NeRF On-the-go: Exploiting Uncertainty for Distractor-free NeRFs in the Wild
2405.18715
0
0
Abstract
Neural Radiance Fields (NeRFs) have shown remarkable success in synthesizing photorealistic views from multi-view images of static scenes, but face challenges in dynamic, real-world environments with distractors like moving objects, shadows, and lighting changes. Existing methods manage controlled environments and low occlusion ratios but fall short in render quality, especially under high occlusion scenarios. In this paper, we introduce NeRF On-the-go, a simple yet effective approach that enables the robust synthesis of novel views in complex, in-the-wild scenes from only casually captured image sequences. Delving into uncertainty, our method not only efficiently eliminates distractors, even when they are predominant in captures, but also achieves a notably faster convergence speed. Through comprehensive experiments on various scenes, our method demonstrates a significant improvement over state-of-the-art techniques. This advancement opens new avenues for NeRF in diverse and dynamic real-world applications.
Create account to get full access
Overview
- This paper, "NeRF On-the-go: Exploiting Uncertainty for Distractor-free NeRFs in the Wild", presents a new approach to creating neural radiance fields (NeRFs) in dynamic and unconstrained environments.
- NeRFs are a type of 3D representation that can generate photorealistic images from a set of input images. However, traditional NeRF models can struggle with "distractors" - objects or people that are present in some but not all of the input images.
- The proposed method, called "NeRF On-the-go", aims to address this issue by explicitly modeling the uncertainty in the NeRF representation and using this to identify and exclude distractors during the rendering process.
Plain English Explanation
"NeRF On-the-go" is a new way to create 3D models of a scene using a technique called "neural radiance fields" (NeRFs). NeRFs can generate realistic-looking images from a set of input photos, but they can have trouble if there are things in the scene that aren't in all the photos, like people or objects.
The key idea behind "NeRF On-the-go" is to pay attention to how certain the NeRF model is about different parts of the scene. The model can then use this information to identify and ignore the parts of the scene that are inconsistent across the input photos, like distracting people or objects. This allows the NeRF to focus on the stable, consistent parts of the scene and produce better-quality 3D models, even in messy or dynamic environments.
Technical Explanation
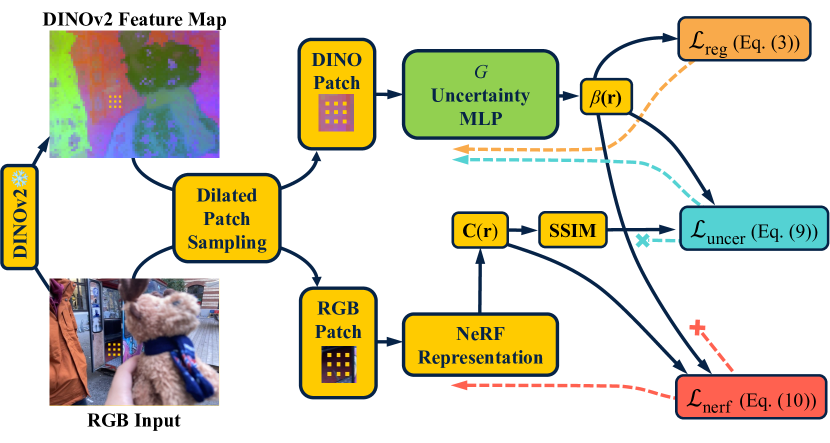
The authors propose a new NeRF-based approach called "NeRF On-the-go" that can handle dynamic and unconstrained environments with distractors. The core idea is to explicitly model the uncertainty in the NeRF representation and use this to identify and exclude distractors during the rendering process.
Specifically, the method uses a Bayesian NeRF model that estimates a distribution over the radiance field, rather than a single point estimate. This allows the model to quantify its uncertainty about different parts of the scene. The authors then introduce a rendering strategy that prioritizes regions with low uncertainty, effectively ignoring high-uncertainty "distractors" that are inconsistently present in the input images.
The paper presents extensive experiments comparing "NeRF On-the-go" to baseline NeRF models, as well as methods like AG-NeRF and CT-NeRF, on a variety of real-world datasets. The results show that the proposed approach can significantly improve the quality and robustness of the reconstructed 3D scenes, even in the presence of dynamic distractors.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the "NeRF On-the-go" approach, comparing it to several relevant baselines. The use of Bayesian uncertainty modeling to identify and exclude distractors is a clever and well-motivated idea.
However, one potential limitation is that the method relies on the assumption that distractors will exhibit higher uncertainty in the NeRF representation. While this seems to hold true in the experiments, there may be cases where distractors could be modeled with low uncertainty, for example if they are static or recurring elements in the scene.
Additionally, the paper does not explore the limitations of the Bayesian NeRF model itself, such as the increased computational cost or potential instabilities in the uncertainty estimation. Further research could investigate ways to improve the efficiency and robustness of the uncertainty-based rendering approach.
Finally, while the experiments demonstrate the effectiveness of "NeRF On-the-go" on real-world datasets, it would be interesting to see how the method performs on even more diverse and challenging scenes, such as those with significant occlusions, lighting changes, or camera motion.
Conclusion
This paper presents a novel approach called "NeRF On-the-go" that can create high-quality 3D models of complex scenes, even in the presence of dynamic distractors. By explicitly modeling the uncertainty in the NeRF representation and using this to prioritize stable, consistent elements of the scene, the method can produce more accurate and robust reconstructions compared to traditional NeRF models.
The key insights and technical advancements demonstrated in this work could have significant implications for a wide range of applications, from virtual and augmented reality to autonomous navigation and robotics. As the field of 3D scene understanding continues to advance, methods like "NeRF On-the-go" will play an increasingly important role in enabling these technologies to operate reliably in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CTNeRF: Cross-Time Transformer for Dynamic Neural Radiance Field from Monocular Video
Xingyu Miao, Yang Bai, Haoran Duan, Yawen Huang, Fan Wan, Yang Long, Yefeng Zheng
0
0
The goal of our work is to generate high-quality novel views from monocular videos of complex and dynamic scenes. Prior methods, such as DynamicNeRF, have shown impressive performance by leveraging time-varying dynamic radiation fields. However, these methods have limitations when it comes to accurately modeling the motion of complex objects, which can lead to inaccurate and blurry renderings of details. To address this limitation, we propose a novel approach that builds upon a recent generalization NeRF, which aggregates nearby views onto new viewpoints. However, such methods are typically only effective for static scenes. To overcome this challenge, we introduce a module that operates in both the time and frequency domains to aggregate the features of object motion. This allows us to learn the relationship between frames and generate higher-quality images. Our experiments demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets. Specifically, our approach outperforms existing methods in terms of both the accuracy and visual quality of the synthesized views. Our code is available on https://github.com/xingy038/CTNeRF.
6/27/2024

AG-NeRF: Attention-guided Neural Radiance Fields for Multi-height Large-scale Outdoor Scene Rendering
Jingfeng Guo, Xiaohan Zhang, Baozhu Zhao, Qi Liu
0
0
Existing neural radiance fields (NeRF)-based novel view synthesis methods for large-scale outdoor scenes are mainly built on a single altitude. Moreover, they often require a priori camera shooting height and scene scope, leading to inefficient and impractical applications when camera altitude changes. In this work, we propose an end-to-end framework, termed AG-NeRF, and seek to reduce the training cost of building good reconstructions by synthesizing free-viewpoint images based on varying altitudes of scenes. Specifically, to tackle the detail variation problem from low altitude (drone-level) to high altitude (satellite-level), a source image selection method and an attention-based feature fusion approach are developed to extract and fuse the most relevant features of target view from multi-height images for high-fidelity rendering. Extensive experiments demonstrate that AG-NeRF achieves SOTA performance on 56 Leonard and Transamerica benchmarks and only requires a half hour of training time to reach the competitive PSNR as compared to the latest BungeeNeRF.
4/19/2024

CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Yunlong Ran, Yanxu Li, Qi Ye, Yuchi Huo, Zechun Bai, Jiahao Sun, Jiming Chen
0
0
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
4/24/2024
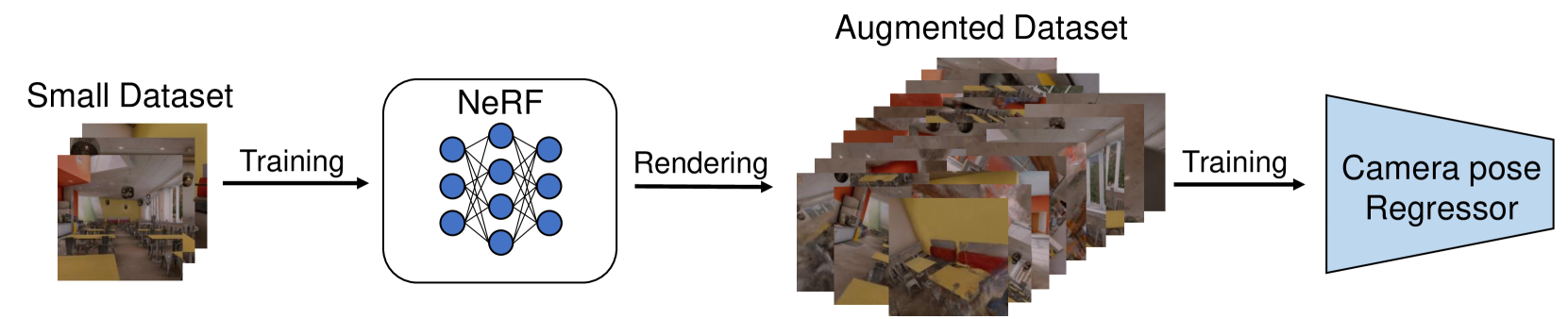
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Juyeop Han, Lukas Lao Beyer, Guilherme V. Cavalheiro, Sertac Karaman
0
0
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
4/3/2024