Near-Optimal Policy Optimization for Correlated Equilibrium in General-Sum Markov Games
2401.15240
0
0
🛠️
Abstract
We study policy optimization algorithms for computing correlated equilibria in multi-player general-sum Markov Games. Previous results achieve $O(T^{-1/2})$ convergence rate to a correlated equilibrium and an accelerated $O(T^{-3/4})$ convergence rate to the weaker notion of coarse correlated equilibrium. In this paper, we improve both results significantly by providing an uncoupled policy optimization algorithm that attains a near-optimal $tilde{O}(T^{-1})$ convergence rate for computing a correlated equilibrium. Our algorithm is constructed by combining two main elements (i) smooth value updates and (ii) the optimistic-follow-the-regularized-leader algorithm with the log barrier regularizer.
Create account to get full access
Overview
- Presents a new approach for training multi-agent systems to converge to correlated equilibria in normal-form games
- Builds on prior work on learning in normal-form games and coupled optimization frameworks for correlated equilibria
- Proposes a novel "multi-agent training beyond zero-sum" algorithm that can converge to correlated equilibria in more general games
Plain English Explanation
This research paper introduces a new method for training multi-agent systems to reach a type of balanced outcome called a correlated equilibrium in normal-form games. Normal-form games are mathematical models that capture strategic interactions between multiple decision-makers or "agents."
The key innovation is an algorithm called "multi-agent training beyond zero-sum" that can find correlated equilibria even in more complex games that are not strictly zero-sum. Correlated equilibria are a generalization of the classic Nash equilibrium that allows for more nuanced coordination between agents.
By developing this new training approach, the authors aim to expand the applicability of multi-agent reinforcement learning to a broader class of real-world scenarios beyond purely competitive games. The techniques could have implications for areas like multi-agent robotics, traffic management, and other domains involving complex, interacting decision-makers.
Technical Explanation
The paper builds on prior work on learning in normal-form games and coupled optimization frameworks for correlated equilibria. It proposes a novel "multi-agent training beyond zero-sum" algorithm that can converge to correlated equilibria in more general normal-form games.
The key technical contributions include:
- Formalizing a new class of "beyond zero-sum" normal-form games that generalize the classic zero-sum setting.
- Developing a training framework that leverages "correlation devices" to enable agents to converge to correlated equilibria, even in these more complex games.
- Providing theoretical guarantees on the convergence of this training process to approximate correlated equilibria.
- Demonstrating the effectiveness of the approach through experiments on synthetic normal-form games as well as more realistic multi-agent navigation scenarios.
Critical Analysis
The paper makes a compelling case for the benefits of correlated equilibria in multi-agent systems and presents a novel algorithmic approach for reaching such outcomes. However, some potential limitations and areas for further research are worth noting:
- The theoretical convergence guarantees are based on certain simplifying assumptions, like the availability of a "correlation device." Relaxing these assumptions could be an interesting direction for future work.
- The experimental evaluations, while promising, are still relatively limited in scope. Assessing the scalability and robustness of the approach in larger, more complex normal-form games would be valuable.
- The paper does not deeply explore potential negative societal impacts or ethical considerations around the use of these techniques, which could be an important area for further investigation.
Overall, this research represents a valuable contribution to the field of multi-agent reinforcement learning, with the potential to expand the applicability of these techniques to a broader range of real-world scenarios.
Conclusion
This paper presents a new algorithmic approach for training multi-agent systems to converge to correlated equilibria in normal-form games. By going "beyond zero-sum," the proposed "multi-agent training beyond zero-sum" algorithm can find more nuanced, coordinated outcomes that generalize the classic Nash equilibrium concept.
The work builds on prior research in normal-form game learning and coupled optimization frameworks for correlated equilibria. The authors provide theoretical guarantees on the convergence of their approach and demonstrate its effectiveness through experiments on synthetic and more realistic multi-agent scenarios.
While the paper has some limitations, it represents an important step forward in expanding the capabilities of multi-agent reinforcement learning systems. The techniques could have significant implications for a wide range of real-world applications involving complex, interacting decision-makers.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
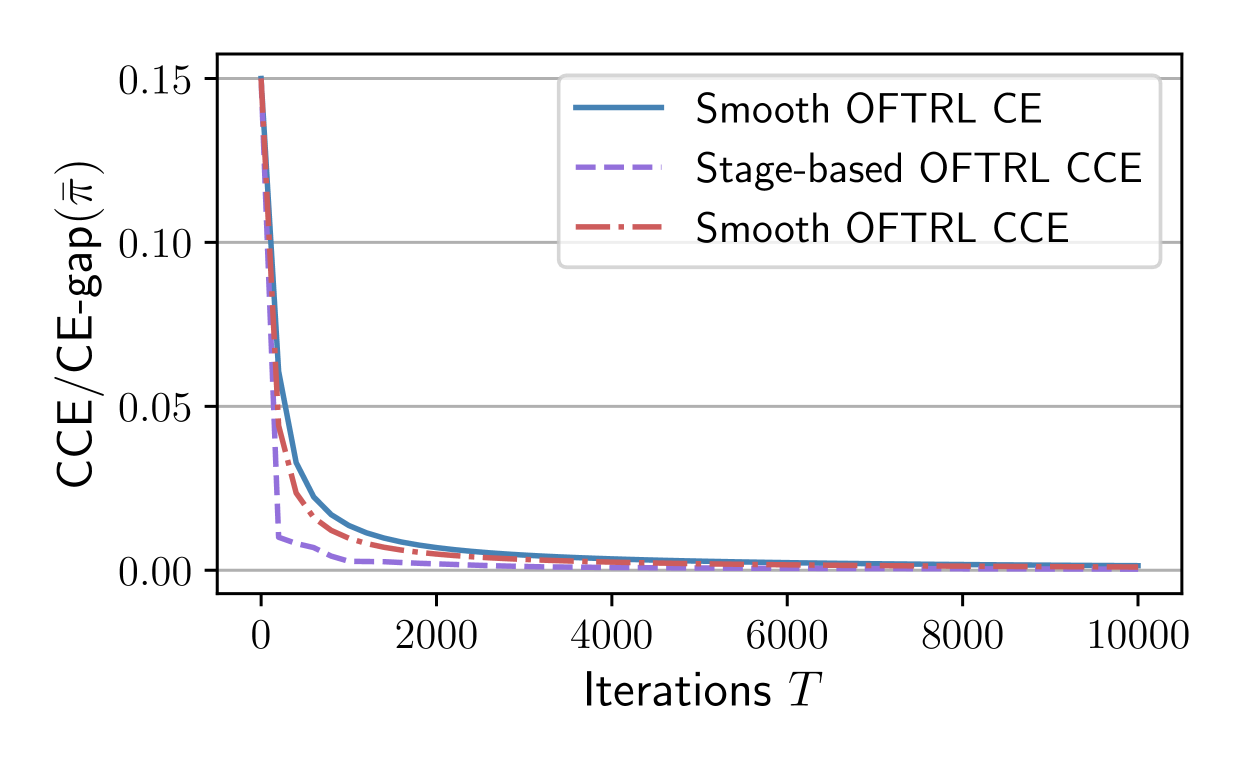
$widetilde{O}(T^{-1})$ Convergence to (Coarse) Correlated Equilibria in Full-Information General-Sum Markov Games
Weichao Mao, Haoran Qiu, Chen Wang, Hubertus Franke, Zbigniew Kalbarczyk, Tamer Bac{s}ar
0
0
No-regret learning has a long history of being closely connected to game theory. Recent works have devised uncoupled no-regret learning dynamics that, when adopted by all the players in normal-form games, converge to various equilibrium solutions at a near-optimal rate of $widetilde{O}(T^{-1})$, a significant improvement over the $O(1/sqrt{T})$ rate of classic no-regret learners. However, analogous convergence results are scarce in Markov games, a more generic setting that lays the foundation for multi-agent reinforcement learning. In this work, we close this gap by showing that the optimistic-follow-the-regularized-leader (OFTRL) algorithm, together with appropriate value update procedures, can find $widetilde{O}(T^{-1})$-approximate (coarse) correlated equilibria in full-information general-sum Markov games within $T$ iterations. Numerical results are also included to corroborate our theoretical findings.
4/24/2024

A Coupled Optimization Framework for Correlated Equilibria in Normal-Form Game
Sarah H. Q. Li, Yue Yu, Florian Dorfler, John Lygeros
0
0
In competitive multi-player interactions, simultaneous optimality is a key requirement for establishing strategic equilibria. This property is explicit when the game-theoretic equilibrium is the simultaneously optimal solution of coupled optimization problems. However, no such optimization problems exist for the correlated equilibrium, a strategic equilibrium where the players can correlate their actions. We address the lack of a coupled optimization framework for the correlated equilibrium by introducing an {unnormalized game} -- an extension of normal-form games in which the player strategies are lifted to unnormalized measures over the joint actions. We show that the set of fully mixed generalized Nash equilibria of this unnormalized game is a subset of the correlated equilibrium of the normal-form game. Furthermore, we introduce an entropy regularization to the unnormalized game and prove that the entropy-regularized generalized Nash equilibrium is a sub-optimal correlated equilibrium of the normal form game where the degree of sub-optimality depends on the magnitude of regularization. We prove that the entropy-regularized unnormalized game has a closed-form solution, and empirically verify its computational efficacy at approximating the correlated equilibrium of normal-form games.
4/4/2024
🏋️
Multi-Agent Training beyond Zero-Sum with Correlated Equilibrium Meta-Solvers
Luke Marris, Paul Muller, Marc Lanctot, Karl Tuyls, Thore Graepel
0
0
Two-player, constant-sum games are well studied in the literature, but there has been limited progress outside of this setting. We propose Joint Policy-Space Response Oracles (JPSRO), an algorithm for training agents in n-player, general-sum extensive form games, which provably converges to an equilibrium. We further suggest correlated equilibria (CE) as promising meta-solvers, and propose a novel solution concept Maximum Gini Correlated Equilibrium (MGCE), a principled and computationally efficient family of solutions for solving the correlated equilibrium selection problem. We conduct several experiments using CE meta-solvers for JPSRO and demonstrate convergence on n-player, general-sum games.
4/19/2024
🔍
Learning Nash Equilibria in Zero-Sum Markov Games: A Single Time-scale Algorithm Under Weak Reachability
Reda Ouhamma, Maryam Kamgarpour
0
0
We consider decentralized learning for zero-sum games, where players only see their payoff information and are agnostic to actions and payoffs of the opponent. Previous works demonstrated convergence to a Nash equilibrium in this setting using double time-scale algorithms under strong reachability assumptions. We address the open problem of achieving an approximate Nash equilibrium efficiently with an uncoupled and single time-scale algorithm under weaker conditions. Our contribution is a rational and convergent algorithm, utilizing Tsallis-entropy regularization in a value-iteration-based approach. The algorithm learns an approximate Nash equilibrium in polynomial time, requiring only the existence of a policy pair that induces an irreducible and aperiodic Markov chain, thus considerably weakening past assumptions. Our analysis leverages negative drift inequalities and introduces novel properties of Tsallis entropy that are of independent interest.
5/27/2024