Neural Networks with (Low-Precision) Polynomial Approximations: New Insights and Techniques for Accuracy Improvement

0

Sign in to get full access
Overview
- This paper proposes a novel neural network architecture called Polynomial Augmented Neural Networks (PANNs) that leverages polynomial functions to improve the performance of neural networks on weak orthogonality tasks.
- The authors also introduce an Optimized Layerwise Approximation (OLA) method for efficient private inference with fully connected neural networks.
- Additionally, the paper explores learning smooth functions in high dimensions from sparse data using a physics-informed neural network (PINN) approach, and unveils the optimization process of PINNs.
Plain English Explanation
The researchers have developed a new type of neural network called Polynomial Augmented Neural Networks (PANNs) that combines neural networks with polynomial functions. This can help improve the performance of neural networks on certain tasks, particularly those involving "weak orthogonality."
The researchers also created a method called Optimized Layerwise Approximation (OLA) that allows for efficient and private inference (making predictions) using fully connected neural networks. This could be useful for applications that require protecting sensitive data.
Additionally, the paper explores how to learn smooth functions in high dimensions from sparse data using an approach called physics-informed neural networks (PINNs). The researchers also provide insights into the optimization process of PINNs.
Overall, this research aims to advance the field of neural networks by developing new techniques to improve performance, enable private inference, and learn complex functions from limited data.
Technical Explanation
The paper introduces Polynomial Augmented Neural Networks (PANNs), a novel neural network architecture that integrates polynomial functions to enhance the performance of neural networks on tasks involving "weak orthogonality." The authors demonstrate that PANNs can outperform standard neural networks on such tasks.
The paper also presents an Optimized Layerwise Approximation (OLA) method for efficient and private inference with fully connected neural networks. OLA allows for fast and secure inference by approximating the neural network layers, which could be beneficial for applications that require protecting sensitive data.
Furthermore, the researchers explore learning smooth functions in high dimensions from sparse data using a physics-informed neural network (PINN) approach. PINNs leverage physical constraints to guide the learning process and can effectively capture complex function behaviors from limited data.
Finally, the paper unveils the optimization process of PINNs, providing insights into the convergence and performance characteristics of this approach.
Critical Analysis
The paper presents several innovative techniques that address important challenges in the field of neural networks. However, the authors acknowledge some limitations and areas for future research:
- The performance of PANNs may be sensitive to the choice of polynomial functions, and further investigation is needed to understand the best strategies for selecting and integrating these functions.
- The OLA method for efficient private inference relies on approximating the neural network layers, which could introduce some accuracy trade-offs. The authors suggest exploring alternative approaches to maintain high performance while ensuring privacy.
- The PINN-based learning of smooth functions in high dimensions may require careful tuning of hyperparameters and a thorough understanding of the physical constraints being incorporated. Extending this approach to more complex real-world problems could be an area for future research.
Overall, the techniques presented in this paper offer promising directions for advancing the state-of-the-art in neural network architectures, efficient inference, and function learning from sparse data. However, as with any research, further exploration and validation will be necessary to fully understand the capabilities and limitations of these methods.
Conclusion
This paper proposes several innovative approaches to address key challenges in neural network research. The Polynomial Augmented Neural Networks (PANNs) architecture, the Optimized Layerwise Approximation (OLA) method for efficient private inference, and the exploration of learning smooth functions in high dimensions from sparse data using physics-informed neural networks (PINNs) all represent significant advancements in the field.
The insights gained from unveiling the optimization process of PINNs also contribute to our understanding of these powerful models. While the paper acknowledges some limitations and areas for future research, the proposed techniques have the potential to enable more efficient, robust, and data-efficient neural network-based solutions, with applications across a wide range of domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Networks with (Low-Precision) Polynomial Approximations: New Insights and Techniques for Accuracy Improvement
Chi Zhang, Jingjing Fan, Man Ho Au, Siu Ming Yiu
Replacing non-polynomial functions (e.g., non-linear activation functions such as ReLU) in a neural network with their polynomial approximations is a standard practice in privacy-preserving machine learning. The resulting neural network, called polynomial approximation of neural network (PANN) in this paper, is compatible with advanced cryptosystems to enable privacy-preserving model inference. Using ``highly precise'' approximation, state-of-the-art PANN offers similar inference accuracy as the underlying backbone model. However, little is known about the effect of approximation, and existing literature often determined the required approximation precision empirically. In this paper, we initiate the investigation of PANN as a standalone object. Specifically, our contribution is two-fold. Firstly, we provide an explanation on the effect of approximate error in PANN. In particular, we discovered that (1) PANN is susceptible to some type of perturbations; and (2) weight regularisation significantly reduces PANN's accuracy. We support our explanation with experiments. Secondly, based on the insights from our investigations, we propose solutions to increase inference accuracy for PANN. Experiments showed that combination of our solutions is very effective: at the same precision, our PANN is 10% to 50% more accurate than state-of-the-arts; and at the same accuracy, our PANN only requires a precision of 2^{-9} while state-of-the-art solution requires a precision of 2^{-12} using the ResNet-20 model on CIFAR-10 dataset.
Read more6/10/2024
0
Polynomial-Augmented Neural Networks (PANNs) with Weak Orthogonality Constraints for Enhanced Function and PDE Approximation
Madison Cooley, Shandian Zhe, Robert M. Kirby, Varun Shankar
We present polynomial-augmented neural networks (PANNs), a novel machine learning architecture that combines deep neural networks (DNNs) with a polynomial approximant. PANNs combine the strengths of DNNs (flexibility and efficiency in higher-dimensional approximation) with those of polynomial approximation (rapid convergence rates for smooth functions). To aid in both stable training and enhanced accuracy over a variety of problems, we present (1) a family of orthogonality constraints that impose mutual orthogonality between the polynomial and the DNN within a PANN; (2) a simple basis pruning approach to combat the curse of dimensionality introduced by the polynomial component; and (3) an adaptation of a polynomial preconditioning strategy to both DNNs and polynomials. We test the resulting architecture for its polynomial reproduction properties, ability to approximate both smooth functions and functions of limited smoothness, and as a method for the solution of partial differential equations (PDEs). Through these experiments, we demonstrate that PANNs offer superior approximation properties to DNNs for both regression and the numerical solution of PDEs, while also offering enhanced accuracy over both polynomial and DNN-based regression (each) when regressing functions with limited smoothness.
Read more6/5/2024
🤯
0
Optimized Layerwise Approximation for Efficient Private Inference on Fully Homomorphic Encryption
Junghyun Lee, Eunsang Lee, Young-Sik Kim, Yongwoo Lee, Joon-Woo Lee, Yongjune Kim, Jong-Seon No
Recent studies have explored the deployment of privacy-preserving deep neural networks utilizing homomorphic encryption (HE), especially for private inference (PI). Many works have attempted the approximation-aware training (AAT) approach in PI, changing the activation functions of a model to low-degree polynomials that are easier to compute on HE by allowing model retraining. However, due to constraints in the training environment, it is often necessary to consider post-training approximation (PTA), using the pre-trained parameters of the existing plaintext model without retraining. Existing PTA studies have uniformly approximated the activation function in all layers to a high degree to mitigate accuracy loss from approximation, leading to significant time consumption. This study proposes an optimized layerwise approximation (OLA), a systematic framework that optimizes both accuracy loss and time consumption by using different approximation polynomials for each layer in the PTA scenario. For efficient approximation, we reflect the layerwise impact on the classification accuracy by considering the actual input distribution of each activation function while constructing the optimization problem. Additionally, we provide a dynamic programming technique to solve the optimization problem and achieve the optimized layerwise degrees in polynomial time. As a result, the OLA method reduces inference times for the ResNet-20 model and the ResNet-32 model by 3.02 times and 2.82 times, respectively, compared to prior state-of-the-art implementations employing uniform degree polynomials. Furthermore, we successfully classified CIFAR-10 by replacing the GELU function in the ConvNeXt model with only 3-degree polynomials using the proposed method, without modifying the backbone model.
Read more5/30/2024
0
Learning smooth functions in high dimensions: from sparse polynomials to deep neural networks
Ben Adcock, Simone Brugiapaglia, Nick Dexter, Sebastian Moraga
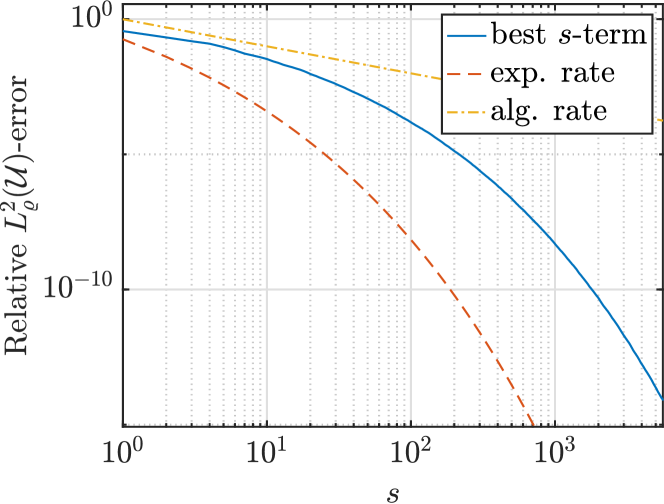
Learning approximations to smooth target functions of many variables from finite sets of pointwise samples is an important task in scientific computing and its many applications in computational science and engineering. Despite well over half a century of research on high-dimensional approximation, this remains a challenging problem. Yet, significant advances have been made in the last decade towards efficient methods for doing this, commencing with so-called sparse polynomial approximation methods and continuing most recently with methods based on Deep Neural Networks (DNNs). In tandem, there have been substantial advances in the relevant approximation theory and analysis of these techniques. In this work, we survey this recent progress. We describe the contemporary motivations for this problem, which stem from parametric models and computational uncertainty quantification; the relevant function classes, namely, classes of infinite-dimensional, Banach-valued, holomorphic functions; fundamental limits of learnability from finite data for these classes; and finally, sparse polynomial and DNN methods for efficiently learning such functions from finite data. For the latter, there is currently a significant gap between the approximation theory of DNNs and the practical performance of deep learning. Aiming to narrow this gap, we develop the topic of practical existence theory, which asserts the existence of dimension-independent DNN architectures and training strategies that achieve provably near-optimal generalization errors in terms of the amount of training data.
Read more4/8/2024