NeRF-Guided Unsupervised Learning of RGB-D Registration
2405.00507
0
0

Abstract
This paper focuses on training a robust RGB-D registration model without ground-truth pose supervision. Existing methods usually adopt a pairwise training strategy based on differentiable rendering, which enforces the photometric and the geometric consistency between the two registered frames as supervision. However, this frame-to-frame framework suffers from poor multi-view consistency due to factors such as lighting changes, geometry occlusion and reflective materials. In this paper, we present NeRF-UR, a novel frame-to-model optimization framework for unsupervised RGB-D registration. Instead of frame-to-frame consistency, we leverage the neural radiance field (NeRF) as a global model of the scene and use the consistency between the input and the NeRF-rerendered frames for pose optimization. This design can significantly improve the robustness in scenarios with poor multi-view consistency and provides better learning signal for the registration model. Furthermore, to bootstrap the NeRF optimization, we create a synthetic dataset, Sim-RGBD, through a photo-realistic simulator to warm up the registration model. By first training the registration model on Sim-RGBD and later unsupervisedly fine-tuning on real data, our framework enables distilling the capability of feature extraction and registration from simulation to reality. Our method outperforms the state-of-the-art counterparts on two popular indoor RGB-D datasets, ScanNet and 3DMatch. Code and models will be released for paper reproduction.
Create account to get full access
Overview
• This paper explores an unsupervised learning approach for RGB-D registration, guided by Neural Radiance Fields (NeRF) to improve performance. • It proposes a framework that leverages the geometry and appearance information captured by NeRF to learn an effective RGB-D registration model without direct supervision. • The key idea is to use the NeRF representation as a proxy for the ground truth, which can then be used to train the registration model in an unsupervised manner.
Plain English Explanation
• Registering RGB-D data, which combines color (RGB) and depth (D) information, is an important task in computer vision and robotics. It involves aligning multiple views of the same scene to create a cohesive 3D representation. • Traditionally, this task has required labeled training data, which can be time-consuming and expensive to obtain. The authors of this paper propose a new approach that can learn to register RGB-D data without needing any labeled examples. • The key to their method is the use of a Neural Radiance Field (NeRF), which is a machine learning model that can accurately represent the 3D geometry and appearance of a scene based on a series of 2D images. The NeRF model acts as a proxy for the ground truth, allowing the registration model to be trained in an unsupervised way. • By leveraging the information captured by the NeRF model, the authors' framework can learn to effectively register RGB-D data without the need for labeled training data, which is a significant advantage over traditional supervised approaches.
Technical Explanation
• The authors propose a framework called "NeRF-Guided Unsupervised Learning of RGB-D Registration" that uses a NeRF model as a proxy for ground truth to train an RGB-D registration model in an unsupervised manner. • The overall pipeline consists of three main components: a NeRF model, a registration model, and an unsupervised loss function. • The NeRF model is first trained on the input RGB-D data to capture the 3D geometry and appearance of the scene. This NeRF model is then used to generate synthetic depth and color images from different viewpoints. • The registration model, which is the main focus of the paper, is trained to align the input RGB-D frames to the synthetic views generated by the NeRF model. The unsupervised loss function compares the transformed input RGB-D data with the NeRF-generated views, providing the necessary signal to train the registration model. • The authors evaluate their approach on several benchmark datasets and demonstrate that their NeRF-guided unsupervised learning method outperforms traditional supervised approaches, particularly in scenarios with limited training data.
Critical Analysis
• The authors acknowledge that their approach relies on the accuracy of the NeRF model, which can be sensitive to factors such as the number of input views and the complexity of the scene. If the NeRF model fails to capture the true 3D geometry and appearance, it may negatively impact the performance of the registration model. • Additionally, the authors mention that the unsupervised loss function used to train the registration model may not be sufficient to capture all the nuances of the registration task, and further refinements or auxiliary losses may be necessary in some cases. • While the authors' results are promising, further research is needed to explore the generalization capabilities of their approach, particularly in more diverse and challenging real-world scenarios.
Conclusion
• This paper presents a novel approach for unsupervised learning of RGB-D registration, leveraging the power of Neural Radiance Fields (NeRF) to guide the training process. • By using the NeRF model as a proxy for ground truth, the authors' framework can learn an effective registration model without the need for labeled training data, which is a significant advantage over traditional supervised methods. • The results demonstrate the potential of this NeRF-guided unsupervised learning approach, and the authors' work opens up new avenues for further exploration in the field of 3D perception and scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Generative Lifting of Multiview to 3D from Unknown Pose: Wrapping NeRF inside Diffusion
Xin Yuan, Rana Hanocka, Michael Maire
0
0
We cast multiview reconstruction from unknown pose as a generative modeling problem. From a collection of unannotated 2D images of a scene, our approach simultaneously learns both a network to predict camera pose from 2D image input, as well as the parameters of a Neural Radiance Field (NeRF) for the 3D scene. To drive learning, we wrap both the pose prediction network and NeRF inside a Denoising Diffusion Probabilistic Model (DDPM) and train the system via the standard denoising objective. Our framework requires the system accomplish the task of denoising an input 2D image by predicting its pose and rendering the NeRF from that pose. Learning to denoise thus forces the system to concurrently learn the underlying 3D NeRF representation and a mapping from images to camera extrinsic parameters. To facilitate the latter, we design a custom network architecture to represent pose as a distribution, granting implicit capacity for discovering view correspondences when trained end-to-end for denoising alone. This technique allows our system to successfully build NeRFs, without pose knowledge, for challenging scenes where competing methods fail. At the conclusion of training, our learned NeRF can be extracted and used as a 3D scene model; our full system can be used to sample novel camera poses and generate novel-view images.
6/12/2024
🛠️
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
Baijun Ye, Caiyun Liu, Xiaoyu Ye, Yuantao Chen, Yuhai Wang, Zike Yan, Yongliang Shi, Hao Zhao, Guyue Zhou
0
0
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
5/7/2024
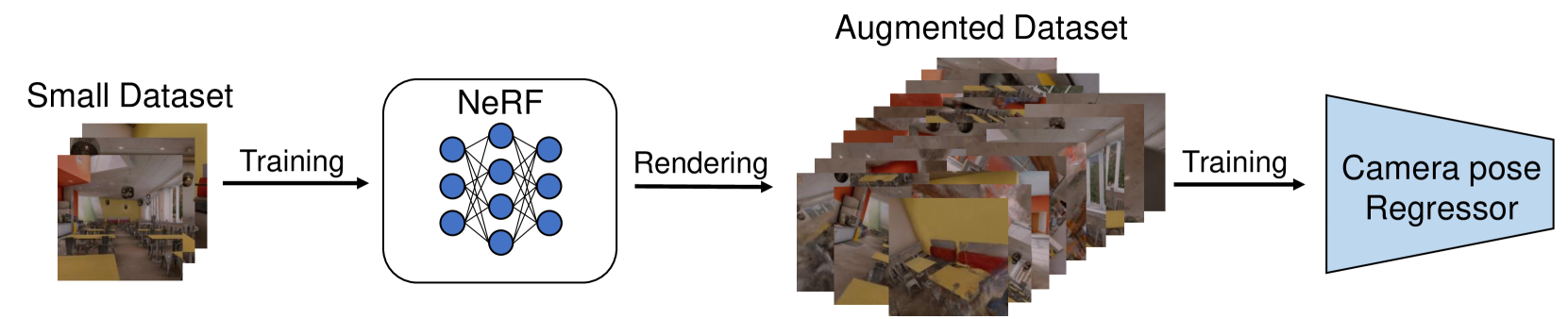
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Juyeop Han, Lukas Lao Beyer, Guilherme V. Cavalheiro, Sertac Karaman
0
0
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
4/3/2024

DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Letian Wang, Seung Wook Kim, Jiawei Yang, Cunjun Yu, Boris Ivanovic, Steven L. Waslander, Yue Wang, Sanja Fidler, Marco Pavone, Peter Karkus
0
0
We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
6/19/2024