Neural Dueling Bandits

0

Sign in to get full access
Overview
- Neural Dueling Bandits is a research paper that explores a new approach to the dueling bandits problem in machine learning.
- The dueling bandits problem involves ranking a set of options based on pairwise comparisons, where the goal is to identify the best option efficiently.
- The paper proposes using a neural network to model the preferences between options, which can capture more complex relationships compared to traditional linear models.
Plain English Explanation
The dueling bandits problem is like a competition between different options, where you can only compare two options at a time and see which one is better. The goal is to figure out which option is the overall best, by efficiently exploring the different options and learning their relative preferences.
In this paper, the researchers introduce a new approach that uses a neural network to model the preferences between the options. This allows the system to capture more complex relationships between the options, compared to traditional linear models.
The key idea is to train the neural network to predict the outcome of pairwise comparisons between the options. As the system gathers more data from these comparisons, it can learn the underlying preferences and identify the best option more efficiently. This neural dueling bandits approach is designed to work well in situations where the options have complex, non-linear relationships.
Technical Explanation
The paper formulates the dueling bandits problem as a reinforcement learning task, where the agent's goal is to identify the best option by repeatedly comparing pairs of options and observing the outcomes.
The researchers propose a neural dueling bandits algorithm that uses a neural network to model the underlying preference function between the options. The neural network takes in features of the options and outputs a predicted preference score for each option. The algorithm then selects pairs of options to compare based on these preference scores, and updates the neural network's parameters as it observes the comparison outcomes.
The key technical contributions of the paper include:
- A neural network architecture that can effectively capture complex, non-linear preference relationships between options.
- A novel exploration strategy that balances exploitation of the current preference model and exploration of uncertain options.
- Theoretical analysis showing that the neural dueling bandits algorithm can achieve near-optimal regret bounds, compared to the best possible algorithm for the dueling bandits problem.
The researchers evaluate their approach on both synthetic and real-world datasets, and demonstrate that the neural dueling bandits algorithm outperforms several baseline methods in terms of cumulative regret and ability to identify the best option.
Critical Analysis
The paper presents a promising approach to the dueling bandits problem, with the use of neural networks offering the potential to model more complex preference relationships. However, the authors acknowledge several limitations and areas for future research:
- The theoretical analysis assumes the neural network can be trained to convergence, which may not be practical in real-world settings with limited data and computational resources.
- The exploration strategy relies on estimating the uncertainty in the neural network's predictions, which can be challenging to do accurately in practice.
- The paper focuses on the single-objective setting, whereas many real-world problems involve multiple, potentially conflicting objectives that need to be balanced.
Additionally, one could question the scalability of the neural dueling bandits approach as the number of options grows large. Maintaining and updating a neural network for a large set of options may become computationally expensive, and the exploration-exploitation trade-off may become more challenging.
Overall, the paper presents an interesting and potentially impactful contribution to the dueling bandits literature, but further research is needed to address the identified limitations and explore extensions to more complex settings.
Conclusion
The Neural Dueling Bandits paper introduces a novel approach to the dueling bandits problem, leveraging the expressive power of neural networks to model complex preference relationships between options. By training a neural network to predict the outcomes of pairwise comparisons, the proposed algorithm can efficiently explore the option space and identify the best option.
The key innovation is the use of a neural network, which allows the algorithm to capture non-linear and context-dependent preferences that may be difficult to model with traditional linear approaches. The theoretical and empirical results presented in the paper suggest that this neural dueling bandits approach can outperform existing methods, particularly in settings with complex preference structures.
While the paper highlights some limitations and areas for future work, the overall contribution represents an important step forward in the field of dueling bandits and reinforcement learning more broadly. As the complexity of real-world decision-making problems continues to grow, techniques like neural dueling bandits may prove increasingly valuable in helping to navigate these challenging scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Dueling Bandits
Arun Verma, Zhongxiang Dai, Xiaoqiang Lin, Patrick Jaillet, Bryan Kian Hsiang Low
Contextual dueling bandit is used to model the bandit problems, where a learner's goal is to find the best arm for a given context using observed noisy preference feedback over the selected arms for the past contexts. However, existing algorithms assume the reward function is linear, which can be complex and non-linear in many real-life applications like online recommendations or ranking web search results. To overcome this challenge, we use a neural network to estimate the reward function using preference feedback for the previously selected arms. We propose upper confidence bound- and Thompson sampling-based algorithms with sub-linear regret guarantees that efficiently select arms in each round. We then extend our theoretical results to contextual bandit problems with binary feedback, which is in itself a non-trivial contribution. Experimental results on the problem instances derived from synthetic datasets corroborate our theoretical results.
Read more7/25/2024
🧠
0
Strategic Linear Contextual Bandits
Thomas Kleine Buening, Aadirupa Saha, Christos Dimitrakakis, Haifeng Xu
Motivated by the phenomenon of strategic agents gaming a recommender system to maximize the number of times they are recommended to users, we study a strategic variant of the linear contextual bandit problem, where the arms can strategically misreport their privately observed contexts to the learner. We treat the algorithm design problem as one of mechanism design under uncertainty and propose the Optimistic Grim Trigger Mechanism (OptGTM) that incentivizes the agents (i.e., arms) to report their contexts truthfully while simultaneously minimizing regret. We also show that failing to account for the strategic nature of the agents results in linear regret. However, a trade-off between mechanism design and regret minimization appears to be unavoidable. More broadly, this work aims to provide insight into the intersection of online learning and mechanism design.
Read more6/4/2024
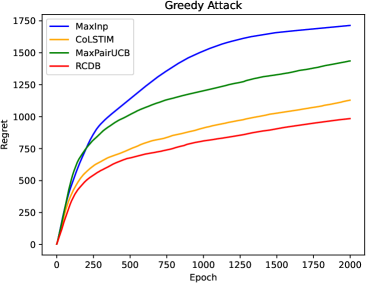
0
Nearly Optimal Algorithms for Contextual Dueling Bandits from Adversarial Feedback
Qiwei Di, Jiafan He, Quanquan Gu
Learning from human feedback plays an important role in aligning generative models, such as large language models (LLM). However, the effectiveness of this approach can be influenced by adversaries, who may intentionally provide misleading preferences to manipulate the output in an undesirable or harmful direction. To tackle this challenge, we study a specific model within this problem domain--contextual dueling bandits with adversarial feedback, where the true preference label can be flipped by an adversary. We propose an algorithm namely robust contextual dueling bandit (algo), which is based on uncertainty-weighted maximum likelihood estimation. Our algorithm achieves an $tilde O(dsqrt{T}+dC)$ regret bound, where $T$ is the number of rounds, $d$ is the dimension of the context, and $ 0 le C le T$ is the total number of adversarial feedback. We also prove a lower bound to show that our regret bound is nearly optimal, both in scenarios with and without ($C=0$) adversarial feedback. Additionally, we conduct experiments to evaluate our proposed algorithm against various types of adversarial feedback. Experimental results demonstrate its superiority over the state-of-the-art dueling bandit algorithms in the presence of adversarial feedback.
Read more4/17/2024
📊
0
Feel-Good Thompson Sampling for Contextual Dueling Bandits
Xuheng Li, Heyang Zhao, Quanquan Gu
Contextual dueling bandits, where a learner compares two options based on context and receives feedback indicating which was preferred, extends classic dueling bandits by incorporating contextual information for decision-making and preference learning. Several algorithms based on the upper confidence bound (UCB) have been proposed for linear contextual dueling bandits. However, no algorithm based on posterior sampling has been developed in this setting, despite the empirical success observed in traditional contextual bandits. In this paper, we propose a Thompson sampling algorithm, named FGTS.CDB, for linear contextual dueling bandits. At the core of our algorithm is a new Feel-Good exploration term specifically tailored for dueling bandits. This term leverages the independence of the two selected arms, thereby avoiding a cross term in the analysis. We show that our algorithm achieves nearly minimax-optimal regret, i.e., $tilde{mathcal{O}}(dsqrt T)$, where $d$ is the model dimension and $T$ is the time horizon. Finally, we evaluate our algorithm on synthetic data and observe that FGTS.CDB outperforms existing algorithms by a large margin.
Read more4/10/2024