WebQuest: A Benchmark for Multimodal QA on Web Page Sequences

0
Sign in to get full access
Overview
- The paper introduces WebQuest, a new benchmark for evaluating multimodal question answering (QA) on sequences of web pages.
- WebQuest presents QA tasks that require understanding web content and integrating information across multiple pages.
- The benchmark aims to advance research in multimodal reasoning and push the boundaries of current language and vision models.
Plain English Explanation
The WebQuest benchmark is designed to test how well AI systems can answer questions by understanding and combining information from a series of web pages. Typical QA tasks focus on finding answers within a single page, but real-world questions often require piecing together details across multiple sources.
WebQuest presents questions that can only be answered by carefully reading and synthesizing content from a sequence of related web pages. This forces AI models to go beyond simple lookup and develop more sophisticated multimodal reasoning capabilities. The goal is to drive progress in areas like natural language understanding, visual recognition, and cross-modal information integration.
By creating this challenging benchmark, the researchers hope to spur the development of AI assistants that can truly comprehend and reason about the wealth of information on the web, just as humans do. This could lead to more powerful and versatile question-answering systems with applications in education, research, and everyday information-seeking tasks.
Technical Explanation
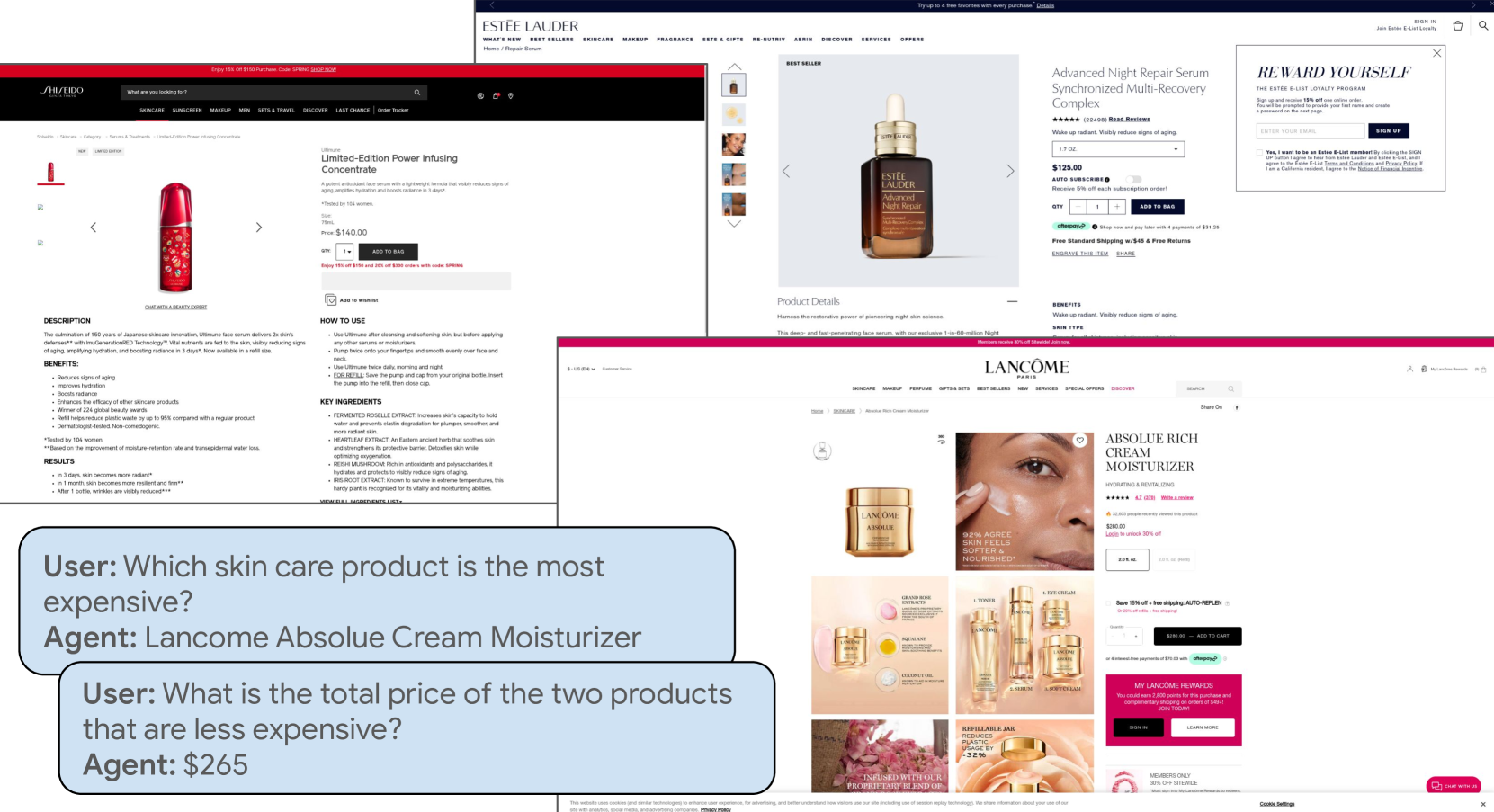
The WebQuest dataset consists of over 30,000 multimodal QA examples, each with a sequence of 2-4 web pages and a corresponding question that requires understanding and integrating information across those pages. The web pages include text, images, and other modalities, mirroring the rich, multifaceted nature of real-world online content.
The questions cover a diverse range of topics and often involve tasks like:
- Connecting visual and textual information
- Reasoning about relationships between entities
- Combining details from different pages to infer new facts
- Understanding the context and intent behind a query
Evaluating on WebQuest tests a model's ability to comprehend and reason about complex, multimodal web content, going beyond simple information retrieval. The benchmark aims to drive progress in areas like multimodal situated reasoning, world knowledge, and the evolution of multimodal language models.
Critical Analysis
The WebQuest benchmark represents an important step forward in evaluating multimodal reasoning capabilities. By focusing on web page sequences rather than isolated pages or images, it more closely mirrors real-world information-seeking tasks.
However, the authors acknowledge some limitations. The web pages in WebQuest are curated and may not fully capture the diversity and noisiness of the actual web. Additionally, the benchmark does not address aspects like open-ended dialogue or task-oriented interactions.
Further research is needed to develop models that can truly understand and reason about the full breadth of online content and user information needs. Extending benchmarks like VisualWebArena to include web page sequences could be a fruitful direction.
Conclusion
The WebQuest benchmark represents an important advance in evaluating multimodal QA systems. By challenging models to understand and integrate information across web page sequences, it pushes the boundaries of current language and vision capabilities. Successful performance on WebQuest could lead to more powerful and versatile AI assistants, with applications ranging from education and research to everyday information-seeking tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
WebQuest: A Benchmark for Multimodal QA on Web Page Sequences
Maria Wang, Srinivas Sunkara, Gilles Baechler, Jason Lin, Yun Zhu, Fedir Zubach, Lei Shu, Jindong Chen
The rise of powerful multimodal LLMs has enhanced the viability of building web agents which can, with increasing levels of autonomy, assist users to retrieve information and complete tasks on various human-computer interfaces. It is hence necessary to build challenging benchmarks that span a wide-variety of use cases reflecting real-world usage. In this work, we present WebQuest, a multi-page question-answering dataset that requires reasoning across multiple related web pages. In contrast to existing UI benchmarks that focus on multi-step web navigation and task completion, our dataset evaluates information extraction, multimodal retrieval and composition of information from many web pages. WebQuest includes three question categories: single-screen QA, multi-screen QA, and QA based on navigation traces. We evaluate leading proprietary multimodal models like GPT-4V, Gemini Flash, Claude 3, and open source models like InstructBLIP, PaliGemma on our dataset, revealing a significant gap between single-screen and multi-screen reasoning. Finally, we investigate inference time techniques like Chain-of-Thought prompting to improve model capabilities on multi-screen reasoning.
Read more9/26/2024

0
VisualWebBench: How Far Have Multimodal LLMs Evolved in Web Page Understanding and Grounding?
Junpeng Liu, Yifan Song, Bill Yuchen Lin, Wai Lam, Graham Neubig, Yuanzhi Li, Xiang Yue
Multimodal Large Language models (MLLMs) have shown promise in web-related tasks, but evaluating their performance in the web domain remains a challenge due to the lack of comprehensive benchmarks. Existing benchmarks are either designed for general multimodal tasks, failing to capture the unique characteristics of web pages, or focus on end-to-end web agent tasks, unable to measure fine-grained abilities such as OCR, understanding, and grounding. In this paper, we introduce bench{}, a multimodal benchmark designed to assess the capabilities of MLLMs across a variety of web tasks. bench{} consists of seven tasks, and comprises 1.5K human-curated instances from 139 real websites, covering 87 sub-domains. We evaluate 14 open-source MLLMs, Gemini Pro, Claude-3 series, and GPT-4V(ision) on bench{}, revealing significant challenges and performance gaps. Further analysis highlights the limitations of current MLLMs, including inadequate grounding in text-rich environments and subpar performance with low-resolution image inputs. We believe bench{} will serve as a valuable resource for the research community and contribute to the creation of more powerful and versatile MLLMs for web-related applications.
Read more4/10/2024
🗣️
0
WorldQA: Multimodal World Knowledge in Videos through Long-Chain Reasoning
Yuanhan Zhang, Kaichen Zhang, Bo Li, Fanyi Pu, Christopher Arif Setiadharma, Jingkang Yang, Ziwei Liu
Multimodal information, together with our knowledge, help us to understand the complex and dynamic world. Large language models (LLM) and large multimodal models (LMM), however, still struggle to emulate this capability. In this paper, we present WorldQA, a video understanding dataset designed to push the boundaries of multimodal world models with three appealing properties: (1) Multimodal Inputs: The dataset comprises 1007 question-answer pairs and 303 videos, necessitating the analysis of both auditory and visual data for successful interpretation. (2) World Knowledge: We identify five essential types of world knowledge for question formulation. This approach challenges models to extend their capabilities beyond mere perception. (3) Long-Chain Reasoning: Our dataset introduces an average reasoning step of 4.45, notably surpassing other videoQA datasets. Furthermore, we introduce WorldRetriever, an agent designed to synthesize expert knowledge into a coherent reasoning chain, thereby facilitating accurate responses to WorldQA queries. Extensive evaluations of 13 prominent LLMs and LMMs reveal that WorldRetriever, although being the most effective model, achieved only 70% of humanlevel performance in multiple-choice questions. This finding highlights the necessity for further advancement in the reasoning and comprehension abilities of models. Our experiments also yield several key insights. For instance, while humans tend to perform better with increased frames, current LMMs, including WorldRetriever, show diminished performance under similar conditions. We hope that WorldQA,our methodology, and these insights could contribute to the future development of multimodal world models.
Read more5/7/2024
🏋️
0
VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, Daniel Fried
Autonomous agents capable of planning, reasoning, and executing actions on the web offer a promising avenue for automating computer tasks. However, the majority of existing benchmarks primarily focus on text-based agents, neglecting many natural tasks that require visual information to effectively solve. Given that most computer interfaces cater to human perception, visual information often augments textual data in ways that text-only models struggle to harness effectively. To bridge this gap, we introduce VisualWebArena, a benchmark designed to assess the performance of multimodal web agents on realistic textit{visually grounded tasks}. VisualWebArena comprises of a set of diverse and complex web-based tasks that evaluate various capabilities of autonomous multimodal agents. To perform on this benchmark, agents need to accurately process image-text inputs, interpret natural language instructions, and execute actions on websites to accomplish user-defined objectives. We conduct an extensive evaluation of state-of-the-art LLM-based autonomous agents, including several multimodal models. Through extensive quantitative and qualitative analysis, we identify several limitations of text-only LLM agents, and reveal gaps in the capabilities of state-of-the-art multimodal language agents. VisualWebArena provides a framework for evaluating multimodal autonomous language agents, and offers insights towards building stronger autonomous agents for the web. Our code, baseline models, and data is publicly available at https://jykoh.com/vwa.
Read more6/7/2024