LLM In-Context Recall is Prompt Dependent
2404.08865
0
0
Abstract
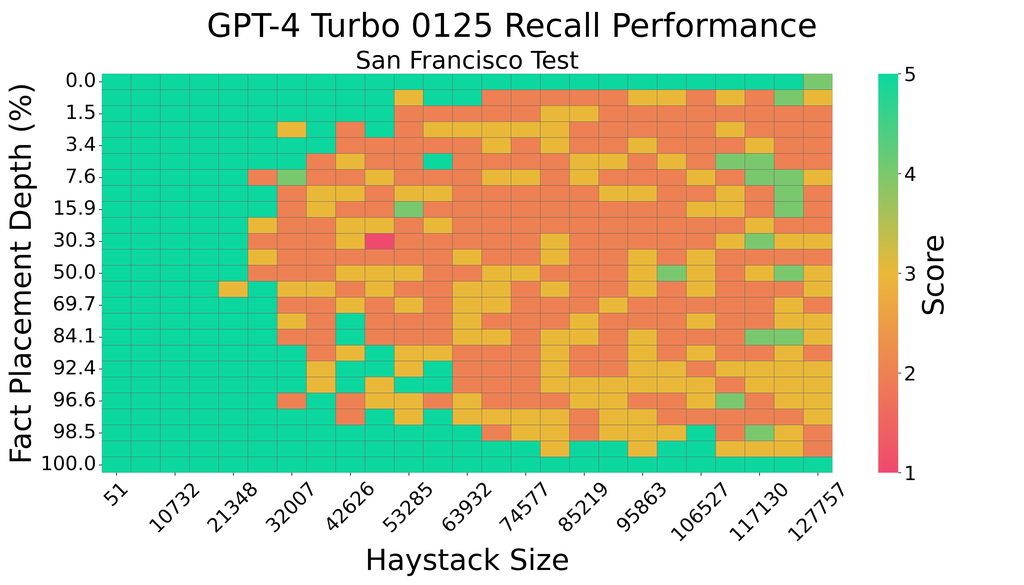
The proliferation of Large Language Models (LLMs) highlights the critical importance of conducting thorough evaluations to discern their comparative advantages, limitations, and optimal use cases. Particularly important is assessing their capacity to accurately retrieve information included in a given prompt. A model's ability to do this significantly influences how effectively it can utilize contextual details, thus impacting its practical efficacy and dependability in real-world applications. Our research analyzes the in-context recall performance of various LLMs using the needle-in-a-haystack method. In this approach, a factoid (the needle) is embedded within a block of filler text (the haystack), which the model is asked to retrieve. We assess the recall performance of each model across various haystack lengths and with varying needle placements to identify performance patterns. This study demonstrates that an LLM's recall capability is not only contingent upon the prompt's content but also may be compromised by biases in its training data. Conversely, adjustments to model architecture, training strategy, or fine-tuning can improve performance. Our analysis provides insight into LLM behavior, offering direction for the development of more effective applications of LLMs.
Create account to get full access
Overview
- This paper examines how the performance of large language models (LLMs) in recalling information is influenced by the specific prompts used to elicit that information.
- The researchers conducted experiments to test the impact of different prompts on the in-context recall capabilities of LLMs.
- The findings suggest that LLM performance on recall tasks is highly dependent on the wording and structure of the prompts provided.
Plain English Explanation
The paper investigates how the way a question is phrased can affect how well a large language model, like GPT-3 or BERT, is able to recall information that was provided to it earlier. The researchers ran a series of experiments where they gave the language models different versions of the same basic prompt and then measured how accurately the models could recall specific details.
The key finding is that the model's performance on these recall tasks can vary significantly depending on the exact wording and structure of the prompt. Subtle changes to the prompt, like using different vocabulary or rephrasing the question, can lead to big differences in how well the model is able to retrieve and regurgitate the information it was given earlier.
This indicates that the in-context recall capabilities of large language models are quite [object Object]. The models don't just have a fixed, universal ability to recall information - their performance is heavily influenced by the specific way the question is asked. This is an important consideration when using these models for tasks that require accurate recall, like question-answering or summarization.
Technical Explanation
The researchers conducted a series of experiments to test how the wording of prompts affects the in-context recall performance of large language models. They sourced a dataset of passages from the [object Object] paper, which contained short text passages along with specific details that language models were tasked with recalling.
The researchers then created multiple variants of the prompts used to elicit recall of these details, manipulating factors like vocabulary, sentence structure, and question phrasing. They fed these different prompts to large language models like GPT-3 and measured the models' accuracy in recalling the target information.
The results showed that the model's recall performance was highly [object Object]. Even small changes to the prompts could lead to significant differences in the models' ability to correctly retrieve and reproduce the requested details. This suggests that the in-context recall capabilities of LLMs are not a fixed, universal skill, but are heavily influenced by the specific wording used to prompt the model.
Critical Analysis
The paper provides compelling evidence that the in-context recall performance of large language models is highly dependent on the prompts used to elicit that recall. This is an important finding, as it highlights a key limitation of these models - their ability to retrieve and reproduce information is not a monolithic capability, but is significantly affected by the way the task is framed.
One potential criticism is that the study only looked at a limited set of prompts and a specific dataset of passages. It's possible that the degree of prompt dependence could vary depending on the domain, complexity of the information, or other factors. Further research would be needed to assess the generalizability of these findings.
Additionally, the paper does not explore the underlying reasons why LLM recall is so prompt-dependent. Are there particular linguistic or cognitive factors that make these models sensitive to prompt wording? Investigating the mechanisms behind this phenomenon could lead to valuable insights.
Overall, this research raises important questions about the [object Object]. It suggests that practitioners need to be cautious when relying on these models for applications like [object Object], where precise retrieval of information is critical. Further study of prompt dependence and ways to mitigate its effects could lead to more robust and reliable applications of large language models.
Conclusion
This paper presents a compelling demonstration that the in-context recall performance of large language models is heavily dependent on the specific prompts used to elicit that recall. The researchers found that even minor changes to the wording and structure of prompts could lead to significant variations in how accurately the models were able to retrieve and reproduce details from provided information.
These findings highlight an important limitation of current large language models - their recall capabilities are not a fixed, universal skill, but are highly sensitive to the framing of the task. This is a critical consideration for anyone seeking to use these models for applications that require precise and reliable information retrieval, such as question-answering or summarization.
Further research is needed to better understand the underlying factors that drive this prompt dependence, as well as strategies to mitigate its effects. But this paper provides a valuable contribution by shedding light on this crucial characteristic of large language models, and the implications it has for their real-world deployment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
New!Needle in the Haystack for Memory Based Large Language Models
Subhajit Chaudhury, Soham Dan, Payel Das, Georgios Kollias, Elliot Nelson
0
0
In this paper, we demonstrate the benefits of using memory augmented Large Language Model (LLM) architecture in improving the recall abilities of facts from a potentially long context. As a case study we test LARIMAR, a recently proposed LLM architecture which augments a LLM decoder with an external associative memory, on several long-context recall tasks, including passkey and needle-in-the-haystack tests. We demonstrate that the external memory can be adapted at test time to handle contexts much longer than those seen during training, while keeping readouts from the memory recognizable to the trained decoder and without increasing GPU memory footprint. Compared to alternative architectures for long-context recall tasks with models of a comparable parameter count, LARIMAR is able to maintain strong performance without any task-specific training.
7/2/2024
🧠
Towards a Holistic Evaluation of LLMs on Factual Knowledge Recall
Jiaqing Yuan, Lin Pan, Chung-Wei Hang, Jiang Guo, Jiarong Jiang, Bonan Min, Patrick Ng, Zhiguo Wang
0
0
Large language models (LLMs) have shown remarkable performance on a variety of NLP tasks, and are being rapidly adopted in a wide range of use cases. It is therefore of vital importance to holistically evaluate the factuality of their generated outputs, as hallucinations remain a challenging issue. In this work, we focus on assessing LLMs' ability to recall factual knowledge learned from pretraining, and the factors that affect this ability. To that end, we construct FACT-BENCH, a representative benchmark covering 20 domains, 134 property types, 3 answer types, and different knowledge popularity levels. We benchmark 31 models from 10 model families and provide a holistic assessment of their strengths and weaknesses. We observe that instruction-tuning hurts knowledge recall, as pretraining-only models consistently outperform their instruction-tuned counterparts, and positive effects of model scaling, as larger models outperform smaller ones for all model families. However, the best performance from GPT-4 still represents a large gap with the upper-bound. We additionally study the role of in-context exemplars using counterfactual demonstrations, which lead to significant degradation of factual knowledge recall for large models. By further decoupling model known and unknown knowledge, we find the degradation is attributed to exemplars that contradict a model's known knowledge, as well as the number of such exemplars. Lastly, we fine-tune LLaMA-7B in different settings of known and unknown knowledge. In particular, fine-tuning on a model's known knowledge is beneficial, and consistently outperforms fine-tuning on unknown and mixed knowledge. We will make our benchmark publicly available.
4/26/2024
🤔
Shortcomings of LLMs for Low-Resource Translation: Retrieval and Understanding are Both the Problem
Sara Court, Micha Elsner
0
0
This work investigates the in-context learning abilities of pretrained large language models (LLMs) when instructed to translate text from a low-resource language into a high-resource language as part of an automated machine translation pipeline. We conduct a set of experiments translating Southern Quechua to Spanish and examine the informativity of various types of information retrieved from a constrained database of digitized pedagogical materials (dictionaries and grammar lessons) and parallel corpora. Using both automatic and human evaluation of model output, we conduct ablation studies that manipulate (1) context type (morpheme translations, grammar descriptions, and corpus examples), (2) retrieval methods (automated vs. manual), and (3) model type. Our results suggest that even relatively small LLMs are capable of utilizing prompt context for zero-shot low-resource translation when provided a minimally sufficient amount of relevant linguistic information. However, the variable effects of prompt type, retrieval method, model type, and language-specific factors highlight the limitations of using even the best LLMs as translation systems for the majority of the world's 7,000+ languages and their speakers.
6/26/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024