Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
2406.05359
0
0
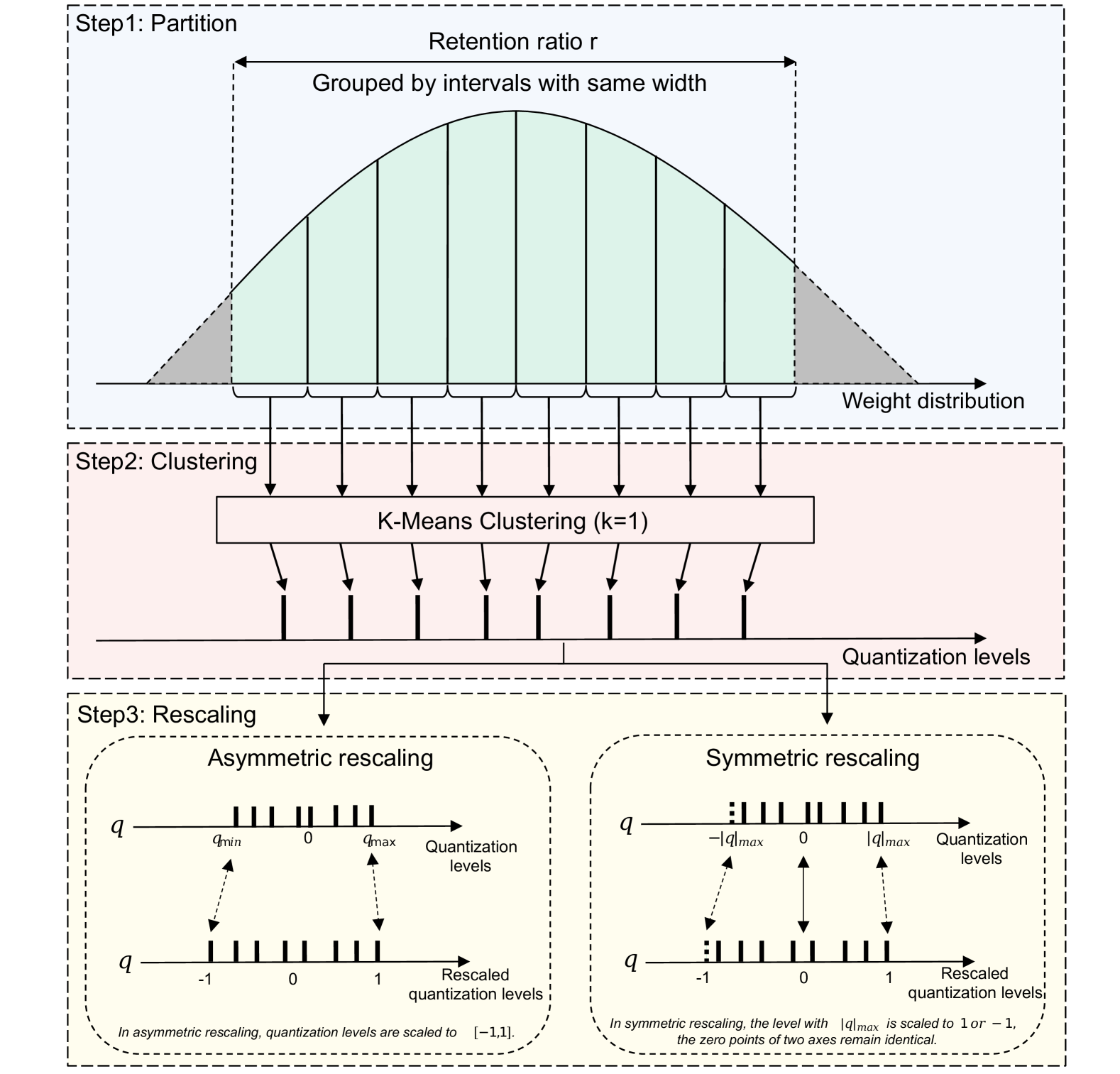
Abstract
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
Create account to get full access
Overview
- This paper explores adaptive neural network quantization techniques to develop lightweight speaker verification models.
- The researchers aim to create efficient models that can be deployed on resource-constrained devices while maintaining high accuracy.
- They investigate quantization methods, such as simple-efficient-quantization-techniques-neural-speech-coding, gradient-based-automatic-per-weight-mixed-precision, chip-hardware-aware-quantization-mixed-precision-neural, and comprehensive-evaluation-quantization-strategies-large-language-models, to reduce the model size and computational complexity without significant accuracy degradation.
Plain English Explanation
The paper focuses on developing efficient speaker verification models that can be used on devices with limited resources, such as smartphones or edge devices. Speaker verification is the process of using a person's voice to confirm their identity, similar to how fingerprints or facial recognition can be used for identification.
The researchers explore techniques called neural network quantization to make the speaker verification models smaller and faster. Quantization involves reducing the precision of the numerical values used in the neural network, which can significantly reduce the model size and computational requirements without drastically impacting the accuracy.
The researchers test different quantization methods, including simple-efficient-quantization-techniques-neural-speech-coding, gradient-based-automatic-per-weight-mixed-precision, chip-hardware-aware-quantization-mixed-precision-neural, and comprehensive-evaluation-quantization-strategies-large-language-models, to find the best balance between model size, speed, and accuracy for speaker verification tasks.
The goal is to create lightweight speaker verification models that can be deployed on devices with limited processing power, such as smartphones or smart home assistants, without sacrificing the performance of the speaker verification system.
Technical Explanation
The researchers explore adaptive neural network quantization techniques to develop lightweight speaker verification models. They start with two baseline models: ResNet and DF-ResNet, which are popular architectures for speaker verification tasks.
To reduce the model size and computational complexity, the researchers apply various quantization methods. These include:
- simple-efficient-quantization-techniques-neural-speech-coding: A straightforward approach that uniformly quantizes the weights and activations of the neural network.
- gradient-based-automatic-per-weight-mixed-precision: A method that automatically determines the optimal precision for each weight in the network during training.
- chip-hardware-aware-quantization-mixed-precision-neural: A technique that takes into account the specific hardware constraints of the target device to optimize the quantization.
- comprehensive-evaluation-quantization-strategies-large-language-models: A comprehensive evaluation of different quantization strategies, including static and dynamic quantization.
The researchers conduct experiments on popular speaker verification datasets to assess the performance of the quantized models. They measure the model size, inference time, and verification accuracy to determine the effectiveness of the quantization techniques.
The results show that the adaptive quantization methods can significantly reduce the model size and inference time while maintaining high speaker verification accuracy, making the models suitable for deployment on resource-constrained devices.
Critical Analysis
The paper provides a comprehensive evaluation of different quantization techniques for speaker verification models, which is a valuable contribution to the field. However, there are a few potential limitations and areas for further research:
- The paper focuses on only two baseline architectures (ResNet and DF-ResNet). It would be interesting to see how the quantization techniques perform on a wider range of speaker verification model architectures.
- The paper does not explore the impact of quantization on the model's robustness to noisy or challenging audio environments. Real-world speaker verification systems often need to handle a variety of environmental conditions, and the effect of quantization on this aspect should be investigated.
- The paper does not provide much insight into the trade-offs between the different quantization methods in terms of their complexity, ease of implementation, and hyperparameter tuning requirements. This information would be helpful for practitioners when choosing the most appropriate quantization approach for their specific use case.
- The paper could benefit from a more detailed discussion of the potential limitations of the proposed techniques, such as the impact of quantization on the model's generalization ability or the sensitivity to the choice of hyperparameters.
Overall, the paper presents a valuable contribution to the development of efficient speaker verification models, and the insights provided can be helpful for researchers and engineers working on deploying such models on resource-constrained devices. Further research exploring the limitations and exploring a wider range of architectures and use cases would be a valuable next step.
Conclusion
This paper explores the use of adaptive neural network quantization techniques to develop lightweight speaker verification models. The researchers investigate various quantization methods, including simple-efficient-quantization-techniques-neural-speech-coding, gradient-based-automatic-per-weight-mixed-precision, chip-hardware-aware-quantization-mixed-precision-neural, and comprehensive-evaluation-quantization-strategies-large-language-models, to find the best balance between model size, speed, and accuracy for speaker verification tasks.
The results demonstrate that the proposed adaptive quantization techniques can significantly reduce the model size and inference time while maintaining high speaker verification accuracy, making the models suitable for deployment on resource-constrained devices such as smartphones or smart home assistants. This research has the potential to enable the widespread adoption of efficient speaker verification systems in a variety of applications, from personal security to voice-controlled smart home devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Simple and Efficient Quantization Techniques for Neural Speech Coding
Andreas Brendel, Nicola Pia, Kishan Gupta, Guillaume Fuchs, Markus Multrus
0
0
Neural audio coding has emerged as a vivid research direction by promising good audio quality at very low bitrates unachievable by classical coding techniques. Here, end-to-end trainable autoencoder-like models represent the state of the art, where a discrete representation in the bottleneck of the autoencoder has to be learned that allows for efficient transmission of the input audio signal. This discrete representation is typically generated by applying a quantizer to the output of the neural encoder. In almost all state-of-the-art neural audio coding approaches, this quantizer is realized as a Vector Quantizer (VQ) and a lot of effort has been spent to alleviate drawbacks of this quantization technique when used together with a neural audio coder. In this paper, we propose simple alternatives to VQ, which are based on projected Scalar Quantization (SQ). These quantization techniques do not need any additional losses, scheduling parameters or codebook storage thereby simplifying the training of neural audio codecs. Furthermore, we propose a new causal network architecture for neural speech coding that shows good performance at very low computational complexity.
5/15/2024
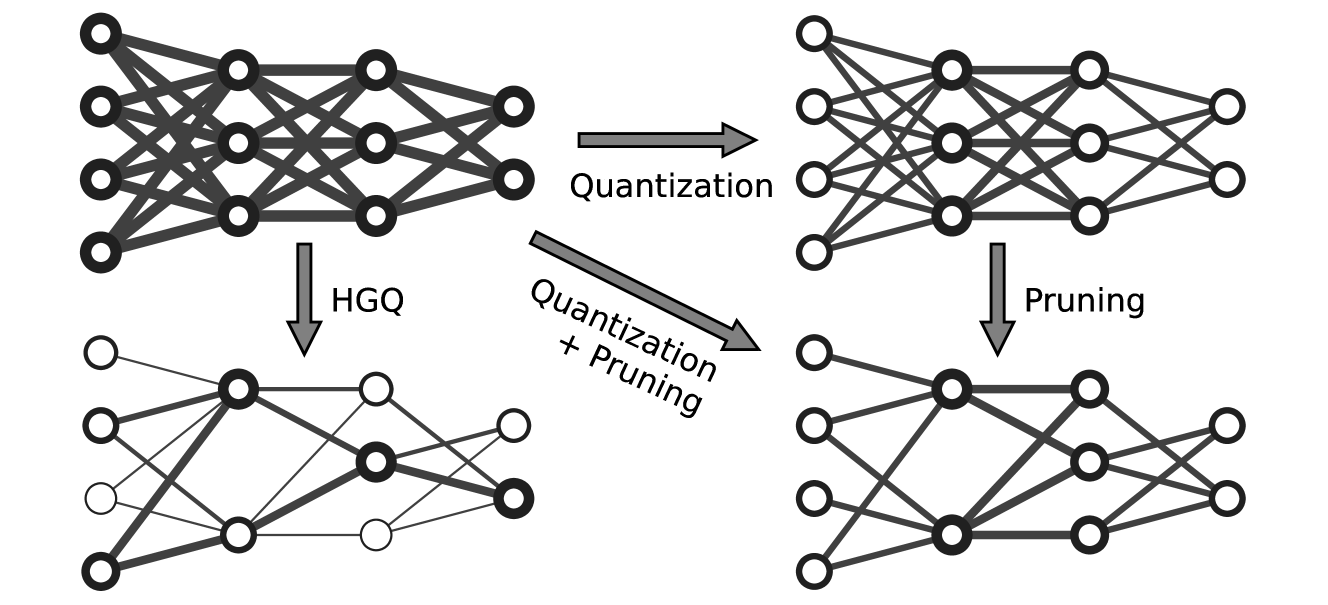
Gradient-based Automatic Per-Weight Mixed Precision Quantization for Neural Networks On-Chip
Chang Sun, Thea K. {AA}rrestad, Vladimir Loncar, Jennifer Ngadiuba, Maria Spiropulu
0
0
Model size and inference speed at deployment time, are major challenges in many deep learning applications. A promising strategy to overcome these challenges is quantization. However, a straightforward uniform quantization to very low precision can result in significant accuracy loss. Mixed-precision quantization, based on the idea that certain parts of the network can accommodate lower precision without compromising performance compared to other parts, offers a potential solution. In this work, we present High Granularity Quantization (HGQ), an innovative quantization-aware training method designed to fine-tune the per-weight and per-activation precision in an automatic way for ultra-low latency and low power neural networks which are to be deployed on FPGAs. We demonstrate that HGQ can outperform existing methods by a substantial margin, achieving resource reduction by up to a factor of 20 and latency improvement by a factor of 5 while preserving accuracy.
5/2/2024
🧠
On-Chip Hardware-Aware Quantization for Mixed Precision Neural Networks
Wei Huang, Haotong Qin, Yangdong Liu, Jingzhuo Liang, Yulun Zhang, Ying Li, Xianglong Liu
0
0
Low-bit quantization emerges as one of the most promising compression approaches for deploying deep neural networks on edge devices. Mixed-precision quantization leverages a mixture of bit-widths to unleash the accuracy and efficiency potential of quantized models. However, existing mixed-precision quantization methods rely on simulations in high-performance devices to achieve accuracy and efficiency trade-offs in immense search spaces. This leads to a non-negligible gap between the estimated efficiency metrics and the actual hardware that makes quantized models far away from the optimal accuracy and efficiency, and also causes the quantization process to rely on additional high-performance devices. In this paper, we propose an On-Chip Hardware-Aware Quantization (OHQ) framework, performing hardware-aware mixed-precision quantization on deployed edge devices to achieve accurate and efficient computing. Specifically, for efficiency metrics, we built an On-Chip Quantization Aware pipeline, which allows the quantization process to perceive the actual hardware efficiency of the quantization operator and avoid optimization errors caused by inaccurate simulation. For accuracy metrics, we propose Mask-Guided Quantization Estimation technology to effectively estimate the accuracy impact of operators in the on-chip scenario, getting rid of the dependence of the quantization process on high computing power. By synthesizing insights from quantized models and hardware through linear optimization, we can obtain optimized bit-width configurations to achieve outstanding performance on accuracy and efficiency. We evaluate inference accuracy and acceleration with quantization for various architectures and compression ratios on hardware. OHQ achieves 70% and 73% accuracy for ResNet-18 and MobileNetV3, respectively, and can reduce latency by 15~30% compared to INT8 on real deployment.
5/24/2024
🏋️
AdaQAT: Adaptive Bit-Width Quantization-Aware Training
C'edric Gernigon (TARAN), Silviu-Ioan Filip (TARAN), Olivier Sentieys (TARAN), Cl'ement Coggiola (CNES), Mickael Bruno (CNES)
0
0
Large-scale deep neural networks (DNNs) have achieved remarkable success in many application scenarios. However, high computational complexity and energy costs of modern DNNs make their deployment on edge devices challenging. Model quantization is a common approach to deal with deployment constraints, but searching for optimized bit-widths can be challenging. In this work, we present Adaptive Bit-Width Quantization Aware Training (AdaQAT), a learning-based method that automatically optimizes weight and activation signal bit-widths during training for more efficient DNN inference. We use relaxed real-valued bit-widths that are updated using a gradient descent rule, but are otherwise discretized for all quantization operations. The result is a simple and flexible QAT approach for mixed-precision uniform quantization problems. Compared to other methods that are generally designed to be run on a pretrained network, AdaQAT works well in both training from scratch and fine-tuning scenarios.Initial results on the CIFAR-10 and ImageNet datasets using ResNet20 and ResNet18 models, respectively, indicate that our method is competitive with other state-of-the-art mixed-precision quantization approaches.
4/29/2024