Thinner Latent Spaces: Detecting dimension and imposing invariance through autoencoder gradient constraints

0

Sign in to get full access
Overview
- Presents a method to detect the intrinsic dimension of the latent space in autoencoders and impose desired geometric properties through gradient constraints.
- Aims to produce a more compact, low-dimensional latent representation while retaining important information.
- Key ideas include: detecting latent dimension, enforcing invariances, and using gradient constraints to shape the latent space.
Plain English Explanation
Autoencoders are a type of neural network that can learn to compress and decompress data, creating a reduced, lower-dimensional representation called the "latent space." This latent space is meant to capture the most important information from the original data.
However, the latent space can sometimes be larger than necessary, containing redundant or irrelevant dimensions. The authors of this paper present a method to detect the true, intrinsic dimension of the latent space - in other words, the minimum number of dimensions needed to represent the data effectively.
Additionally, the authors show how to impose desired geometric properties on the latent space. For example, they can make the latent space invariant to certain transformations of the input data, so that the autoencoder's output doesn't change when the input is rotated, translated, or scaled.
The key innovation is the use of gradient constraints during training to shape the latent space. By controlling the gradients of the autoencoder, the authors can encourage the network to learn a more compact, low-dimensional latent representation that still preserves important information from the original data.
Overall, this research aims to create more efficient and robust autoencoder models by carefully controlling the properties of the latent space. This could have applications in areas like data compression, where a smaller latent representation is desirable, or in machine learning tasks that require invariance to certain transformations.
Technical Explanation
The key contributions of this paper are:
-
Latent Dimension Detection: The authors propose a method to automatically detect the intrinsic dimension of the latent space in an autoencoder. This involves analyzing the singular values of the encoder's Jacobian matrix to determine the minimum number of latent dimensions needed to represent the data.
-
Invariance Constraints: The authors introduce gradient-based constraints that can be used to impose desired geometric properties, such as invariance to specific transformations, on the latent space. This is achieved by penalizing the gradients of the autoencoder with respect to the transformed inputs.
-
Latent Space Shaping: By combining the dimension detection and invariance constraints, the authors demonstrate how to shape the latent space of the autoencoder to be more compact and low-dimensional, while retaining important information from the original data.
Experiments are conducted on various datasets, including images and tabular data, to evaluate the effectiveness of the proposed methods. The results show that the authors' approach can produce autoencoders with smaller latent spaces that are more robust to input transformations, without significant loss of reconstruction quality.
Critical Analysis
The paper presents a compelling approach to improving the efficiency and controllability of autoencoder models. The ability to detect the intrinsic dimension of the latent space and impose desired geometric properties is a valuable contribution.
However, the authors acknowledge that their method relies on the assumption that the latent space can be well-approximated by a low-dimensional manifold. In cases where the data has a more complex structure, the proposed techniques may not be as effective.
Additionally, the authors do not provide a detailed analysis of the computational overhead or training time required by their approach compared to standard autoencoder training. This information would be helpful for evaluating the practicality of the method, especially for large-scale or real-time applications.
Further research could explore the generalization of the proposed techniques to other types of neural networks beyond autoencoders, as well as the integration with other latent space regularization methods to achieve even more compact and robust representations.
Conclusion
This paper presents a novel approach to improving the efficiency and controllability of autoencoder models by detecting the intrinsic dimension of the latent space and imposing desired geometric properties through gradient constraints. The key ideas, including latent dimension detection, invariance constraints, and latent space shaping, offer a promising direction for enhancing the performance and versatility of autoencoder-based models in various applications, such as data compression, transformation-invariant machine learning, and more.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Thinner Latent Spaces: Detecting dimension and imposing invariance through autoencoder gradient constraints
George A. Kevrekidis, Mauro Maggioni, Soledad Villar, Yannis G. Kevrekidis
Conformal Autoencoders are a neural network architecture that imposes orthogonality conditions between the gradients of latent variables towards achieving disentangled representations of data. In this letter we show that orthogonality relations within the latent layer of the network can be leveraged to infer the intrinsic dimensionality of nonlinear manifold data sets (locally characterized by the dimension of their tangent space), while simultaneously computing encoding and decoding (embedding) maps. We outline the relevant theory relying on differential geometry, and describe the corresponding gradient-descent optimization algorithm. The method is applied to standard data sets and we highlight its applicability, advantages, and shortcomings. In addition, we demonstrate that the same computational technology can be used to build coordinate invariance to local group actions when defined only on a (reduced) submanifold of the embedding space.
Read more8/30/2024

0
Neural Isometries: Taming Transformations for Equivariant ML
Thomas W. Mitchel, Michael Taylor, Vincent Sitzmann
Real-world geometry and 3D vision tasks are replete with challenging symmetries that defy tractable analytical expression. In this paper, we introduce Neural Isometries, an autoencoder framework which learns to map the observation space to a general-purpose latent space wherein encodings are related by isometries whenever their corresponding observations are geometrically related in world space. Specifically, we regularize the latent space such that maps between encodings preserve a learned inner product and commute with a learned functional operator, in the same manner as rigid-body transformations commute with the Laplacian. This approach forms an effective backbone for self-supervised representation learning, and we demonstrate that a simple off-the-shelf equivariant network operating in the pre-trained latent space can achieve results on par with meticulously-engineered, handcrafted networks designed to handle complex, nonlinear symmetries. Furthermore, isometric maps capture information about the respective transformations in world space, and we show that this allows us to regress camera poses directly from the coefficients of the maps between encodings of adjacent views of a scene.
Read more5/30/2024
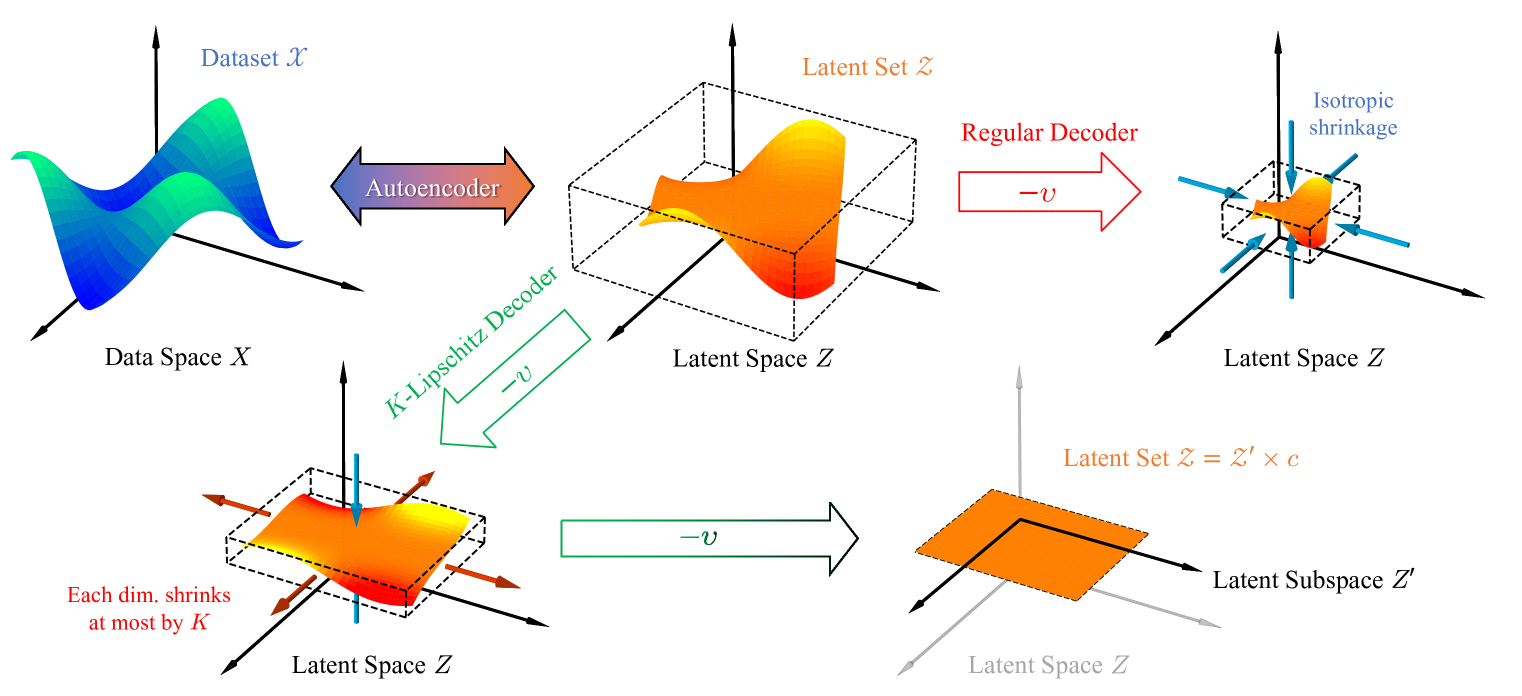
0
Compressing Latent Space via Least Volume
Qiuyi Chen, Mark Fuge
This paper introduces Least Volume-a simple yet effective regularization inspired by geometric intuition-that can reduce the necessary number of latent dimensions needed by an autoencoder without requiring any prior knowledge of the intrinsic dimensionality of the dataset. We show that the Lipschitz continuity of the decoder is the key to making it work, provide a proof that PCA is just a linear special case of it, and reveal that it has a similar PCA-like importance ordering effect when applied to nonlinear models. We demonstrate the intuition behind the regularization on some pedagogical toy problems, and its effectiveness on several benchmark problems, including MNIST, CIFAR-10 and CelebA.
Read more4/30/2024

0
Decoder ensembling for learned latent geometries
Stas Syrota, Pablo Moreno-Mu~noz, S{o}ren Hauberg
Latent space geometry provides a rigorous and empirically valuable framework for interacting with the latent variables of deep generative models. This approach reinterprets Euclidean latent spaces as Riemannian through a pull-back metric, allowing for a standard differential geometric analysis of the latent space. Unfortunately, data manifolds are generally compact and easily disconnected or filled with holes, suggesting a topological mismatch to the Euclidean latent space. The most established solution to this mismatch is to let uncertainty be a proxy for topology, but in neural network models, this is often realized through crude heuristics that lack principle and generally do not scale to high-dimensional representations. We propose using ensembles of decoders to capture model uncertainty and show how to easily compute geodesics on the associated expected manifold. Empirically, we find this simple and reliable, thereby coming one step closer to easy-to-use latent geometries.
Read more8/15/2024