NaviQAte: Functionality-Guided Web Application Navigation

0
Sign in to get full access
Overview
- NaviQAte is a functionality-guided web application navigation system that aims to help users complete tasks on websites more efficiently.
- It uses a large language model (LLM) agent to understand user intentions and navigate through web applications step-by-step to complete desired tasks.
- The system is designed to assist users, especially those with disabilities, in navigating complex websites and accomplishing their goals.
Plain English Explanation
NaviQAte: Functionality-Guided Web Application Navigation describes a new approach to web navigation that leverages the capabilities of large language models (LLMs). The key idea is to use an LLM agent to understand a user's high-level goals or "intentions" when they are trying to complete a task on a website, and then guide them through the necessary steps to accomplish that task.
For example, imagine you need to book a flight on an airline's website. Instead of hunting through menus and links to find the right pages, you could simply tell the NaviQAte agent "I want to book a flight from New York to Los Angeles." The agent would then understand your intention and navigate the website on your behalf, guiding you through the process of selecting dates, choosing a flight, and completing the booking.
This functionality-guided approach is particularly helpful for users who may struggle with complex website layouts, such as those with disabilities or limited technical expertise. By translating high-level user intentions into specific actions, NaviQAte aims to make web navigation more accessible and efficient for a wide range of users.
Technical Explanation
NaviQAte is a web application navigation system that uses a large language model (LLM) agent to understand user intentions and guide them through the necessary steps to complete desired tasks. The system consists of three main components:
-
Intent Extraction: The LLM agent is used to analyze the user's natural language input and extract their high-level intentions or goals (e.g., "book a flight").
-
Task Decomposition: Based on the extracted intentions, the system breaks down the task into a sequence of granular actions required to accomplish the goal (e.g., navigate to the flights page, select travel dates, choose a flight, complete booking).
-
Task Execution: The system then automates the execution of these individual actions, navigating the web application on the user's behalf to complete the task.
The researchers evaluated NaviQAte's performance on a range of web application tasks, including flight booking, online shopping, and document editing. They found that the system was able to successfully complete the desired tasks with high accuracy, demonstrating the potential of LLM-powered web navigation to improve user productivity and accessibility.
Critical Analysis
The NaviQAte paper presents a promising approach to web application navigation, but there are a few potential limitations and areas for further research:
-
Robustness: The paper does not extensively discuss the robustness of the system to variations in user input or changes in website layouts. More research is needed to understand how well NaviQAte would perform in real-world scenarios with unpredictable user requests and evolving web applications.
-
Ethical Considerations: The use of an LLM agent to autonomously navigate websites on a user's behalf raises some ethical questions, such as the potential for privacy concerns or unintended actions. The paper does not address these issues in depth.
-
Generalization: While the system was evaluated on a range of tasks, it's unclear how well the approach would scale to a broader set of web applications or use cases. Further research is needed to understand the limits of the system's capabilities.
Overall, the NaviQAte paper presents an interesting and potentially impactful approach to web navigation, but additional research is needed to fully understand its practical implications and limitations.
Conclusion
NaviQAte: Functionality-Guided Web Application Navigation introduces a novel approach to web navigation that leverages the capabilities of large language models to understand user intentions and automate the steps required to complete desired tasks. By translating high-level goals into granular actions, the system aims to make web applications more accessible and efficient for a wide range of users, particularly those with disabilities or limited technical expertise.
While the paper presents promising results, further research is needed to address potential limitations, such as robustness, ethical considerations, and generalization to a broader set of use cases. Nonetheless, the NaviQAte system represents an exciting step forward in the integration of advanced AI technologies into web-based user experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NaviQAte: Functionality-Guided Web Application Navigation
Mobina Shahbandeh, Parsa Alian, Noor Nashid, Ali Mesbah
End-to-end web testing is challenging due to the need to explore diverse web application functionalities. Current state-of-the-art methods, such as WebCanvas, are not designed for broad functionality exploration; they rely on specific, detailed task descriptions, limiting their adaptability in dynamic web environments. We introduce NaviQAte, which frames web application exploration as a question-and-answer task, generating action sequences for functionalities without requiring detailed parameters. Our three-phase approach utilizes advanced large language models like GPT-4o for complex decision-making and cost-effective models, such as GPT-4o mini, for simpler tasks. NaviQAte focuses on functionality-guided web application navigation, integrating multi-modal inputs such as text and images to enhance contextual understanding. Evaluations on the Mind2Web-Live and Mind2Web-Live-Abstracted datasets show that NaviQAte achieves a 44.23% success rate in user task navigation and a 38.46% success rate in functionality navigation, representing a 15% and 33% improvement over WebCanvas. These results underscore the effectiveness of our approach in advancing automated web application testing.
Read more9/18/2024
⛏️
0
Can ChatGPT assist visually impaired people with micro-navigation?
Junxian He, Shrinivas Pundlik, Gang Luo
Objective: Micro-navigation poses challenges for blind and visually impaired individuals. They often need to ask for sighted assistance. We explored the feasibility of utilizing ChatGPT as a virtual assistant to provide navigation directions. Methods: We created a test set of outdoor and indoor micro-navigation scenarios consisting of 113 scene images and their human-generated text descriptions. A total of 412 way-finding queries and their expected responses were compiled based on the scenarios. Not all queries are answerable based on the information available in the scene image. I do not knowresponse was expected for unanswerable queries, which served as negative cases. High level orientation responses were expected, and step-by-step guidance was not required. ChatGPT 4o was evaluated based on sensitivity (SEN) and specificity (SPE) under different conditions. Results: The default ChatGPT 4o, with scene images as inputs, resulted in SEN and SPE values of 64.8% and 75.9%, respectively. Instruction on how to respond to unanswerable questions did not improve SEN substantially but SPE increased by around 14 percentage points. SEN and SPE both improved substantially, by about 17 and 16 percentage points on average respectively, when human written descriptions of the scenes were provided as input instead of images. Providing further prompt instructions to the assistants when the input was text description did not substantially change the SEN and SPE values. Conclusion: Current native ChatGPT 4o is still unable to provide correct micro-navigation guidance in some cases, probably because its scene understanding is not optimized for navigation purposes. If multi-modal chatbots could interpret scenes with a level of clarity comparable to humans, and also guided by appropriate prompts, they may have the potential to provide assistance to visually impaired for micro-navigation.
Read more8/19/2024
0
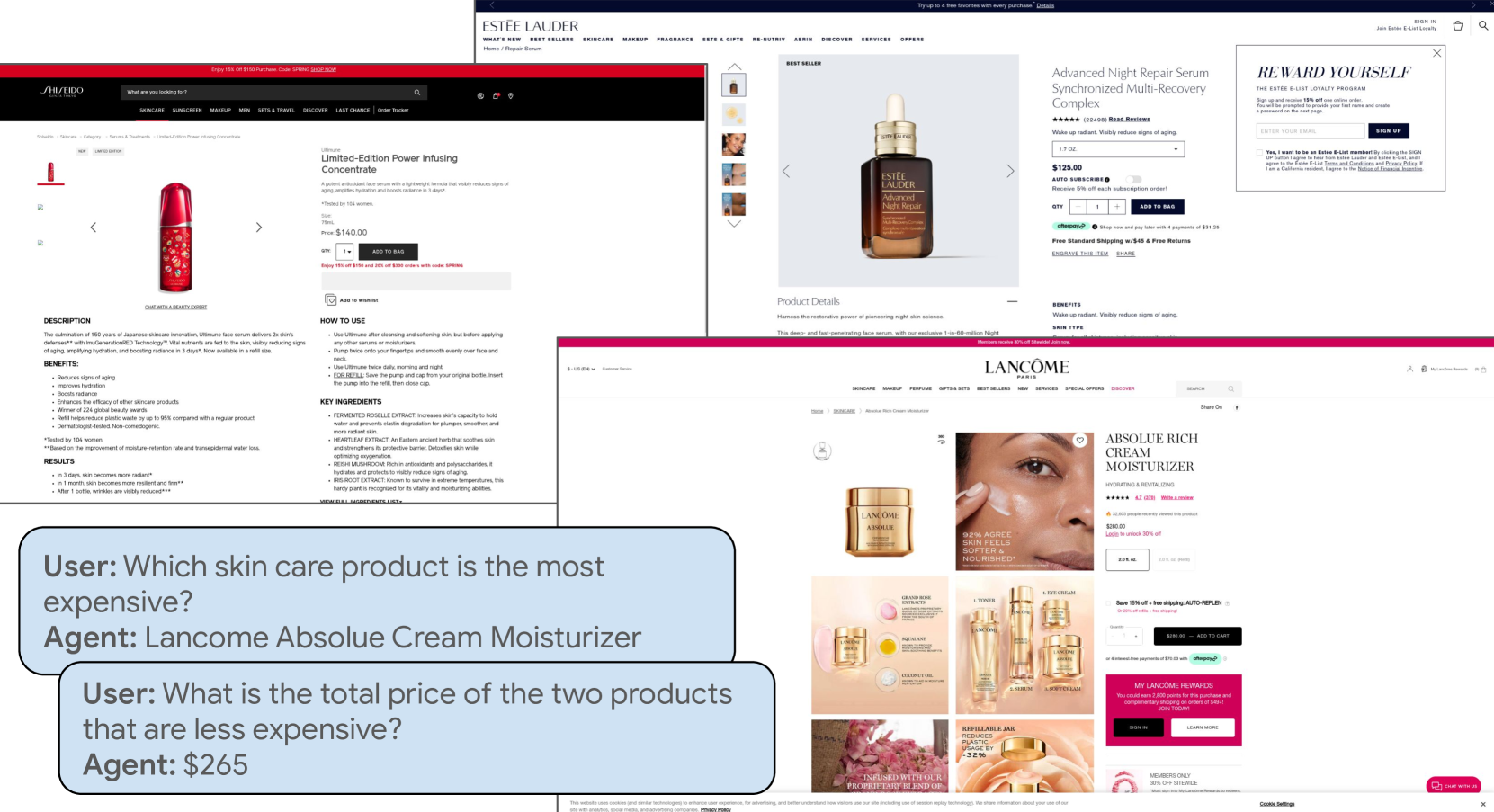
WebQuest: A Benchmark for Multimodal QA on Web Page Sequences
Maria Wang, Srinivas Sunkara, Gilles Baechler, Jason Lin, Yun Zhu, Fedir Zubach, Lei Shu, Jindong Chen
The rise of powerful multimodal LLMs has enhanced the viability of building web agents which can, with increasing levels of autonomy, assist users to retrieve information and complete tasks on various human-computer interfaces. It is hence necessary to build challenging benchmarks that span a wide-variety of use cases reflecting real-world usage. In this work, we present WebQuest, a multi-page question-answering dataset that requires reasoning across multiple related web pages. In contrast to existing UI benchmarks that focus on multi-step web navigation and task completion, our dataset evaluates information extraction, multimodal retrieval and composition of information from many web pages. WebQuest includes three question categories: single-screen QA, multi-screen QA, and QA based on navigation traces. We evaluate leading proprietary multimodal models like GPT-4V, Gemini Flash, Claude 3, and open source models like InstructBLIP, PaliGemma on our dataset, revealing a significant gap between single-screen and multi-screen reasoning. Finally, we investigate inference time techniques like Chain-of-Thought prompting to improve model capabilities on multi-screen reasoning.
Read more9/26/2024

0
UINav: A Practical Approach to Train On-Device Automation Agents
Wei Li, Fu-Lin Hsu, Will Bishop, Folawiyo Campbell-Ajala, Max Lin, Oriana Riva
Automation systems that can autonomously drive application user interfaces to complete user tasks are of great benefit, especially when users are situationally or permanently impaired. Prior automation systems do not produce generalizable models while AI-based automation agents work reliably only in simple, hand-crafted applications or incur high computation costs. We propose UINav, a demonstration-based approach to train automation agents that fit mobile devices, yet achieving high success rates with modest numbers of demonstrations. To reduce the demonstration overhead, UINav uses a referee model that provides users with immediate feedback on tasks where the agent fails, and automatically augments human demonstrations to increase diversity in training data. Our evaluation shows that with only 10 demonstrations UINav can achieve 70% accuracy, and that with enough demonstrations it can surpass 90% accuracy.
Read more7/1/2024