthesizer for Efficient Multilingual Speech to Speech Translation
Nameer Hirschkind, Xiao Yu, Mahesh Kumar Nandwana, Joseph Liu, Eloi DuBois, Dao Le, Nicolas Thiebaut, Colin Sinclair, Kyle Spence, Charles Shang, Zoe Abrams, Morgan McGuire
0
0
We introduce DiffuseST, a low-latency, direct speech-to-speech translation system capable of preserving the input speaker's voice zero-shot while translating from multiple source languages into English. We experiment with the synthesizer component of the architecture, comparing a Tacotron-based synthesizer to a novel diffusion-based synthesizer. We find the diffusion-based synthesizer to improve MOS and PESQ audio quality metrics by 23% each and speaker similarity by 5% while maintaining comparable BLEU scores. Despite having more than double the parameter count, the diffusion synthesizer has lower latency, allowing the entire model to run more than 5$times$ faster than real-time.
6/17/2024
📈
Boosting Diffusion Model for Spectrogram Up-sampling in Text-to-speech: An Empirical Study
Chong Zhang, Yanqing Liu, Yang Zheng, Sheng Zhao
0
0
Scaling text-to-speech (TTS) with autoregressive language model (LM) to large-scale datasets by quantizing waveform into discrete speech tokens is making great progress to capture the diversity and expressiveness in human speech, but the speech reconstruction quality from discrete speech token is far from satisfaction depending on the compressed speech token compression ratio. Generative diffusion models trained with score-matching loss and continuous normalized flow trained with flow-matching loss have become prominent in generation of images as well as speech. LM based TTS systems usually quantize speech into discrete tokens and generate these tokens autoregressively, and finally use a diffusion model to up sample coarse-grained speech tokens into fine-grained codec features or mel-spectrograms before reconstructing into waveforms with vocoder, which has a high latency and is not realistic for real time speech applications. In this paper, we systematically investigate varied diffusion models for up sampling stage, which is the main bottleneck for streaming synthesis of LM and diffusion-based architecture, we present the model architecture, objective and subjective metrics to show quality and efficiency improvement.
6/10/2024
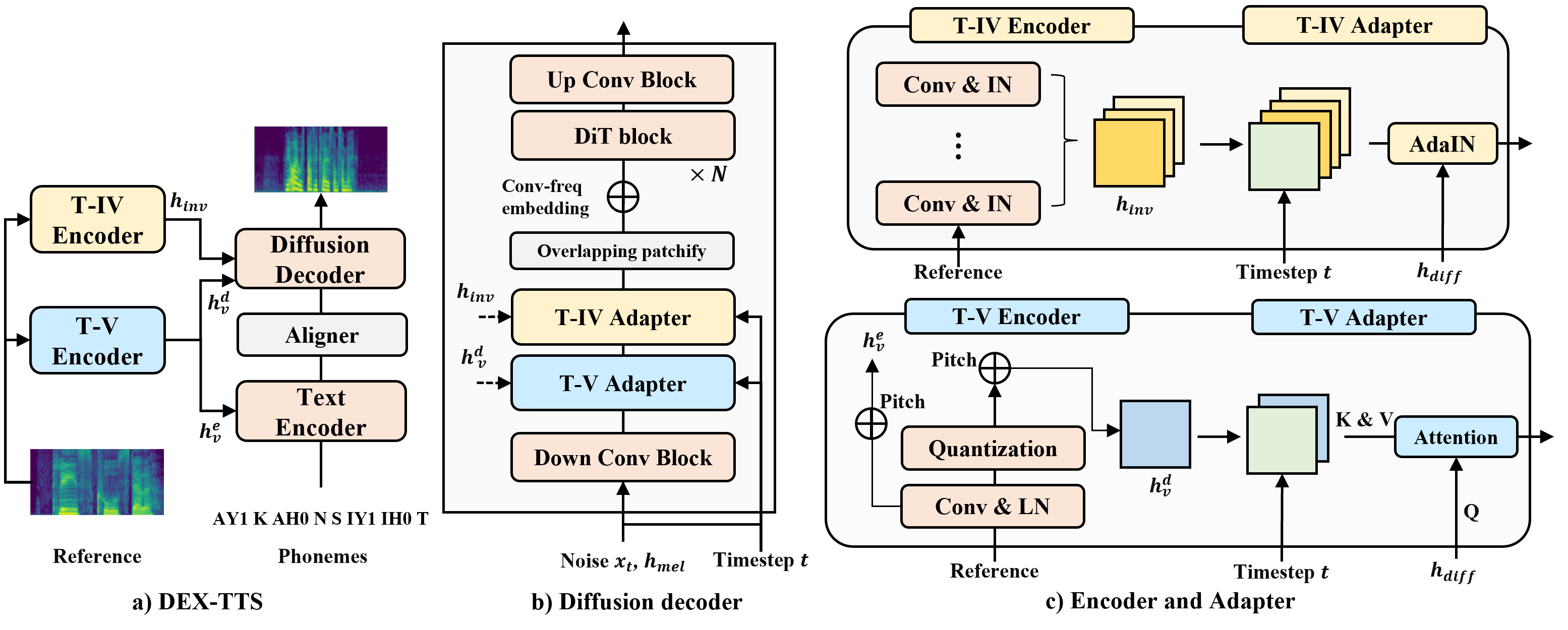
DEX-TTS: Diffusion-based EXpressive Text-to-Speech with Style Modeling on Time Variability
Hyun Joon Park, Jin Sob Kim, Wooseok Shin, Sung Won Han
0
0
Expressive Text-to-Speech (TTS) using reference speech has been studied extensively to synthesize natural speech, but there are limitations to obtaining well-represented styles and improving model generalization ability. In this study, we present Diffusion-based EXpressive TTS (DEX-TTS), an acoustic model designed for reference-based speech synthesis with enhanced style representations. Based on a general diffusion TTS framework, DEX-TTS includes encoders and adapters to handle styles extracted from reference speech. Key innovations contain the differentiation of styles into time-invariant and time-variant categories for effective style extraction, as well as the design of encoders and adapters with high generalization ability. In addition, we introduce overlapping patchify and convolution-frequency patch embedding strategies to improve DiT-based diffusion networks for TTS. DEX-TTS yields outstanding performance in terms of objective and subjective evaluation in English multi-speaker and emotional multi-speaker datasets, without relying on pre-training strategies. Lastly, the comparison results for the general TTS on a single-speaker dataset verify the effectiveness of our enhanced diffusion backbone. Demos are available here.
6/28/2024

DiTTo-TTS: Efficient and Scalable Zero-Shot Text-to-Speech with Diffusion Transformer
Keon Lee, Dong Won Kim, Jaehyeon Kim, Jaewoong Cho
0
0
Large-scale diffusion models have shown outstanding generative abilities across multiple modalities including images, videos, and audio. However, text-to-speech (TTS) systems typically involve domain-specific modeling factors (e.g., phonemes and phoneme-level durations) to ensure precise temporal alignments between text and speech, which hinders the efficiency and scalability of diffusion models for TTS. In this work, we present an efficient and scalable Diffusion Transformer (DiT) that utilizes off-the-shelf pre-trained text and speech encoders. Our approach addresses the challenge of text-speech alignment via cross-attention mechanisms with the prediction of the total length of speech representations. To achieve this, we enhance the DiT architecture to suit TTS and improve the alignment by incorporating semantic guidance into the latent space of speech. We scale the training dataset and the model size to 82K hours and 790M parameters, respectively. Our extensive experiments demonstrate that the large-scale diffusion model for TTS without domain-specific modeling not only simplifies the training pipeline but also yields superior or comparable zero-shot performance to state-of-the-art TTS models in terms of naturalness, intelligibility, and speaker similarity. Our speech samples are available at https://ditto-tts.github.io.
6/18/2024