The Neglected Tails in Vision-Language Models
2401.12425
0
0

Abstract
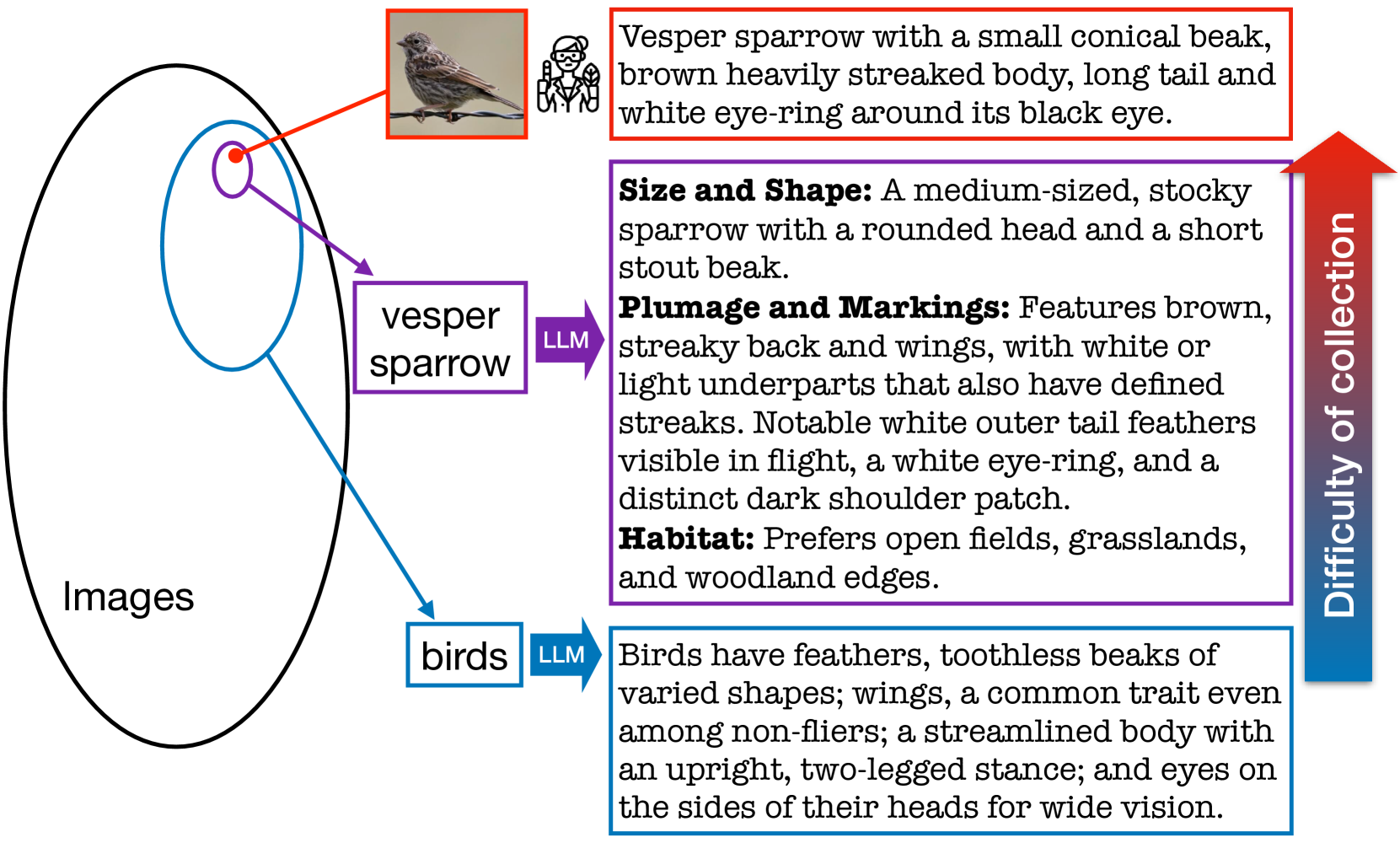
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
Create account to get full access
Overview
• This paper investigates the long-tailed distribution of concepts in vision-language models, where a small number of common concepts dominate while many less frequent concepts are neglected.
• The authors propose a method to estimate the true concept frequency distribution and use this to improve the performance of vision-language models on rare and unseen concepts.
• Key ideas include concept frequency estimation, modifying training objectives, and fine-tuning techniques to address the long-tailed concept distribution.
Plain English Explanation
Vision-language models are AI systems that can understand and generate text based on visual inputs. These models are often trained on large datasets, but the distribution of concepts they learn is skewed - a few common concepts make up the majority, while many less frequent concepts are rarely seen.
This "long-tailed" distribution can cause issues, as the models may perform poorly on rare or unseen concepts. The authors of this paper propose ways to better estimate the true frequency of different concepts, and then use that information to improve the models' performance on the neglected "tails" of the concept distribution.
By modifying the training objectives and fine-tuning the models, the researchers were able to boost performance on uncommon concepts without sacrificing accuracy on the more common ones. This could make vision-language models more robust and applicable to a wider range of real-world scenarios.
Technical Explanation
The paper starts by analyzing the long-tailed distribution of concepts in typical vision-language model training data. The authors propose a method to estimate the true frequency of different concepts, going beyond just using the observed counts in the dataset.
They then explore ways to leverage this estimated concept frequency information to improve model performance. This includes modifying the training objectives to give more weight to rare concepts, as well as fine-tuning techniques that focus on improving predictions for low-frequency concepts.
The key experiments demonstrate that these approaches can substantially boost zero-shot classification accuracy on rare and unseen concepts, while maintaining strong performance on more common ones. The authors also analyze failure cases and discuss future research directions to further address the long-tailed concept distribution challenge.
Critical Analysis
The paper provides a thoughtful analysis of an important issue in vision-language models - their tendency to focus on common concepts at the expense of rare or unseen ones. The proposed solutions, while not a complete fix, represent a meaningful step forward in addressing this problem.
One potential limitation is that the techniques may require additional computational resources or data to implement, which could be a barrier for some use cases. Additionally, the paper acknowledges that the proposed methods may not be able to fully eliminate the performance gap between common and rare concepts.
Further research could explore alternative approaches, such as more advanced few-shot or zero-shot learning techniques, to see if the long-tailed distribution challenge can be tackled from other angles. Investigating the impacts of dataset curation and model architectural choices could also yield valuable insights.
Overall, this paper makes an important contribution by shining a light on the "neglected tails" of vision-language models and proposing concrete steps to improve their handling of rare and unseen concepts.
Conclusion
This paper highlights the long-tailed distribution of concepts in vision-language models, where a small number of common concepts dominate while many less frequent concepts are neglected. The authors propose methods to better estimate true concept frequencies and use this information to improve model performance on the "tails" of the distribution.
The techniques demonstrated, including modified training objectives and fine-tuning approaches, show promise in boosting zero-shot classification accuracy on rare and unseen concepts without sacrificing performance on more common ones. While not a complete solution, this research represents an important step forward in making vision-language models more robust and applicable across a wider range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improved Zero-Shot Classification by Adapting VLMs with Text Descriptions
Oindrila Saha, Grant Van Horn, Subhransu Maji
0
0
The zero-shot performance of existing vision-language models (VLMs) such as CLIP is limited by the availability of large-scale, aligned image and text datasets in specific domains. In this work, we leverage two complementary sources of information -- descriptions of categories generated by large language models (LLMs) and abundant, fine-grained image classification datasets -- to improve the zero-shot classification performance of VLMs across fine-grained domains. On the technical side, we develop methods to train VLMs with this bag-level image-text supervision. We find that simply using these attributes at test-time does not improve performance, but our training strategy, for example, on the iNaturalist dataset, leads to an average improvement of 4-5% in zero-shot classification accuracy for novel categories of birds and flowers. Similar improvements are observed in domains where a subset of the categories was used to fine-tune the model. By prompting LLMs in various ways, we generate descriptions that capture visual appearance, habitat, and geographic regions and pair them with existing attributes such as the taxonomic structure of the categories. We systematically evaluate their ability to improve zero-shot categorization in natural domains. Our findings suggest that geographic priors can be just as effective and are complementary to visual appearance. Our method also outperforms prior work on prompt-based tuning of VLMs. We release the benchmark, consisting of 14 datasets at https://github.com/cvl-umass/AdaptCLIPZS , which will contribute to future research in zero-shot recognition.
4/5/2024
🔍
Refining Skewed Perceptions in Vision-Language Models through Visual Representations
Haocheng Dai, Sarang Joshi
0
0
Large vision-language models (VLMs), such as CLIP, have become foundational, demonstrating remarkable success across a variety of downstream tasks. Despite their advantages, these models, akin to other foundational systems, inherit biases from the disproportionate distribution of real-world data, leading to misconceptions about the actual environment. Prevalent datasets like ImageNet are often riddled with non-causal, spurious correlations that can diminish VLM performance in scenarios where these contextual elements are absent. This study presents an investigation into how a simple linear probe can effectively distill task-specific core features from CLIP's embedding for downstream applications. Our analysis reveals that the CLIP text representations are often tainted by spurious correlations, inherited in the biased pre-training dataset. Empirical evidence suggests that relying on visual representations from CLIP, as opposed to text embedding, is more practical to refine the skewed perceptions in VLMs, emphasizing the superior utility of visual representations in overcoming embedded biases. Our codes will be available here.
5/24/2024

Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
Zhenlin Xu, Yi Zhu, Tiffany Deng, Abhay Mittal, Yanbei Chen, Manchen Wang, Paolo Favaro, Joseph Tighe, Davide Modolo
0
0
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
6/19/2024

Efficient and Long-Tailed Generalization for Pre-trained Vision-Language Model
Jiang-Xin Shi, Chi Zhang, Tong Wei, Yu-Feng Li
0
0
Pre-trained vision-language models like CLIP have shown powerful zero-shot inference ability via image-text matching and prove to be strong few-shot learners in various downstream tasks. However, in real-world scenarios, adapting CLIP to downstream tasks may encounter the following challenges: 1) data may exhibit long-tailed data distributions and might not have abundant samples for all the classes; 2) There might be emerging tasks with new classes that contain no samples at all. To overcome them, we propose a novel framework to achieve efficient and long-tailed generalization, which can be termed as Candle. During the training process, we propose compensating logit-adjusted loss to encourage large margins of prototypes and alleviate imbalance both within the base classes and between the base and new classes. For efficient adaptation, we treat the CLIP model as a black box and leverage the extracted features to obtain visual and textual prototypes for prediction. To make full use of multi-modal information, we also propose cross-modal attention to enrich the features from both modalities. For effective generalization, we introduce virtual prototypes for new classes to make up for their lack of training images. Candle achieves state-of-the-art performance over extensive experiments on 11 diverse datasets while substantially reducing the training time, demonstrating the superiority of our approach. The source code is available at https://github.com/shijxcs/Candle.
6/19/2024