Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
2306.16048
0
0

Abstract
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
Create account to get full access
Overview
- This paper investigates the challenges of zero-shot recognition using vision-language models, focusing on two key aspects: granularity and correctness.
- Zero-shot recognition refers to the ability of a model to recognize and classify objects it has not been explicitly trained on, by leveraging the knowledge it has gained from other data.
- The paper examines how well vision-language models can perform zero-shot recognition at different levels of granularity, from coarse to fine-grained categories.
- It also explores the correctness, or accuracy, of the zero-shot recognition predictions made by these models.
Plain English Explanation
Vision-language models are a type of artificial intelligence that can understand and process both visual and textual information. These models have shown impressive capabilities in tasks like image recognition and captioning. However, one of the key challenges is how well they can perform zero-shot recognition, which means identifying objects or concepts that the model hasn't been explicitly trained on.
This paper looks at two important aspects of zero-shot recognition with vision-language models: granularity and correctness. Granularity refers to the level of detail in the categories or classes that the model can recognize, from broad, general categories to more fine-grained, specific ones. The paper investigates how the model's performance changes as the granularity of the recognition task becomes more detailed.
The paper also examines the correctness, or accuracy, of the zero-shot recognition predictions made by these models. Even if a model can identify an object it hasn't been trained on, the prediction may not always be entirely accurate. The researchers explore how reliable the model's zero-shot recognition capabilities are.
By understanding the challenges around granularity and correctness in zero-shot recognition, researchers and developers can work to improve the performance and reliability of vision-language models in real-world applications, such as improved zero-shot classification by adapting VLMs or evaluating vision-language models on real-world tasks.
Technical Explanation
The researchers conducted experiments to evaluate the zero-shot recognition capabilities of several state-of-the-art vision-language models, including CLIP and Detic. They tested the models on a range of datasets that varied in the granularity of their object categories, from coarse-grained to fine-grained.
The results showed that while the models performed well on coarse-grained zero-shot recognition, their performance dropped significantly as the task became more fine-grained. The researchers attribute this to the models' tendency to make overconfident predictions, even when the correct answer is not in the top predictions.
To address this issue, the paper proposes a novel calibration method that can improve the models' correctness and reliability in zero-shot recognition, especially for fine-grained tasks. The method involves adjusting the model's output probabilities to better reflect the uncertainty in its predictions.
The researchers also found that vision-language models exhibit certain biases in their zero-shot recognition, such as favoring common or "neglected tails" objects over rarer ones. This suggests that more work is needed to mitigate biases and improve the overall robustness of these models.
Critical Analysis
The paper provides valuable insights into the challenges of zero-shot recognition with vision-language models, which is an important capability for these models to possess. The focus on granularity and correctness is well-justified, as these aspects are critical for the practical application of these models in real-world scenarios.
One limitation of the study is that it only examines a few state-of-the-art vision-language models, and the findings may not generalize to all such models. Additionally, the proposed calibration method, while promising, needs further validation and testing to ensure its effectiveness across a wider range of datasets and model architectures.
The paper also does not delve deeply into the underlying reasons for the models' biases and overconfident predictions. A more thorough investigation into the model architectures, training data, and learning algorithms could provide valuable insights to guide future research and development efforts.
Overall, this paper contributes to the growing body of work on the capabilities and limitations of vision-language models, and highlights the importance of rigorously evaluating these models beyond just their headline-grabbing performance on benchmark tasks. Continued research in this area can help improve the effectiveness and robustness of these models for real-world applications.
Conclusion
This paper explores the challenges of zero-shot recognition with vision-language models, focusing on the aspects of granularity and correctness. The researchers conducted experiments to evaluate the performance of several state-of-the-art models on a range of datasets with varying levels of category granularity.
The results show that while the models perform well on coarse-grained zero-shot recognition, their performance drops significantly as the task becomes more fine-grained. The paper proposes a calibration method to improve the models' correctness and reliability, particularly for fine-grained zero-shot recognition.
The findings of this study highlight the need for continued research and development to address the limitations of vision-language models in real-world applications, such as overcoming biases and enhancing their zero-shot capabilities. By addressing these challenges, the field can move closer to realizing the full potential of vision-language models in a wide range of tasks and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024

Exploring the Spectrum of Visio-Linguistic Compositionality and Recognition
Youngtaek Oh, Pyunghwan Ahn, Jinhyung Kim, Gwangmo Song, Soonyoung Lee, In So Kweon, Junmo Kim
0
0
Vision and language models (VLMs) such as CLIP have showcased remarkable zero-shot recognition abilities yet face challenges in visio-linguistic compositionality, particularly in linguistic comprehension and fine-grained image-text alignment. This paper explores the intricate relationship between compositionality and recognition -- two pivotal aspects of VLM capability. We conduct a comprehensive evaluation of existing VLMs, covering both pre-training approaches aimed at recognition and the fine-tuning methods designed to improve compositionality. Our evaluation employs 12 benchmarks for compositionality, along with 21 zero-shot classification and two retrieval benchmarks for recognition. In our analysis from 274 CLIP model checkpoints, we reveal patterns and trade-offs that emerge between compositional understanding and recognition accuracy. Ultimately, this necessitates strategic efforts towards developing models that improve both capabilities, as well as the meticulous formulation of benchmarks for compositionality. We open our evaluation framework at https://github.com/ytaek-oh/vl_compo.
6/14/2024
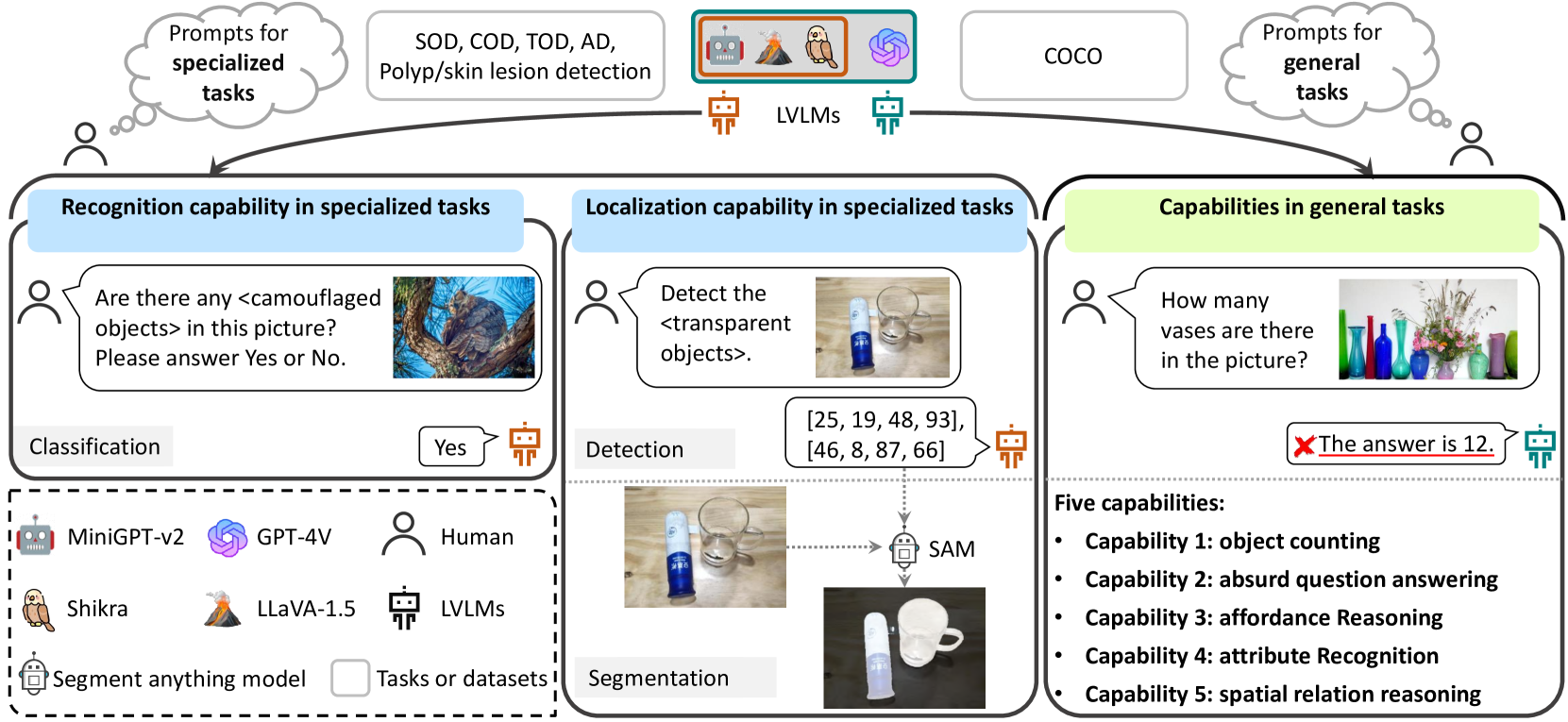
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
0
0
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
6/12/2024

Evaluating Large Vision-Language Models' Understanding of Real-World Complexities Through Synthetic Benchmarks
Haokun Zhou, Yipeng Hong
0
0
This study assesses the ability of Large Vision-Language Models (LVLMs) to differentiate between AI-generated and human-generated images. It introduces a new automated benchmark construction method for this evaluation. The experiment compared common LVLMs with human participants using a mixed dataset of AI and human-created images. Results showed that LVLMs could distinguish between the image types to some extent but exhibited a rightward bias, and perform significantly worse compared to humans. To build on these findings, we developed an automated benchmark construction process using AI. This process involved topic retrieval, narrative script generation, error embedding, and image generation, creating a diverse set of text-image pairs with intentional errors. We validated our method through constructing two caparable benchmarks. This study highlights the strengths and weaknesses of LVLMs in real-world understanding and advances benchmark construction techniques, providing a scalable and automatic approach for AI model evaluation.
6/14/2024