NDVQ: Robust Neural Audio Codec with Normal Distribution-Based Vector Quantization

0
Sign in to get full access
Overview
- This paper introduces NDVQ, a robust neural audio codec that uses normal distribution-based vector quantization.
- The goal is to create a high-quality, low-bitrate audio codec for real-time communications.
- The key innovations include a neural network architecture and a novel quantization method based on normal distributions.
Plain English Explanation
The researchers have developed a new way to compress and transmit audio data efficiently. Their NDVQ system uses a neural network and a special quantization technique to encode audio into a smaller digital file, which can then be decoded and played back.
The main advantage of NDVQ is that it can produce high-quality audio at a very low bitrate, making it well-suited for real-time communication applications like video calls or online gaming. This is achieved by using a neural network to analyze the audio signal and identify patterns that can be compressed without losing important details.
Additionally, the researchers introduced a novel quantization method based on normal distributions. This helps the system adapt to different types of audio and maintain good quality even in the presence of noise or other distortions.
Technical Explanation
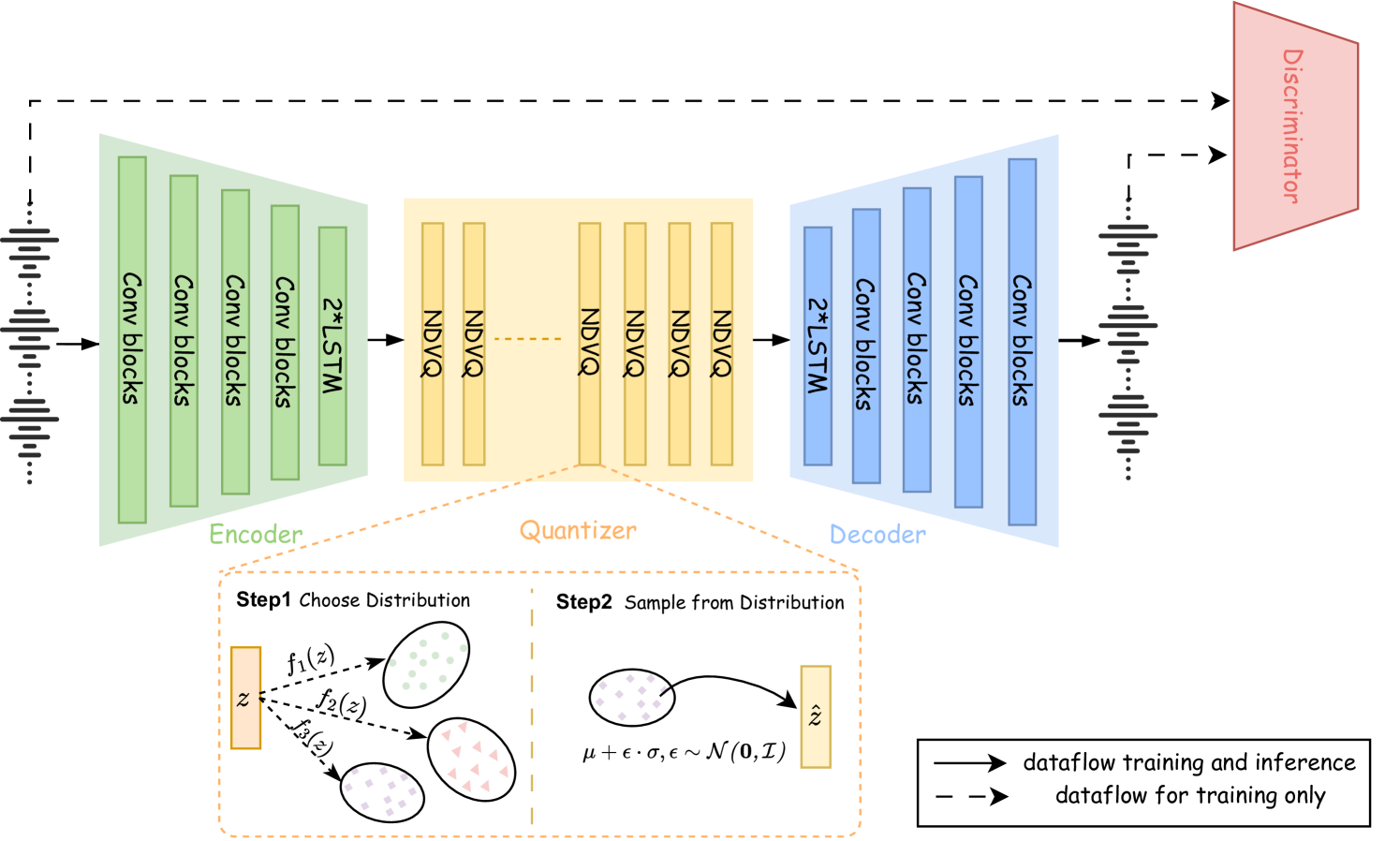
The NDVQ system consists of an encoder network and a decoder network. The encoder takes in raw audio samples and outputs a compressed representation, while the decoder reconstructs the original audio from this compressed signal.
The key innovation is the use of normal distribution-based vector quantization (NDVQ) in the encoder. Instead of traditional quantization methods, NDVQ models the input audio features as a mixture of normal distributions, which allows it to more accurately capture the statistical properties of the data.
The encoder network first extracts relevant features from the input audio. These features are then passed through the NDVQ module, which compresses them into a compact representation. The decoder network uses this compressed representation to reconstruct the original audio.
The researchers evaluated NDVQ on several benchmark datasets and found that it outperforms other state-of-the-art neural audio codecs in terms of both objective and subjective audio quality, while also achieving lower bitrates.
Critical Analysis
The NDVQ paper presents a promising approach to neural audio coding, but there are a few potential limitations and areas for further research:
- The paper does not provide much insight into the practical computational and memory requirements of the NDVQ system, which could be important for real-world deployment, especially on resource-constrained devices.
- The evaluation is primarily focused on standard audio quality metrics, but it would be valuable to also assess the system's performance in real-world communication scenarios, such as its robustness to packet loss or its ability to adapt to different speakers and acoustic environments.
- The authors mention that the NDVQ module could potentially be further improved by incorporating more advanced probabilistic modeling techniques, but they do not provide details on how this could be accomplished.
Overall, the NDVQ paper presents an interesting and potentially impactful contribution to the field of neural audio coding. However, further research and development may be needed to fully realize the system's potential for real-time communication applications.
Conclusion
The NDVQ paper introduces a novel neural audio codec that uses a normal distribution-based vector quantization technique to achieve high-quality, low-bitrate audio compression. This system could have significant implications for real-time communication applications, as it addresses the need for efficient, robust audio coding solutions.
While the paper presents promising results, further research is needed to fully understand the practical constraints and explore potential avenues for improvement, such as more advanced probabilistic modeling or evaluations in realistic communication scenarios. Overall, the NDVQ approach represents an important step forward in the development of efficient and high-performance neural audio codecs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!NDVQ: Robust Neural Audio Codec with Normal Distribution-Based Vector Quantization
Zhikang Niu, Sanyuan Chen, Long Zhou, Ziyang Ma, Xie Chen, Shujie Liu
Built upon vector quantization (VQ), discrete audio codec models have achieved great success in audio compression and auto-regressive audio generation. However, existing models face substantial challenges in perceptual quality and signal distortion, especially when operating in extremely low bandwidth, rooted in the sensitivity of the VQ codebook to noise. This degradation poses significant challenges for several downstream tasks, such as codec-based speech synthesis. To address this issue, we propose a novel VQ method, Normal Distribution-based Vector Quantization (NDVQ), by introducing an explicit margin between the VQ codes via learning a variance. Specifically, our approach involves mapping the waveform to a latent space and quantizing it by selecting the most likely normal distribution, with each codebook entry representing a unique normal distribution defined by its mean and variance. Using these distribution-based VQ codec codes, a decoder reconstructs the input waveform. NDVQ is trained with additional distribution-related losses, alongside reconstruction and discrimination losses. Experiments demonstrate that NDVQ outperforms existing audio compression baselines, such as EnCodec, in terms of audio quality and zero-shot TTS, particularly in very low bandwidth scenarios.
Read more9/20/2024
🧠
0
Simple and Efficient Quantization Techniques for Neural Speech Coding
Andreas Brendel, Nicola Pia, Kishan Gupta, Lyonel Behringer, Guillaume Fuchs, Markus Multrus
Neural audio coding has emerged as a vivid research direction by promising good audio quality at very low bitrates unachievable by classical coding techniques. Here, end-to-end trainable autoencoder-like models represent the state of the art, where a discrete representation in the bottleneck of the autoencoder is learned. This allows for efficient transmission of the input audio signal. The learned discrete representation of neural codecs is typically generated by applying a quantizer to the output of the neural encoder. In almost all state-of-the-art neural audio coding approaches, this quantizer is realized as a Vector Quantizer (VQ) and a lot of effort has been spent to alleviate drawbacks of this quantization technique when used together with a neural audio coder. In this paper, we propose and analyze simple alternatives to VQ, which are based on projected Scalar Quantization (SQ). These quantization techniques do not need any additional losses, scheduling parameters or codebook storage thereby simplifying the training of neural audio codecs. For real-time speech communication applications, these neural codecs are required to operate at low complexity, low latency and at low bitrates. We address those challenges by proposing a new causal network architecture that is based on SQ and a Short-Time Fourier Transform (STFT) representation. The proposed method performs particularly well in the very low complexity and low bitrate regime.
Read more9/20/2024
🧠
0
Residual Quantization with Implicit Neural Codebooks
Iris A. M. Huijben, Matthijs Douze, Matthew Muckley, Ruud J. G. van Sloun, Jakob Verbeek
Vector quantization is a fundamental operation for data compression and vector search. To obtain high accuracy, multi-codebook methods represent each vector using codewords across several codebooks. Residual quantization (RQ) is one such method, which iteratively quantizes the error of the previous step. While the error distribution is dependent on previously-selected codewords, this dependency is not accounted for in conventional RQ as it uses a fixed codebook per quantization step. In this paper, we propose QINCo, a neural RQ variant that constructs specialized codebooks per step that depend on the approximation of the vector from previous steps. Experiments show that QINCo outperforms state-of-the-art methods by a large margin on several datasets and code sizes. For example, QINCo achieves better nearest-neighbor search accuracy using 12-byte codes than the state-of-the-art UNQ using 16 bytes on the BigANN1M and Deep1M datasets.
Read more5/22/2024
0
Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
Bei Liu, Haoyu Wang, Yanmin Qian
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
Read more7/23/2024