Navigating the Noisy Crowd: Finding Key Information for Claim Verification

0

Sign in to get full access
Overview
- This paper presents a novel approach to finding key information for claim verification in a noisy online environment.
- The authors develop a system that can effectively navigate through large amounts of potentially unreliable information to identify the most relevant evidence for verifying a given claim.
- The proposed method leverages language models and retrieval techniques to surface the most salient evidence from a diverse set of online sources.
- The researchers evaluate their system on real-world datasets and demonstrate significant improvements over previous claim verification approaches.
Plain English Explanation
The paper tackles the challenge of verifying claims in the modern, noisy online world. When someone makes a claim, there's often a lot of information - some reliable, some not - spread across various websites, social media, and other sources. The goal is to find the most relevant and trustworthy evidence to determine if the claim is true or false.
The researchers developed a system that can efficiently sift through all this noisy information and identify the key facts and sources needed for claim verification. Their approach uses advanced language models and information retrieval techniques to surface the most salient evidence for a given claim.
For example, if someone claims that a certain product is the most energy-efficient on the market, the system would search through many online reviews, news articles, and other sources to find the most relevant data on the product's energy efficiency. It would then provide the most credible and compelling evidence to support or refute the original claim.
By automating this process, the system can help fact-checkers, journalists, and everyday internet users quickly cut through the clutter and get to the heart of the matter when verifying claims. This is an important step in combating the spread of misinformation online.
Technical Explanation
The paper proposes a novel claim verification system that tackles the challenge of navigating the "noisy crowd" of online information. The authors develop a multi-stage approach that leverages language models and retrieval techniques to identify the most relevant evidence for verifying a given claim.
The first stage involves using a pre-trained language model to generate a query that captures the key semantics of the input claim. This query is then used to retrieve a set of potentially relevant documents from a large corpus of web pages, social media posts, and other online sources.
Next, the system employs a claim-aware document ranking model to re-order the retrieved documents based on their relevance to the specific claim. This model takes into account both the content of the documents and their relationship to the claim itself.
Finally, a claim-aware evidence extraction module is used to identify the most salient snippets of text within the top-ranked documents that provide the strongest supporting or refuting evidence for the claim. This evidence is then presented to the user as the basis for their claim verification judgment.
The authors evaluate their system on several real-world datasets and demonstrate significant improvements over previous claim verification approaches in terms of both accuracy and efficiency. The proposed method is shown to be effective at navigating the noisy online landscape to surface the most credible and informative evidence for claim verification.
Critical Analysis
The paper presents a well-designed and innovative approach to the challenging problem of claim verification in the modern, information-rich online environment. The authors have thoughtfully addressed key challenges such as query formulation, document retrieval, and evidence extraction to create a robust and scalable system.
One notable strength of the proposed method is its ability to leverage large language models and retrieval techniques to efficiently navigate through a vast and diverse corpus of online information. This allows the system to surface the most relevant evidence for a given claim, even in the face of significant noise and misinformation.
However, the paper also acknowledges several limitations and areas for future research. For example, the system's performance is still dependent on the quality and coverage of the underlying data sources. Addressing issues of source credibility, bias, and completeness could further improve the system's reliability.
Additionally, the paper does not explore the potential for adversarial attacks or attempts to game the system. As with any automated fact-checking approach, there is a risk of bad actors trying to exploit vulnerabilities in the system. Developing more robust safeguards against such attacks would be an important area for future work.
Overall, the paper represents a significant contribution to the field of claim verification and fact-checking. The proposed system demonstrates the potential for AI-powered tools to help navigate the challenges of the modern information landscape. However, continued research and development will be necessary to address the complex, evolving challenges of online misinformation.
Conclusion
This paper presents a novel approach to claim verification that tackles the challenge of finding reliable evidence in the noisy online environment. The authors develop a multi-stage system that leverages language models and retrieval techniques to efficiently surface the most relevant and credible information for verifying a given claim.
By automating the process of sifting through large amounts of potentially unreliable data, the proposed system has the potential to significantly improve the speed and accuracy of fact-checking efforts. This could be a valuable tool for journalists, fact-checkers, and everyday internet users in the ongoing fight against the spread of misinformation.
While the paper acknowledges several limitations and areas for future research, the proposed approach represents a significant advancement in the field of claim verification. As online information continues to proliferate, developing robust and scalable systems for navigating this "noisy crowd" will only become more crucial for maintaining a well-informed and truth-seeking society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Navigating the Noisy Crowd: Finding Key Information for Claim Verification
Haisong Gong, Huanhuan Ma, Qiang Liu, Shu Wu, Liang Wang
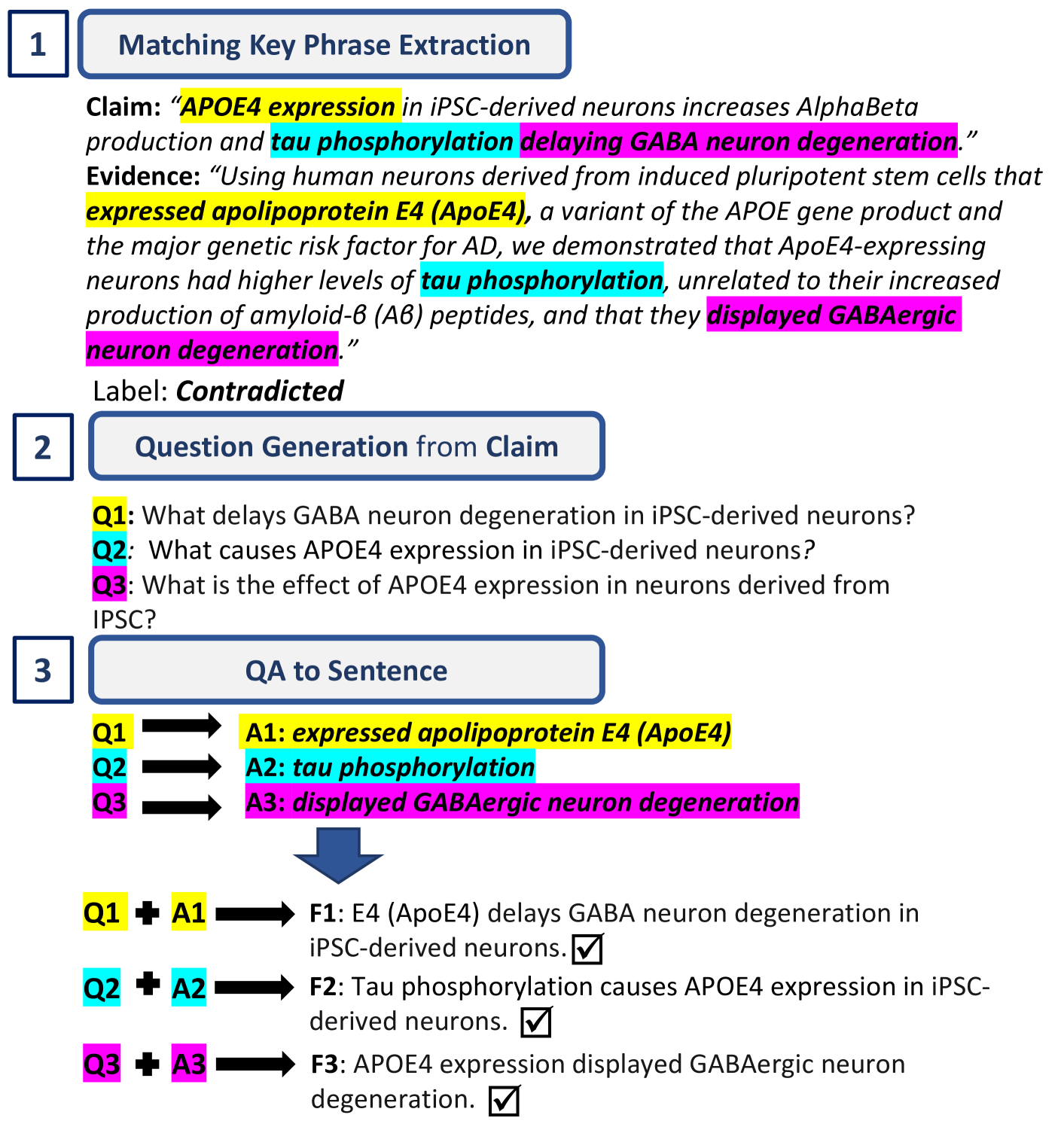
Claim verification is a task that involves assessing the truthfulness of a given claim based on multiple evidence pieces. Using large language models (LLMs) for claim verification is a promising way. However, simply feeding all the evidence pieces to an LLM and asking if the claim is factual does not yield good results. The challenge lies in the noisy nature of both the evidence and the claim: evidence passages typically contain irrelevant information, with the key facts hidden within the context, while claims often convey multiple aspects simultaneously. To navigate this noisy crowd of information, we propose EACon (Evidence Abstraction and Claim Deconstruction), a framework designed to find key information within evidence and verify each aspect of a claim separately. EACon first finds keywords from the claim and employs fuzzy matching to select relevant keywords for each raw evidence piece. These keywords serve as a guide to extract and summarize critical information into abstracted evidence. Subsequently, EACon deconstructs the original claim into subclaims, which are then verified against both abstracted and raw evidence individually. We evaluate EACon using two open-source LLMs on two challenging datasets. Results demonstrate that EACon consistently and substantially improve LLMs' performance in claim verification.
Read more7/18/2024
🌐
0
Complex Claim Verification with Evidence Retrieved in the Wild
Jifan Chen, Grace Kim, Aniruddh Sriram, Greg Durrett, Eunsol Choi
Evidence retrieval is a core part of automatic fact-checking. Prior work makes simplifying assumptions in retrieval that depart from real-world use cases: either no access to evidence, access to evidence curated by a human fact-checker, or access to evidence available long after the claim has been made. In this work, we present the first fully automated pipeline to check real-world claims by retrieving raw evidence from the web. We restrict our retriever to only search documents available prior to the claim's making, modeling the realistic scenario where an emerging claim needs to be checked. Our pipeline includes five components: claim decomposition, raw document retrieval, fine-grained evidence retrieval, claim-focused summarization, and veracity judgment. We conduct experiments on complex political claims in the ClaimDecomp dataset and show that the aggregated evidence produced by our pipeline improves veracity judgments. Human evaluation finds the evidence summary produced by our system is reliable (it does not hallucinate information) and relevant to answering key questions about a claim, suggesting that it can assist fact-checkers even when it cannot surface a complete evidence set.
Read more6/18/2024
0
Robust Claim Verification Through Fact Detection
Nazanin Jafari, James Allan
Claim verification can be a challenging task. In this paper, we present a method to enhance the robustness and reasoning capabilities of automated claim verification through the extraction of short facts from evidence. Our novel approach, FactDetect, leverages Large Language Models (LLMs) to generate concise factual statements from evidence and label these facts based on their semantic relevance to the claim and evidence. The generated facts are then combined with the claim and evidence. To train a lightweight supervised model, we incorporate a fact-detection task into the claim verification process as a multitasking approach to improve both performance and explainability. We also show that augmenting FactDetect in the claim verification prompt enhances performance in zero-shot claim verification using LLMs. Our method demonstrates competitive results in the supervised claim verification model by 15% on the F1 score when evaluated for challenging scientific claim verification datasets. We also demonstrate that FactDetect can be augmented with claim and evidence for zero-shot prompting (AugFactDetect) in LLMs for verdict prediction. We show that AugFactDetect outperforms the baseline with statistical significance on three challenging scientific claim verification datasets with an average of 17.3% performance gain compared to the best performing baselines.
Read more7/29/2024

0
Claim Verification in the Age of Large Language Models: A Survey
Alphaeus Dmonte, Roland Oruche, Marcos Zampieri, Prasad Calyam, Isabelle Augenstein
The large and ever-increasing amount of data available on the Internet coupled with the laborious task of manual claim and fact verification has sparked the interest in the development of automated claim verification systems. Several deep learning and transformer-based models have been proposed for this task over the years. With the introduction of Large Language Models (LLMs) and their superior performance in several NLP tasks, we have seen a surge of LLM-based approaches to claim verification along with the use of novel methods such as Retrieval Augmented Generation (RAG). In this survey, we present a comprehensive account of recent claim verification frameworks using LLMs. We describe the different components of the claim verification pipeline used in these frameworks in detail including common approaches to retrieval, prompting, and fine-tuning. Finally, we describe publicly available English datasets created for this task.
Read more8/27/2024