Neural Isometries: Taming Transformations for Equivariant ML

0

Sign in to get full access
Overview
- This paper introduces "neural isometries" - a new approach to handling transformations in equivariant machine learning models.
- Equivariant models are able to learn representations that are invariant to certain transformations, like rotation or scaling, which can improve their performance and sample efficiency.
- The authors propose a new way to incorporate transformations into neural networks that is more flexible and generalizable than previous methods.
Plain English Explanation
The paper discusses a new technique called "neural isometries" that can help machine learning models better handle transformations like rotation, scaling, and other changes to the input data.
Machine learning models that are "equivariant" are able to learn representations that are invariant to certain transformations. This can make the models more robust and sample-efficient.
Previous methods for building equivariant models have been limited in their flexibility and generalizability. The neural isometries approach introduced in this paper provides a more flexible and generalizable way to incorporate transformations into neural network architectures.
Rather than hardcoding specific transformations into the model, the neural isometries approach learns a set of "latent space symmetries" that capture the relevant transformations in the data. This allows the model to be more adaptable to different types of transformations, including high-dimensional or complex ones.
The authors demonstrate how neural isometries can be applied to a variety of equivariant machine learning tasks, outperforming previous state-of-the-art methods.
Technical Explanation
The key innovation in this paper is the concept of "neural isometries" - a new way to incorporate transformations into equivariant machine learning models.
Previous approaches to building equivariant models have relied on either hand-engineering specific transformations into the model architecture, or learning a set of transformations in an unsupervised way. The neural isometries method provides a more flexible and generalizable alternative.
Rather than hardcoding transformations, the neural isometries approach learns a set of "latent space symmetries" that capture the relevant transformations in the data. These learned symmetries are then used to constrain the neural network layers, ensuring that the model's representations are equivariant to the identified transformations.
This approach has several advantages over prior methods. First, it is more flexible and can handle a wider range of transformations, including high-dimensional or complex ones that may be difficult to specify manually. Second, the learned symmetries can adapt to the specific data and task, rather than relying on a pre-defined set of transformations.
The authors demonstrate the effectiveness of neural isometries on a variety of equivariant machine learning tasks, including image classification, point cloud processing, and graph neural networks. They show that neural isometries can outperform previous state-of-the-art equivariant models, particularly in settings with limited data.
Critical Analysis
One potential limitation of the neural isometries approach is that it relies on the model being able to accurately identify the relevant transformations in the data. If the learned symmetries do not capture all the important transformations, the model may still struggle to achieve equivariance.
Additionally, the process of learning the latent space symmetries adds some computational overhead to the training process, which could be a concern for large-scale or real-time applications.
The paper also does not address the interpretability of the learned symmetries, which could be an important consideration in some applications where model transparency is a priority.
Overall, the neural isometries approach represents an interesting and promising advancement in the field of equivariant machine learning. However, further research may be needed to address some of the potential limitations and to explore the broader implications of this technique.
Conclusion
This paper introduces a novel approach called "neural isometries" for incorporating transformations into equivariant machine learning models. By learning a set of latent space symmetries that capture the relevant transformations in the data, the neural isometries method provides a more flexible and generalizable way to build equivariant models compared to previous techniques.
The authors demonstrate the effectiveness of neural isometries across a range of equivariant machine learning tasks, showing that it can outperform state-of-the-art methods, particularly in data-limited settings. While the approach has some potential limitations, it represents an important step forward in the field of equivariant machine learning and could have significant implications for building more robust and sample-efficient AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Isometries: Taming Transformations for Equivariant ML
Thomas W. Mitchel, Michael Taylor, Vincent Sitzmann
Real-world geometry and 3D vision tasks are replete with challenging symmetries that defy tractable analytical expression. In this paper, we introduce Neural Isometries, an autoencoder framework which learns to map the observation space to a general-purpose latent space wherein encodings are related by isometries whenever their corresponding observations are geometrically related in world space. Specifically, we regularize the latent space such that maps between encodings preserve a learned inner product and commute with a learned functional operator, in the same manner as rigid-body transformations commute with the Laplacian. This approach forms an effective backbone for self-supervised representation learning, and we demonstrate that a simple off-the-shelf equivariant network operating in the pre-trained latent space can achieve results on par with meticulously-engineered, handcrafted networks designed to handle complex, nonlinear symmetries. Furthermore, isometric maps capture information about the respective transformations in world space, and we show that this allows us to regress camera poses directly from the coefficients of the maps between encodings of adjacent views of a scene.
Read more5/30/2024

0
Thinner Latent Spaces: Detecting dimension and imposing invariance through autoencoder gradient constraints
George A. Kevrekidis, Mauro Maggioni, Soledad Villar, Yannis G. Kevrekidis
Conformal Autoencoders are a neural network architecture that imposes orthogonality conditions between the gradients of latent variables towards achieving disentangled representations of data. In this letter we show that orthogonality relations within the latent layer of the network can be leveraged to infer the intrinsic dimensionality of nonlinear manifold data sets (locally characterized by the dimension of their tangent space), while simultaneously computing encoding and decoding (embedding) maps. We outline the relevant theory relying on differential geometry, and describe the corresponding gradient-descent optimization algorithm. The method is applied to standard data sets and we highlight its applicability, advantages, and shortcomings. In addition, we demonstrate that the same computational technology can be used to build coordinate invariance to local group actions when defined only on a (reduced) submanifold of the embedding space.
Read more8/30/2024
🤷
0
Unsupervised Learning of Group Invariant and Equivariant Representations
Robin Winter, Marco Bertolini, Tuan Le, Frank No'e, Djork-Arn'e Clevert
Equivariant neural networks, whose hidden features transform according to representations of a group G acting on the data, exhibit training efficiency and an improved generalisation performance. In this work, we extend group invariant and equivariant representation learning to the field of unsupervised deep learning. We propose a general learning strategy based on an encoder-decoder framework in which the latent representation is separated in an invariant term and an equivariant group action component. The key idea is that the network learns to encode and decode data to and from a group-invariant representation by additionally learning to predict the appropriate group action to align input and output pose to solve the reconstruction task. We derive the necessary conditions on the equivariant encoder, and we present a construction valid for any G, both discrete and continuous. We describe explicitly our construction for rotations, translations and permutations. We test the validity and the robustness of our approach in a variety of experiments with diverse data types employing different network architectures.
Read more4/15/2024
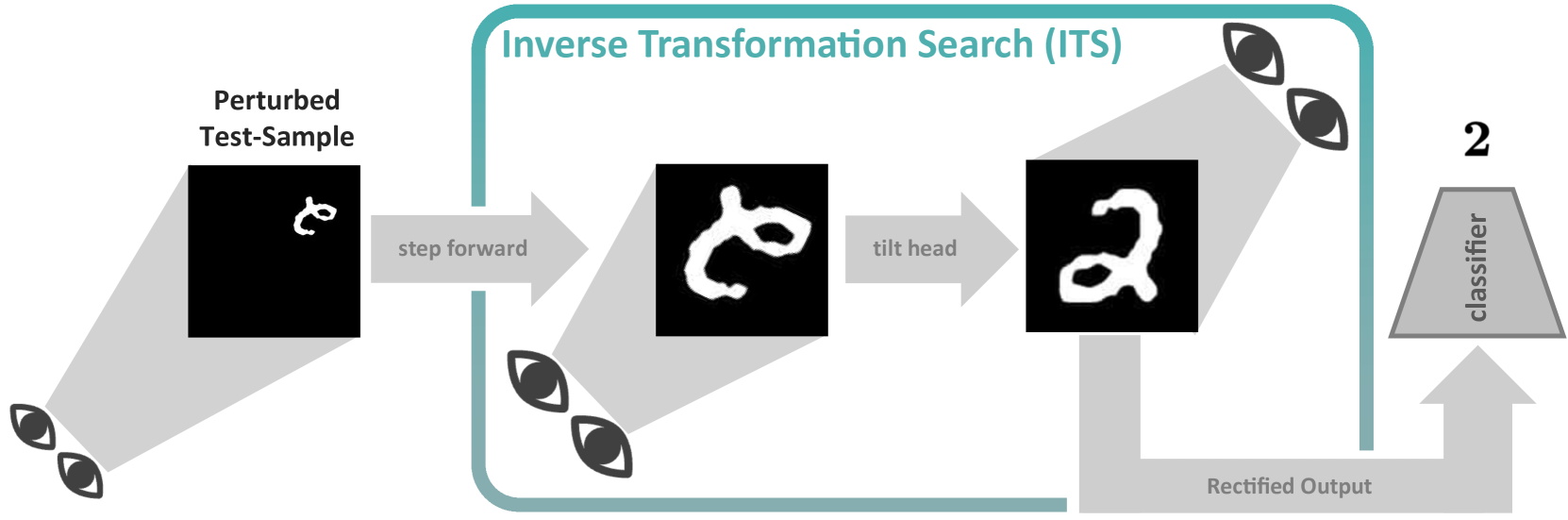
0
Tilt your Head: Activating the Hidden Spatial-Invariance of Classifiers
Johann Schmidt, Sebastian Stober
Deep neural networks are applied in more and more areas of everyday life. However, they still lack essential abilities, such as robustly dealing with spatially transformed input signals. Approaches to mitigate this severe robustness issue are limited to two pathways: Either models are implicitly regularised by increased sample variability (data augmentation) or explicitly constrained by hard-coded inductive biases. The limiting factor of the former is the size of the data space, which renders sufficient sample coverage intractable. The latter is limited by the engineering effort required to develop such inductive biases for every possible scenario. Instead, we take inspiration from human behaviour, where percepts are modified by mental or physical actions during inference. We propose a novel technique to emulate such an inference process for neural nets. This is achieved by traversing a sparsified inverse transformation tree during inference using parallel energy-based evaluations. Our proposed inference algorithm, called Inverse Transformation Search (ITS), is model-agnostic and equips the model with zero-shot pseudo-invariance to spatially transformed inputs. We evaluated our method on several benchmark datasets, including a synthesised ImageNet test set. ITS outperforms the utilised baselines on all zero-shot test scenarios.
Read more5/28/2024