NeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator

0
Sign in to get full access
Overview
- The paper introduces NeuraChip, a hardware accelerator designed to speed up computations for Graph Neural Networks (GNNs).
- NeuraChip uses a "hash-based decoupled spatial accelerator" architecture to efficiently perform sparse matrix multiplication, a key operation in GNN computations.
- The accelerator is designed to leverage on-chip memory and parallelism to improve performance and energy efficiency.
Plain English Explanation
NeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Graph Neural Networks (GNNs) are a powerful machine learning technique that can analyze complex, interconnected data structures like social networks or molecular compounds. However, the computations required for GNNs can be very resource-intensive, especially when dealing with large, sparse graphs.
To address this challenge, the researchers developed NeuraChip, a specialized hardware accelerator designed to speed up GNN computations. The key innovation in NeuraChip is its "hash-based decoupled spatial accelerator" architecture, which breaks down the complex sparse matrix multiplication operations used in GNNs into smaller, more manageable pieces.
By leveraging on-chip memory and parallel processing, NeuraChip can perform these computations much more efficiently than a general-purpose CPU or GPU. This results in significant improvements in both performance and energy efficiency when running GNN models.
The researchers tested NeuraChip on a variety of real-world GNN benchmarks and found that it outperformed other state-of-the-art hardware accelerators, demonstrating the potential of their hardware-software co-design approach.
Technical Explanation
The core innovation in NeuraChip is its hash-based decoupled spatial accelerator architecture, which is designed to efficiently perform the sparse matrix multiplications (SpGEMM) that are critical to GNN computations.
Traditionally, SpGEMM operations are challenging to accelerate due to their irregular memory access patterns and the need to handle variable-sized sparse matrices. NeuraChip addresses these challenges through a few key techniques:
-
Spatial Decoupling: NeuraChip separates the computations into two stages - a "hash-based lookup" stage that identifies the non-zero elements in the sparse matrices, and a "compute" stage that performs the actual multiplications. This decoupling allows for more efficient use of on-chip memory and parallelism.
-
Hashing-based Indexing: NeuraChip uses a hash-based indexing scheme to quickly locate the non-zero elements in the sparse matrices, avoiding the need for expensive scatter/gather operations.
-
Parallelism and On-chip Memory: The accelerator leverages many parallel processing units and large on-chip memory buffers to perform the computations efficiently, minimizing costly off-chip memory accesses.
The researchers evaluated NeuraChip's performance on a variety of standard GNN benchmarks and found that it outperformed other state-of-the-art GPU-based and FPGA-based accelerators, with significant improvements in both execution time and energy efficiency.
Critical Analysis
The researchers provide a thorough evaluation of NeuraChip's performance and compare it to other leading GNN accelerators. However, the paper does not address some potential limitations or areas for further research:
- Scalability: While NeuraChip shows impressive performance on the tested benchmarks, it's unclear how well it would scale to even larger and more complex GNN models, which may exceed the available on-chip memory and parallelism.
- Programmability: The paper focuses on the hardware design, but does not discuss the software stack or ease of programming for the accelerator. Developing efficient compiler and runtime support is crucial for widespread adoption.
- Generalizability: NeuraChip is designed specifically for GNN computations, but it would be interesting to see if the underlying principles could be applied to accelerate other types of sparse, irregular computations beyond just machine learning.
Overall, the NeuraChip design represents a promising step forward in enabling accelerators for graph computing, and the researchers have demonstrated the potential for significant performance and efficiency gains. Further exploration of the scalability, programmability, and generalizability of the approach could help unlock even greater advances in this important area of machine learning.
Conclusion
The NeuraChip paper introduces a novel hardware accelerator designed to speed up the computations required for Graph Neural Networks (GNNs). By leveraging a hash-based decoupled spatial architecture, NeuraChip is able to efficiently perform the sparse matrix multiplications that are central to GNN workloads, resulting in significant improvements in both performance and energy efficiency compared to other state-of-the-art accelerators.
This research represents an important step forward in enabling accelerators for graph computing, which could have wide-ranging implications for a variety of fields that rely on analyzing complex, interconnected data structures. Further advancements in areas like scalability, programmability, and generalizability could unlock even greater potential for this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NeuraChip: Accelerating GNN Computations with a Hash-based Decoupled Spatial Accelerator
Kaustubh Shivdikar, Nicolas Bohm Agostini, Malith Jayaweera, Gilbert Jonatan, Jose L. Abellan, Ajay Joshi, John Kim, David Kaeli
Graph Neural Networks (GNNs) are emerging as a formidable tool for processing non-euclidean data across various domains, ranging from social network analysis to bioinformatics. Despite their effectiveness, their adoption has not been pervasive because of scalability challenges associated with large-scale graph datasets, particularly when leveraging message passing. To tackle these challenges, we introduce NeuraChip, a novel GNN spatial accelerator based on Gustavson's algorithm. NeuraChip decouples the multiplication and addition computations in sparse matrix multiplication. This separation allows for independent exploitation of their unique data dependencies, facilitating efficient resource allocation. We introduce a rolling eviction strategy to mitigate data idling in on-chip memory as well as address the prevalent issue of memory bloat in sparse graph computations. Furthermore, the compute resource load balancing is achieved through a dynamic reseeding hash-based mapping, ensuring uniform utilization of computing resources agnostic of sparsity patterns. Finally, we present NeuraSim, an open-source, cycle-accurate, multi-threaded, modular simulator for comprehensive performance analysis. Overall, NeuraChip presents a significant improvement, yielding an average speedup of 22.1x over Intel's MKL, 17.1x over NVIDIA's cuSPARSE, 16.7x over AMD's hipSPARSE, and 1.5x over prior state-of-the-art SpGEMM accelerator and 1.3x over GNN accelerator. The source code for our open-sourced simulator and performance visualizer is publicly accessible on GitHub https://neurachip.us
Read more4/30/2024
0
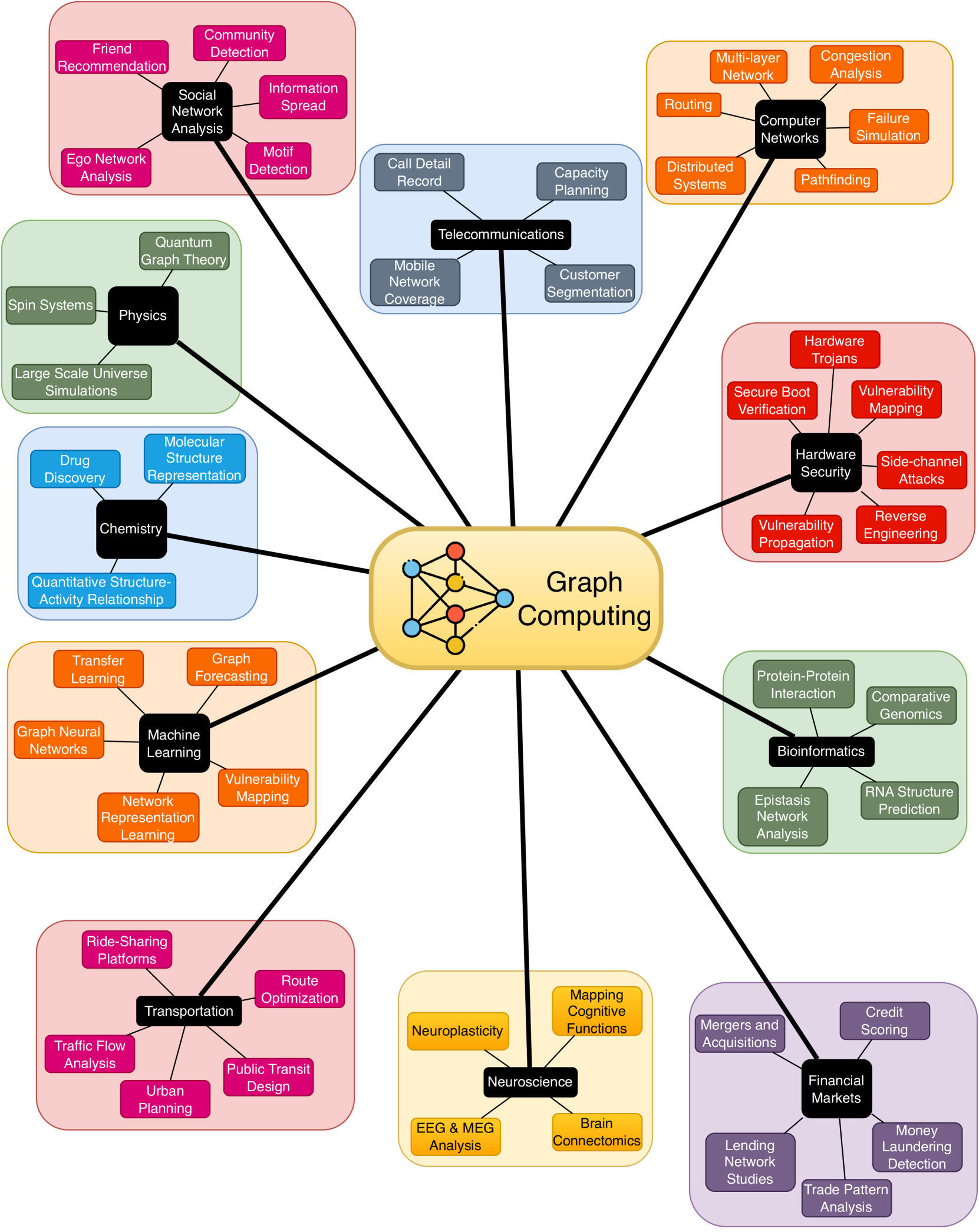
Enabling Accelerators for Graph Computing
Kaustubh Shivdikar
The advent of Graph Neural Networks (GNNs) has revolutionized the field of machine learning, offering a novel paradigm for learning on graph-structured data. Unlike traditional neural networks, GNNs are capable of capturing complex relationships and dependencies inherent in graph data, making them particularly suited for a wide range of applications including social network analysis, molecular chemistry, and network security. GNNs, with their unique structure and operation, present new computational challenges compared to conventional neural networks. This requires comprehensive benchmarking and a thorough characterization of GNNs to obtain insight into their computational requirements and to identify potential performance bottlenecks. In this thesis, we aim to develop a better understanding of how GNNs interact with the underlying hardware and will leverage this knowledge as we design specialized accelerators and develop new optimizations, leading to more efficient and faster GNN computations. A pivotal component within GNNs is the Sparse General Matrix-Matrix Multiplication (SpGEMM) kernel, known for its computational intensity and irregular memory access patterns. In this thesis, we address the challenges posed by SpGEMM by implementing a highly optimized hashing-based SpGEMM kernel tailored for a custom accelerator. Synthesizing these insights and optimizations, we design state-of-the-art hardware accelerators capable of efficiently handling various GNN workloads. Our accelerator architectures are built on our characterization of GNN computational demands, providing clear motivation for our approaches. This exploration into novel models underlines our comprehensive approach, as we strive to enable accelerators that are not just performant, but also versatile, able to adapt to the evolving landscape of graph computing.
Read more5/7/2024

0
SiHGNN: Leveraging Properties of Semantic Graphs for Efficient HGNN Acceleration
Runzhen Xue, Mingyu Yan, Dengke Han, Zhimin Tang, Xiaochun Ye, Dongrui Fan
Heterogeneous Graph Neural Networks (HGNNs) have expanded graph representation learning to heterogeneous graph fields. Recent studies have demonstrated their superior performance across various applications, including medical analysis and recommendation systems, often surpassing existing methods. However, GPUs often experience inefficiencies when executing HGNNs due to their unique and complex execution patterns. Compared to traditional Graph Neural Networks, these patterns further exacerbate irregularities in memory access. To tackle these challenges, recent studies have focused on developing domain-specific accelerators for HGNNs. Nonetheless, most of these efforts have concentrated on optimizing the datapath or scheduling data accesses, while largely overlooking the potential benefits that could be gained from leveraging the inherent properties of the semantic graph, such as its topology, layout, and generation. In this work, we focus on leveraging the properties of semantic graphs to enhance HGNN performance. First, we analyze the Semantic Graph Build (SGB) stage and identify significant opportunities for data reuse during semantic graph generation. Next, we uncover the phenomenon of buffer thrashing during the Graph Feature Processing (GFP) stage, revealing potential optimization opportunities in semantic graph layout. Furthermore, we propose a lightweight hardware accelerator frontend for HGNNs, called SiHGNN. This accelerator frontend incorporates a tree-based Semantic Graph Builder for efficient semantic graph generation and features a novel Graph Restructurer for optimizing semantic graph layouts. Experimental results show that SiHGNN enables the state-of-the-art HGNN accelerator to achieve an average performance improvement of 2.95$times$.
Read more8/28/2024
🐍
0
GPU-RANC: A CUDA Accelerated Simulation Framework for Neuromorphic Architectures
Sahil Hassan, Michael Inouye, Miguel C. Gonzalez, Ilkin Aliyev, Joshua Mack, Maisha Hafiz, Ali Akoglu
Open-source simulation tools play a crucial role for neuromorphic application engineers and hardware architects to investigate performance bottlenecks and explore design optimizations before committing to silicon. Reconfigurable Architecture for Neuromorphic Computing (RANC) is one such tool that offers ability to execute pre-trained Spiking Neural Network (SNN) models within a unified ecosystem through both software-based simulation and FPGA-based emulation. RANC has been utilized by the community with its flexible and highly parameterized design to study implementation bottlenecks, tune architectural parameters or modify neuron behavior based on application insights and study the trade space on hardware performance and network accuracy. In designing architectures for use in neuromorphic computing, there are an incredibly large number of configuration parameters such as number and precision of weights per neuron, neuron and axon counts per core, network topology, and neuron behavior. To accelerate such studies and provide users with a streamlined productive design space exploration, in this paper we introduce the GPU-based implementation of RANC. We summarize our parallelization approach and quantify the speedup gains achieved with GPU-based tick-accurate simulations across various use cases. We demonstrate up to 780 times speedup compared to serial version of the RANC simulator based on a 512 neuromorphic core MNIST inference application. We believe that the RANC ecosystem now provides a much more feasible avenue in the research of exploring different optimizations for accelerating SNNs and performing richer studies by enabling rapid convergence to optimized neuromorphic architectures.
Read more4/26/2024