Neural Residual Diffusion Models for Deep Scalable Vision Generation
2406.13215
0
0

Abstract
The most advanced diffusion models have recently adopted increasingly deep stacked networks (e.g., U-Net or Transformer) to promote the generative emergence capabilities of vision generation models similar to large language models (LLMs). However, progressively deeper stacked networks will intuitively cause numerical propagation errors and reduce noisy prediction capabilities on generative data, which hinders massively deep scalable training of vision generation models. In this paper, we first uncover the nature that neural networks being able to effectively perform generative denoising lies in the fact that the intrinsic residual unit has consistent dynamic property with the input signal's reverse diffusion process, thus supporting excellent generative abilities. Afterwards, we stand on the shoulders of two common types of deep stacked networks to propose a unified and massively scalable Neural Residual Diffusion Models framework (Neural-RDM for short), which is a simple yet meaningful change to the common architecture of deep generative networks by introducing a series of learnable gated residual parameters that conform to the generative dynamics. Experimental results on various generative tasks show that the proposed neural residual models obtain state-of-the-art scores on image's and video's generative benchmarks. Rigorous theoretical proofs and extensive experiments also demonstrate the advantages of this simple gated residual mechanism consistent with dynamic modeling in improving the fidelity and consistency of generated content and supporting large-scale scalable training. Code is available at https://github.com/Anonymous/Neural-RDM.
Create account to get full access
Overview
- This paper introduces a novel deep learning model called Neural Residual Diffusion Models (NRDMs) for generating high-quality, scalable images.
- NRDMs build upon the recent success of diffusion models in image generation, aiming to address challenges like high computational cost and limited scalability.
- Key innovations include leveraging residual connections and multi-scale architectures to improve efficiency and generate images at higher resolutions.
Plain English Explanation
NRDMs are a new type of machine learning model that can create high-quality, detailed images. They build on a technique called diffusion models, which have shown great potential for image generation. However, diffusion models can be computationally expensive and have difficulty generating images at very high resolutions.
To address these challenges, the researchers developed NRDMs. These models use a special type of neural network architecture that includes "residual connections." This helps the model learn more efficiently and generate images faster. NRDMs also use a multi-scale approach, which means they work at different levels of detail to produce crisp, high-resolution images.
The key idea behind NRDMs is to combine the strengths of diffusion models with more efficient neural network designs. This allows them to generate high-quality images while using less computing power and memory compared to previous diffusion-based methods. The researchers demonstrate that NRDMs can generate realistic images at much higher resolutions than what was previously possible with diffusion models.
Technical Explanation
The paper introduces Neural Residual Diffusion Models (NRDMs), a novel deep learning architecture for scalable and high-quality image generation. NRDMs build upon the success of diffusion models for image synthesis, aiming to address their computational complexity and limited scalability.
The key innovations in NRDMs include:
-
Residual Connections: The model incorporates residual connections, which allow the network to learn more efficiently and generate images more quickly compared to standard diffusion models.
-
Multi-Scale Architecture: NRDMs use a multi-scale approach, processing the input at different levels of detail to produce high-resolution, photorealistic images. This helps overcome the resolution limitations of previous diffusion-based methods.
-
Efficient Training and Sampling: The researchers develop efficient training and sampling techniques for NRDMs, further improving their computational efficiency and scalability.
The paper presents extensive experiments demonstrating the capabilities of NRDMs. The models are able to generate diverse, high-quality images at much higher resolutions (up to 1024x1024 pixels) than previous diffusion-based approaches. NRDMs also show improved sample quality and computational efficiency compared to state-of-the-art generative models.
Critical Analysis
The paper makes a strong contribution by introducing NRDMs, a novel and effective approach for scalable, high-quality image generation using diffusion models. The key innovations, such as residual connections and multi-scale architecture, help address important limitations of previous diffusion-based methods.
However, the paper does not extensively discuss potential limitations or future research directions. For example, it would be valuable to understand the model's performance on more challenging or diverse datasets, as well as its robustness to distribution shift or adversarial attacks. Additionally, the paper could further examine the computational and memory requirements of NRDMs, especially at very high resolutions, and compare them to other efficient diffusion model variants, such as Missing-U-Net.
Overall, the research presented in this paper is a significant step forward in advancing the capabilities of diffusion models for image generation. The development of NRDMs demonstrates the potential for combining powerful generative models with efficient neural network architectures to achieve scalable, high-quality image synthesis.
Conclusion
The Neural Residual Diffusion Models (NRDMs) introduced in this paper represent an important advancement in the field of diffusion-based image generation. By incorporating residual connections and multi-scale processing, the researchers have developed a model that can generate high-resolution, photorealistic images more efficiently than previous diffusion-based approaches.
The demonstrated capabilities of NRDMs, particularly in terms of sample quality and computational scalability, suggest that this novel architecture could have a significant impact on applications requiring realistic and high-fidelity image synthesis, such as virtual content creation, image editing, and AI-assisted design. As the authors note, further research is needed to fully understand the model's limitations and explore potential extensions, but this work represents an exciting step forward in the ongoing development of powerful and practical deep generative models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
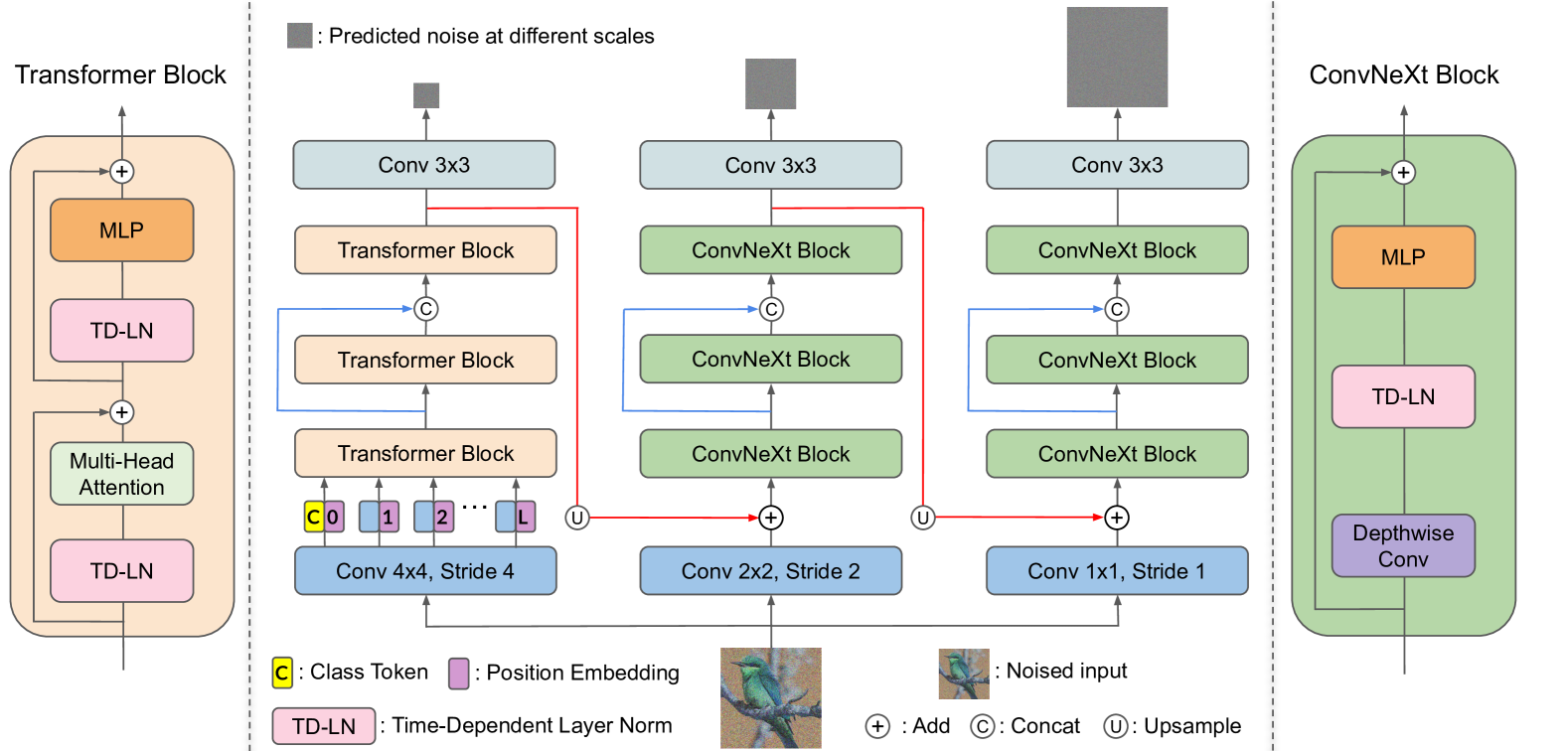
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
Qihao Liu, Zhanpeng Zeng, Ju He, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
0
0
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via patchification), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512. Project page: https://qihao067.github.io/projects/DiMR
6/14/2024
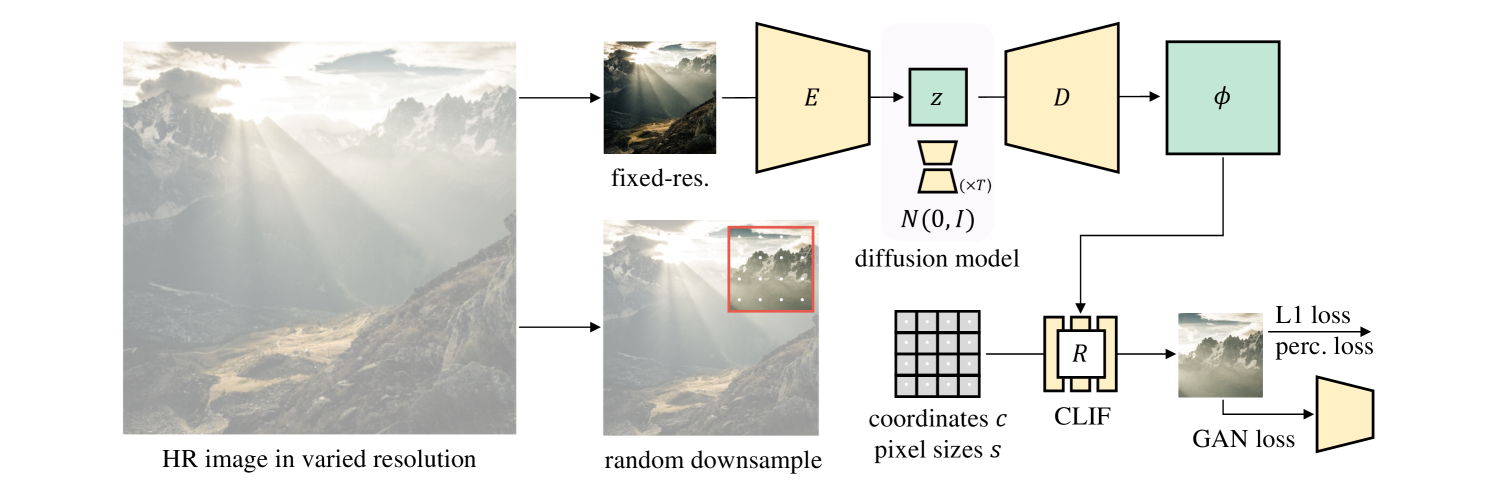
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024
🧠
Neural Diffusion Models
Grigory Bartosh, Dmitry Vetrov, Christian A. Naesseth
0
0
Diffusion models have shown remarkable performance on many generative tasks. Despite recent success, most diffusion models are restricted in that they only allow linear transformation of the data distribution. In contrast, broader family of transformations can potentially help train generative distributions more efficiently, simplifying the reverse process and closing the gap between the true negative log-likelihood and the variational approximation. In this paper, we present Neural Diffusion Models (NDMs), a generalization of conventional diffusion models that enables defining and learning time-dependent non-linear transformations of data. We show how to optimise NDMs using a variational bound in a simulation-free setting. Moreover, we derive a time-continuous formulation of NDMs, which allows fast and reliable inference using off-the-shelf numerical ODE and SDE solvers. Finally, we demonstrate the utility of NDMs with learnable transformations through experiments on standard image generation benchmarks, including CIFAR-10, downsampled versions of ImageNet and CelebA-HQ. NDMs outperform conventional diffusion models in terms of likelihood and produce high-quality samples.
6/4/2024

Diffusion Models in Low-Level Vision: A Survey
Chunming He, Yuqi Shen, Chengyu Fang, Fengyang Xiao, Longxiang Tang, Yulun Zhang, Wangmeng Zuo, Zhenhua Guo, Xiu Li
0
0
Deep generative models have garnered significant attention in low-level vision tasks due to their generative capabilities. Among them, diffusion model-based solutions, characterized by a forward diffusion process and a reverse denoising process, have emerged as widely acclaimed for their ability to produce samples of superior quality and diversity. This ensures the generation of visually compelling results with intricate texture information. Despite their remarkable success, a noticeable gap exists in a comprehensive survey that amalgamates these pioneering diffusion model-based works and organizes the corresponding threads. This paper proposes the comprehensive review of diffusion model-based techniques. We present three generic diffusion modeling frameworks and explore their correlations with other deep generative models, establishing the theoretical foundation. Following this, we introduce a multi-perspective categorization of diffusion models, considering both the underlying framework and the target task. Additionally, we summarize extended diffusion models applied in other tasks, including medical, remote sensing, and video scenarios. Moreover, we provide an overview of commonly used benchmarks and evaluation metrics. We conduct a thorough evaluation, encompassing both performance and efficiency, of diffusion model-based techniques in three prominent tasks. Finally, we elucidate the limitations of current diffusion models and propose seven intriguing directions for future research. This comprehensive examination aims to facilitate a profound understanding of the landscape surrounding denoising diffusion models in the context of low-level vision tasks. A curated list of diffusion model-based techniques in over 20 low-level vision tasks can be found at https://github.com/ChunmingHe/awesome-diffusion-models-in-low-level-vision.
6/18/2024