Neural network learns low-dimensional polynomials with SGD near the information-theoretic limit

0
Sign in to get full access
Overview
- This paper explores how neural networks can learn low-dimensional polynomial functions from high-dimensional data using stochastic gradient descent (SGD).
- The researchers investigate the theoretical limits of this learning process and show that neural networks can achieve near-optimal performance under certain conditions.
- The findings have implications for understanding the capabilities and limitations of neural networks in learning complex functions from sparse data.
Plain English Explanation
Neural networks are a type of machine learning model inspired by the human brain. They are made up of interconnected nodes that can "learn" patterns in data through a process called training. In this paper, the researchers looked at how neural networks can learn simple polynomial functions from high-dimensional data, using a training technique called stochastic gradient descent (SGD).
Polynomials are mathematical functions that can be represented as a sum of terms with variables raised to different powers. The researchers focused on low-dimensional polynomials, meaning the functions only depend on a small number of the input variables, even though the overall data has many dimensions.
The key insight is that neural networks can learn these low-dimensional polynomials very efficiently, even getting close to the theoretical "information-theoretic" limit of what's possible. This means the neural networks are able to extract the most important information from the high-dimensional data to learn the simple underlying function.
The findings have important implications for understanding the capabilities and limitations of neural networks in practical applications. They suggest that neural networks can be remarkably effective at approximating complex functions from sparse, high-dimensional data, as long as the underlying function has a low-dimensional structure.
Technical Explanation
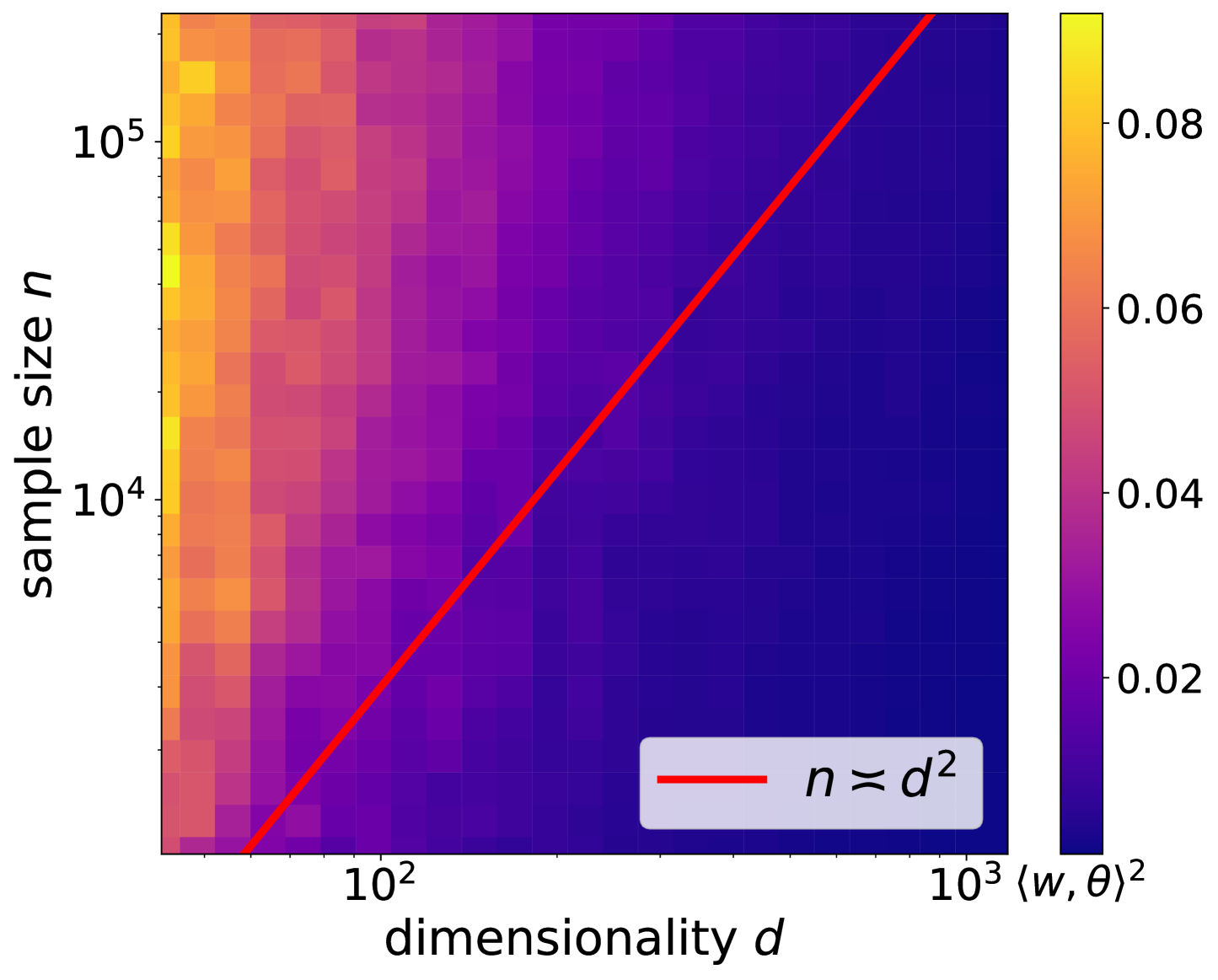
The paper investigates the ability of neural networks trained with stochastic gradient descent (SGD) to learn low-dimensional polynomial functions from high-dimensional data. The researchers derive theoretical bounds on the sample complexity and generalization error of this learning process, and show that neural networks can achieve near-optimal performance under certain conditions.
Specifically, the authors consider a setting where the target function is a low-degree polynomial in a small subset of the input variables, even though the overall input dimension is much higher. They analyze the effectiveness of SGD in learning such functions, and provide upper and lower bounds on the required number of training samples to achieve a given level of generalization error.
The key technical results show that neural networks trained with SGD can learn these low-dimensional polynomials near the information-theoretic limit, meaning they can extract the essential information from the high-dimensional inputs to accurately approximate the target function. This contrasts with more general nonparametric regression tasks, where the sample complexity can scale poorly with the input dimension.
The findings build on prior work on the memory capacity of shallow neural networks and the ability of SGD to efficiently learn low-complexity functions from data. By characterizing the sample complexity for this specific class of low-dimensional polynomials, the paper provides insights into the strengths and limitations of neural networks in high-dimensional function approximation tasks.
Critical Analysis
The paper presents a strong theoretical analysis of neural network learning for low-dimensional polynomial functions, with tight upper and lower bounds on the sample complexity. This provides a rigorous understanding of the conditions under which neural networks can achieve near-optimal performance in this setting.
However, the analysis is limited to a specific class of target functions - low-degree polynomials in a small subset of the input variables. While this is an important and relevant case, it does not cover the full range of functions that neural networks may need to learn in practice. The authors acknowledge this limitation and suggest extending the analysis to more general function classes as an area for future research.
Additionally, the theoretical results rely on assumptions such as the target function having low underlying complexity, the network architecture matching the function structure, and the training process satisfying certain technical conditions. While these assumptions are reasonable for the given setting, they may not always hold in real-world applications, where the target functions and data distributions can be much more complex and heterogeneous.
Further empirical validation of the theoretical insights on a broader range of practical problems would help to better understand the strengths and limitations of the findings. Exploring how the results generalize to more complex neural network architectures and training regimes would also be a valuable direction for future work.
Conclusion
This paper provides a rigorous theoretical analysis of the ability of neural networks trained with stochastic gradient descent to learn low-dimensional polynomial functions from high-dimensional data. The key finding is that neural networks can achieve near-optimal performance in this setting, approaching the information-theoretic limits of what's possible.
These results offer important insights into the capabilities and limitations of neural networks in high-dimensional function approximation tasks. They suggest that neural networks can be remarkably effective at learning simple, low-dimensional structures from complex, sparse data, as long as the underlying function has the right kind of structure.
The findings have implications for the design and application of neural networks in a variety of domains, from scientific modeling to pattern recognition. By understanding the theoretical limits of neural network learning, researchers and practitioners can better assess the appropriate use cases and develop more effective neural network architectures and training techniques.
Overall, this paper contributes to the ongoing effort to understand the fundamental principles underlying the success of neural networks and to push the boundaries of what's possible with this powerful machine learning approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural network learns low-dimensional polynomials with SGD near the information-theoretic limit
Jason D. Lee, Kazusato Oko, Taiji Suzuki, Denny Wu
We study the problem of gradient descent learning of a single-index target function $f_*(boldsymbol{x}) = textstylesigma_*left(langleboldsymbol{x},boldsymbol{theta}rangleright)$ under isotropic Gaussian data in $mathbb{R}^d$, where the link function $sigma_*:mathbb{R}tomathbb{R}$ is an unknown degree $q$ polynomial with information exponent $p$ (defined as the lowest degree in the Hermite expansion). Prior works showed that gradient-based training of neural networks can learn this target with $ngtrsim d^{Theta(p)}$ samples, and such statistical complexity is predicted to be necessary by the correlational statistical query lower bound. Surprisingly, we prove that a two-layer neural network optimized by an SGD-based algorithm learns $f_*$ of arbitrary polynomial link function with a sample and runtime complexity of $n asymp T asymp C(q) cdot dmathrm{polylog} d$, where constant $C(q)$ only depends on the degree of $sigma_*$, regardless of information exponent; this dimension dependence matches the information theoretic limit up to polylogarithmic factors. Core to our analysis is the reuse of minibatch in the gradient computation, which gives rise to higher-order information beyond correlational queries.
Read more6/4/2024
0
Learning smooth functions in high dimensions: from sparse polynomials to deep neural networks
Ben Adcock, Simone Brugiapaglia, Nick Dexter, Sebastian Moraga
Learning approximations to smooth target functions of many variables from finite sets of pointwise samples is an important task in scientific computing and its many applications in computational science and engineering. Despite well over half a century of research on high-dimensional approximation, this remains a challenging problem. Yet, significant advances have been made in the last decade towards efficient methods for doing this, commencing with so-called sparse polynomial approximation methods and continuing most recently with methods based on Deep Neural Networks (DNNs). In tandem, there have been substantial advances in the relevant approximation theory and analysis of these techniques. In this work, we survey this recent progress. We describe the contemporary motivations for this problem, which stem from parametric models and computational uncertainty quantification; the relevant function classes, namely, classes of infinite-dimensional, Banach-valued, holomorphic functions; fundamental limits of learnability from finite data for these classes; and finally, sparse polynomial and DNN methods for efficiently learning such functions from finite data. For the latter, there is currently a significant gap between the approximation theory of DNNs and the practical performance of deep learning. Aiming to narrow this gap, we develop the topic of practical existence theory, which asserts the existence of dimension-independent DNN architectures and training strategies that achieve provably near-optimal generalization errors in terms of the amount of training data.
Read more4/8/2024
🏋️
0
Learning sum of diverse features: computational hardness and efficient gradient-based training for ridge combinations
Kazusato Oko, Yujin Song, Taiji Suzuki, Denny Wu
We study the computational and sample complexity of learning a target function $f_*:mathbb{R}^dtomathbb{R}$ with additive structure, that is, $f_*(x) = frac{1}{sqrt{M}}sum_{m=1}^M f_m(langle x, v_mrangle)$, where $f_1,f_2,...,f_M:mathbb{R}tomathbb{R}$ are nonlinear link functions of single-index models (ridge functions) with diverse and near-orthogonal index features ${v_m}_{m=1}^M$, and the number of additive tasks $M$ grows with the dimensionality $Masymp d^gamma$ for $gammage 0$. This problem setting is motivated by the classical additive model literature, the recent representation learning theory of two-layer neural network, and large-scale pretraining where the model simultaneously acquires a large number of skills that are often localized in distinct parts of the trained network. We prove that a large subset of polynomial $f_*$ can be efficiently learned by gradient descent training of a two-layer neural network, with a polynomial statistical and computational complexity that depends on the number of tasks $M$ and the information exponent of $f_m$, despite the unknown link function and $M$ growing with the dimensionality. We complement this learnability guarantee with computational hardness result by establishing statistical query (SQ) lower bounds for both the correlational SQ and full SQ algorithms.
Read more6/18/2024
🏋️
0
Approximation and Gradient Descent Training with Neural Networks
G. Welper
It is well understood that neural networks with carefully hand-picked weights provide powerful function approximation and that they can be successfully trained in over-parametrized regimes. Since over-parametrization ensures zero training error, these two theories are not immediately compatible. Recent work uses the smoothness that is required for approximation results to extend a neural tangent kernel (NTK) optimization argument to an under-parametrized regime and show direct approximation bounds for networks trained by gradient flow. Since gradient flow is only an idealization of a practical method, this paper establishes analogous results for networks trained by gradient descent.
Read more5/21/2024