Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
2406.09416
0
0
Abstract
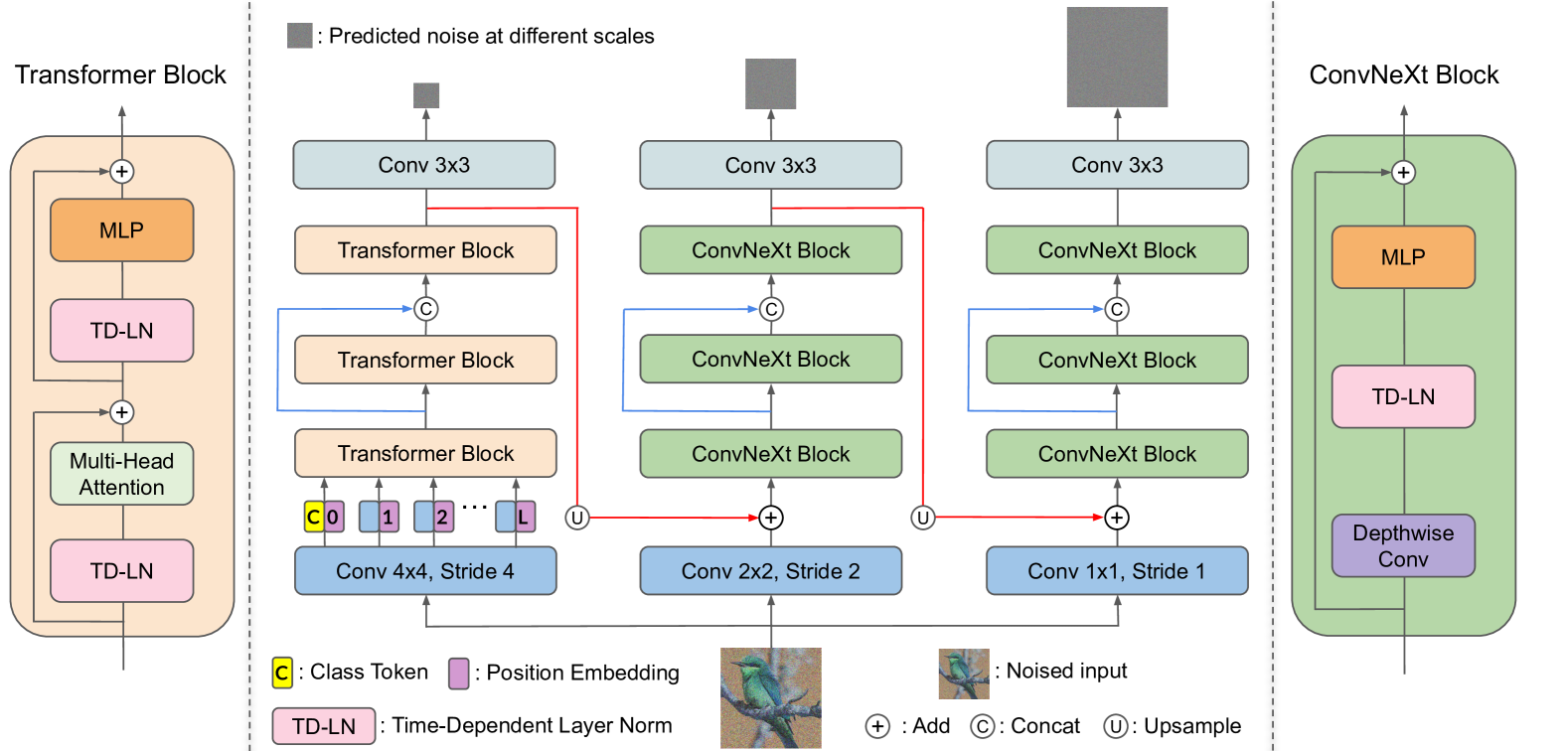
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via patchification), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512. Project page: https://qihao067.github.io/projects/DiMR
Create account to get full access
Overview
- Addresses the problem of distortion in image generation models
- Proposes a multi-resolution diffusion model approach to alleviate this issue
- Leverages pre-trained models and efficient training techniques for high-resolution image generation
Plain English Explanation
Image generation models, which create new images from scratch, often struggle with distortion - where the generated images have artifacts or imperfections. This paper presents a new approach to address this problem using multi-resolution diffusion models.
The key idea is to train the model to generate images at multiple resolutions simultaneously. This allows the model to learn the relationships between different levels of detail, helping it create higher-quality, less distorted images. The approach also builds on pre-trained models and efficient training techniques to enable generation of high-resolution images.
By using a multi-resolution approach, the model can better capture the structure and details of the images it is trying to generate. This results in more realistic and coherent outputs, without the unwanted distortions that plague many image generation systems. The techniques described in this paper represent an important step forward in improving the fidelity and realism of AI-generated imagery.
Technical Explanation
The paper introduces a multi-resolution diffusion model for image generation that is designed to alleviate distortion. The key innovations include:
-
Multi-Resolution Architecture: The model is structured to generate images at multiple resolutions in parallel, allowing it to learn the relationships between different levels of detail. This contrasts with typical single-resolution approaches.
-
Efficient Training: The model leverages pre-trained HiDiffusion and ImageNeural Field Diffusion models to enable efficient high-resolution image generation, building on previous advancements.
-
Progressive Generation: The model progressively generates images from low to high resolution, similar to techniques like DIM-Diffusion and Hierarchical Patch Diffusion.
-
Dual Diffusion Process: The model employs a dual diffusion process, with one stream focused on generating high-frequency details and another on low-frequency structure, to better capture the full range of image characteristics.
Through these innovations, the multi-resolution diffusion model is able to generate high-quality, high-resolution images with significantly reduced distortion compared to previous approaches. The techniques build on and integrate with other state-of-the-art diffusion models for image generation.
Critical Analysis
The paper presents a compelling approach to address the common issue of distortion in AI-generated images. The multi-resolution architecture and efficient training techniques are well-designed and build on previous advancements in the field.
One potential limitation is that the model may still struggle with certain types of high-frequency details or artifacts, as the dual diffusion process may not capture all nuances of image structure. Further research could explore ways to enhance the model's handling of these challenging image characteristics.
Additionally, the paper does not provide extensive comparisons to other leading image generation models, such as Diff-Mosaic, which have also demonstrated impressive results in reducing distortion. A more thorough benchmarking against these alternatives could help better situate the contributions of this work.
Overall, the multi-resolution diffusion model represents an important step forward in improving the realism and fidelity of AI-generated imagery. The techniques described in the paper are well-grounded in the latest advancements in diffusion models and could have significant implications for a wide range of applications that rely on high-quality image generation.
Conclusion
This paper introduces a novel multi-resolution diffusion model that effectively addresses the problem of distortion in AI-generated images. By leveraging a parallel multi-resolution architecture, efficient training techniques, and a dual diffusion process, the model is able to generate high-quality, high-resolution images with significantly reduced artifacts and imperfections.
The innovations described in this work build on and integrate with other state-of-the-art diffusion models, representing an important step forward in improving the realism and fidelity of synthetic imagery. As AI-generated images become increasingly prevalent in various applications, techniques like this multi-resolution diffusion model will be crucial for ensuring the integrity and usefulness of these generated assets.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, Jiajun Liang
0
0
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
4/30/2024

Neural Residual Diffusion Models for Deep Scalable Vision Generation
Zhiyuan Ma, Liangliang Zhao, Biqing Qi, Bowen Zhou
0
0
The most advanced diffusion models have recently adopted increasingly deep stacked networks (e.g., U-Net or Transformer) to promote the generative emergence capabilities of vision generation models similar to large language models (LLMs). However, progressively deeper stacked networks will intuitively cause numerical propagation errors and reduce noisy prediction capabilities on generative data, which hinders massively deep scalable training of vision generation models. In this paper, we first uncover the nature that neural networks being able to effectively perform generative denoising lies in the fact that the intrinsic residual unit has consistent dynamic property with the input signal's reverse diffusion process, thus supporting excellent generative abilities. Afterwards, we stand on the shoulders of two common types of deep stacked networks to propose a unified and massively scalable Neural Residual Diffusion Models framework (Neural-RDM for short), which is a simple yet meaningful change to the common architecture of deep generative networks by introducing a series of learnable gated residual parameters that conform to the generative dynamics. Experimental results on various generative tasks show that the proposed neural residual models obtain state-of-the-art scores on image's and video's generative benchmarks. Rigorous theoretical proofs and extensive experiments also demonstrate the advantages of this simple gated residual mechanism consistent with dynamic modeling in improving the fidelity and consistency of generated content and supporting large-scale scalable training. Code is available at https://github.com/Anonymous/Neural-RDM.
6/21/2024
Image Neural Field Diffusion Models
Yinbo Chen, Oliver Wang, Richard Zhang, Eli Shechtman, Xiaolong Wang, Michael Gharbi
0
0
Diffusion models have shown an impressive ability to model complex data distributions, with several key advantages over GANs, such as stable training, better coverage of the training distribution's modes, and the ability to solve inverse problems without extra training. However, most diffusion models learn the distribution of fixed-resolution images. We propose to learn the distribution of continuous images by training diffusion models on image neural fields, which can be rendered at any resolution, and show its advantages over fixed-resolution models. To achieve this, a key challenge is to obtain a latent space that represents photorealistic image neural fields. We propose a simple and effective method, inspired by several recent techniques but with key changes to make the image neural fields photorealistic. Our method can be used to convert existing latent diffusion autoencoders into image neural field autoencoders. We show that image neural field diffusion models can be trained using mixed-resolution image datasets, outperform fixed-resolution diffusion models followed by super-resolution models, and can solve inverse problems with conditions applied at different scales efficiently.
6/12/2024

DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Eunbyung Park
0
0
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
6/27/2024