Needle in the Haystack for Memory Based Large Language Models
2407.01437
0
0
💬
Abstract
In this paper, we demonstrate the benefits of using memory augmented Large Language Model (LLM) architecture in improving the recall abilities of facts from a potentially long context. As a case study we test LARIMAR, a recently proposed LLM architecture which augments a LLM decoder with an external associative memory, on several long-context recall tasks, including passkey and needle-in-the-haystack tests. We demonstrate that the external memory can be adapted at test time to handle contexts much longer than those seen during training, while keeping readouts from the memory recognizable to the trained decoder and without increasing GPU memory footprint. Compared to alternative architectures for long-context recall tasks with models of a comparable parameter count, LARIMAR is able to maintain strong performance without any task-specific training.
Create account to get full access
Overview
- This paper explores the challenge of retrieving specific, contextual information from large language models (LLMs) trained on vast amounts of data.
- The authors investigate how the performance of LLMs in recalling relevant information is influenced by the prompts used to query them.
- The research aims to better understand the factors that affect the "needle in the haystack" problem, where LLMs struggle to retrieve precise, contextual details from their expansive knowledge bases.
Plain English Explanation
Large language models (LLMs) like GPT-3 have access to an incredible amount of information, but retrieving specific details from this knowledge can be challenging. It's like trying to find a "needle in a haystack" - the models have so much data that pinpointing the right piece of information can be difficult.
This paper explores how the way you ask LLMs for information, through the prompts you give them, can impact their ability to recall relevant, contextual details. The researchers wanted to better understand the factors that affect this "needle in the haystack" problem and find ways to help LLMs retrieve more precise information from their vast knowledge bases.
By conducting various experiments, the authors shed light on how different prompts can lead LLMs to either successfully retrieve the right information or miss the mark entirely. This research is an important step in improving the long-context capabilities of LLMs and enabling them to share and leverage memories more effectively.
Technical Explanation
The paper investigates how the prompts used to query large language models (LLMs) affect their ability to retrieve relevant, contextual information from their expansive knowledge bases. This is known as the "needle in the haystack" problem, where LLMs struggle to pinpoint specific details amidst their wealth of information.
Through a series of experiments, the authors tested how different prompt characteristics, such as length, structure, and specificity, influenced the performance of LLMs in recalling relevant details. They found that prompt design can significantly impact an LLM's ability to retrieve the "needle" of contextual information from the "haystack" of its knowledge.
The researchers also explored approaches to improve the long-context capabilities of LLMs and enable them to share and leverage memories more effectively. This work contributes to a better understanding of the factors that affect the "needle in the haystack" problem and how to address the aspects of human memory that large language models currently struggle with.
Critical Analysis
The paper provides valuable insights into the "needle in the haystack" problem, but it also acknowledges several limitations and areas for further research. The authors note that their experiments were conducted on a single LLM, and the findings may not generalize to other models or domains.
Additionally, the paper does not explore the potential biases or ethical implications of LLMs being heavily influenced by prompt design. There is a risk that prompts could be crafted to elicit specific, potentially harmful responses from the models.
Further research is needed to better understand the long-term effects of prompt-based information retrieval on the development and deployment of large language models. Addressing the "needle in the haystack" problem is important, but it must be done in a responsible and transparent manner to ensure the safe and ethical use of these powerful AI systems.
Conclusion
This paper provides valuable insights into the "needle in the haystack" problem, where large language models (LLMs) struggle to retrieve specific, contextual information from their vast knowledge bases. The authors demonstrate that the prompts used to query LLMs can significantly impact their ability to recall relevant details.
By shedding light on the factors that affect prompt-based information retrieval, this research contributes to a better understanding of the limitations and challenges faced by LLMs. The findings can inform the development of strategies to improve the long-context capabilities of these models and enable more effective memory sharing and leveraging.
As large language models continue to advance, it will be crucial to address the "needle in the haystack" problem and ensure that they can reliably retrieve the precise information needed to provide accurate and reliable outputs. This research lays the groundwork for further exploration and innovation in this critical area of AI development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models
Hengyi Wang, Haizhou Shi, Shiwei Tan, Weiyi Qin, Wenyuan Wang, Tunyu Zhang, Akshay Nambi, Tanuja Ganu, Hao Wang
0
0
Multimodal Large Language Models (MLLMs) have shown significant promise in various applications, leading to broad interest from researchers and practitioners alike. However, a comprehensive evaluation of their long-context capabilities remains underexplored. To address these gaps, we introduce the MultiModal Needle-in-a-haystack (MMNeedle) benchmark, specifically designed to assess the long-context capabilities of MLLMs. Besides multi-image input, we employ image stitching to further increase the input context length, and develop a protocol to automatically generate labels for sub-image level retrieval. Essentially, MMNeedle evaluates MLLMs by stress-testing their capability to locate a target sub-image (needle) within a set of images (haystack) based on textual instructions and descriptions of image contents. This setup necessitates an advanced understanding of extensive visual contexts and effective information retrieval within long-context image inputs. With this benchmark, we evaluate state-of-the-art MLLMs, encompassing both API-based and open-source models. The findings reveal that GPT-4o consistently surpasses other models in long-context scenarios, but suffers from hallucination problems in negative samples, i.e., when needles are not in the haystacks. Our comprehensive long-context evaluation of MLLMs also sheds lights on the considerable performance gap between API-based and open-source models. All the code, data, and instructions required to reproduce the main results are available at https://github.com/Wang-ML-Lab/multimodal-needle-in-a-haystack.
6/18/2024
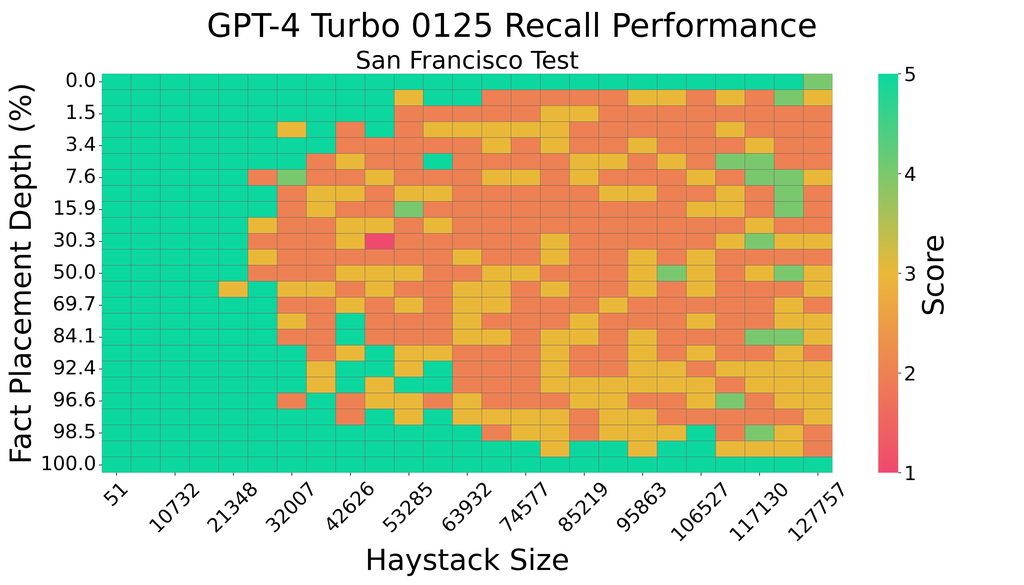
LLM In-Context Recall is Prompt Dependent
Daniel Machlab, Rick Battle
0
0
The proliferation of Large Language Models (LLMs) highlights the critical importance of conducting thorough evaluations to discern their comparative advantages, limitations, and optimal use cases. Particularly important is assessing their capacity to accurately retrieve information included in a given prompt. A model's ability to do this significantly influences how effectively it can utilize contextual details, thus impacting its practical efficacy and dependability in real-world applications. Our research analyzes the in-context recall performance of various LLMs using the needle-in-a-haystack method. In this approach, a factoid (the needle) is embedded within a block of filler text (the haystack), which the model is asked to retrieve. We assess the recall performance of each model across various haystack lengths and with varying needle placements to identify performance patterns. This study demonstrates that an LLM's recall capability is not only contingent upon the prompt's content but also may be compromised by biases in its training data. Conversely, adjustments to model architecture, training strategy, or fine-tuning can improve performance. Our analysis provides insight into LLM behavior, offering direction for the development of more effective applications of LLMs.
4/16/2024
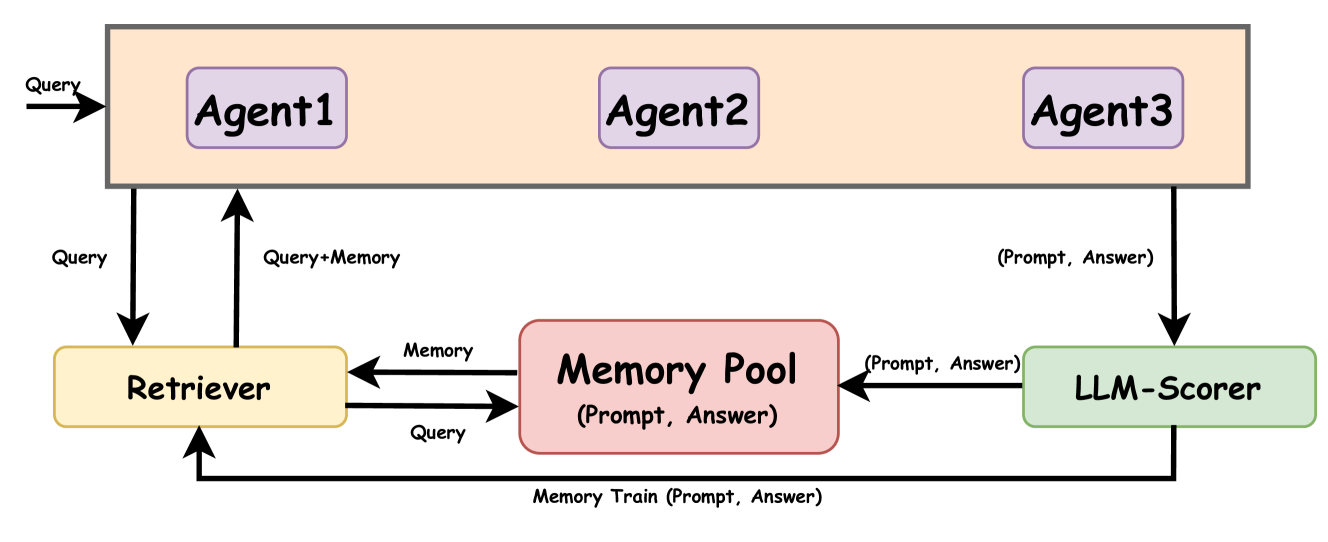
Memory Sharing for Large Language Model based Agents
Hang Gao, Yongfeng Zhang
0
0
In the realm of artificial intelligence, the adaptation of Large Language Model (LLM)-based agents to execute tasks via natural language prompts represents a significant advancement, notably eliminating the need for explicit retraining or fine tuning for fixed-answer tasks such as common sense questions and yes/no queries. However, the application of In-context Learning to open-ended challenges, such as poetry creation, reveals substantial limitations due to the comprehensiveness of the provided examples and agent's ability to understand the content expressed in the problem, leading to outputs that often diverge significantly from expected results. Addressing this gap, our study introduces the Memory-Sharing (MS) framework for LLM multi-agents, which utilizes a real-time memory storage and retrieval system to enhance the In-context Learning process. Each memory within this system captures both the posed query and the corresponding real-time response from an LLM-based agent, aggregating these memories from a broad spectrum of similar agents to enrich the memory pool shared by all agents. This framework not only aids agents in identifying the most relevant examples for specific tasks but also evaluates the potential utility of their memories for future applications by other agents. Empirical validation across three distinct domains involving specialized functions of agents demonstrates that the MS framework significantly improve the agent's performance regrading the open-ended questions. Furthermore, we also discuss what type of memory pool and what retrieval strategy in MS can better help agents, offering a future develop direction of MS. The code and data are available at: https://github.com/GHupppp/MemorySharingLLM
4/16/2024
📊
From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
Zheyang Xiong, Vasilis Papageorgiou, Kangwook Lee, Dimitris Papailiopoulos
0
0
Recent studies have shown that Large Language Models (LLMs) struggle to accurately retrieve information and maintain reasoning capabilities when processing long-context inputs. To address these limitations, we propose a finetuning approach utilizing a carefully designed synthetic dataset comprising numerical key-value retrieval tasks. Our experiments on models like GPT-3.5 Turbo and Mistral 7B demonstrate that finetuning LLMs on this dataset significantly improves LLMs' information retrieval and reasoning capabilities in longer-context settings. We present an analysis of the finetuned models, illustrating the transfer of skills from synthetic to real task evaluations (e.g., $10.5%$ improvement on $20$ documents MDQA at position $10$ for GPT-3.5 Turbo). We also find that finetuned LLMs' performance on general benchmarks remains almost constant while LLMs finetuned on other baseline long-context augmentation data can encourage hallucination (e.g., on TriviaQA, Mistral 7B finetuned on our synthetic data cause no performance drop while other baseline data can cause a drop that ranges from $2.33%$ to $6.19%$). Our study highlights the potential of finetuning on synthetic data for improving the performance of LLMs on longer-context tasks.
6/28/2024