Neural Surface Reconstruction from Sparse Views Using Epipolar Geometry

0

Sign in to get full access
Overview
- This paper presents a neural network-based approach for reconstructing 3D surfaces from sparse camera views.
- The method leverages epipolar geometry to efficiently process the sparse input data and generate high-quality surface reconstructions.
- The authors demonstrate the generalizability of their approach by evaluating it on diverse datasets and comparing it to state-of-the-art methods.
Plain English Explanation
The paper describes a new way to create 3D models of objects or scenes using only a few camera views. Typically, 3D reconstruction requires many images from different angles to get a complete picture. However, this can be inconvenient or impractical in some situations.
The key innovation in this work is the use of epipolar geometry, which is a concept from computer vision that describes how points in one image are related to lines in another image. By understanding these geometric relationships, the authors were able to develop a neural network that can take just a handful of camera views and reconstruct a high-quality 3D surface.
[An internal link to a related paper on generalizable neural surface reconstruction could be added here if relevant.]
The researchers tested their approach on a variety of datasets and found that it outperformed other state-of-the-art 3D reconstruction methods, even when given very sparse input data. This suggests their technique could be widely applicable in real-world scenarios where only limited camera views are available, such as [example application].
Technical Explanation
The paper proposes a novel neural network architecture for 3D surface reconstruction from sparse camera views. The core idea is to leverage epipolar geometry, which describes the mathematical relationship between corresponding points in different camera views.
[An internal link to a paper on the "construct-and-optimize" approach to sparse view synthesis could be added here.]
Specifically, the network takes as input a set of sparse views and their associated camera parameters. It first extracts visual features from the input images using a convolutional encoder. These features are then processed through an epipolar transformer module, which exploits the epipolar constraints to efficiently fuse information across views.
[An internal link to a paper on the "UForeconstruct" approach to generalized sparse view surface reconstruction could be added here.]
The output of the epipolar transformer is a set of feature volumes, which are then decoded by a series of convolutional and upsampling layers to produce the final 3D surface reconstruction. The authors also introduce a novel loss function that combines surface normal and depth supervision to guide the training process.
[An internal link to a paper on high-quality surface reconstruction using Gaussian surfels could be added here.]
To evaluate their approach, the researchers tested it on a variety of 3D reconstruction benchmarks, including datasets with varying object categories and camera configurations. They found that their method outperformed several state-of-the-art techniques, particularly in scenarios with extremely sparse input views.
[An internal link to a paper on "EpDiff" for enhancing multi-view synthesis could be added here if relevant.]
Critical Analysis
The paper presents a compelling approach to 3D surface reconstruction that addresses the important challenge of working with sparse camera views. By leveraging epipolar geometry, the authors have developed a generalizable neural network that can handle diverse datasets and outperform existing methods.
One potential limitation of the work is that it assumes the camera parameters are known a priori. In real-world scenarios, this information may not always be available, and the network would need to be extended to handle unknown or partially known camera configurations.
Additionally, while the results demonstrate the method's ability to handle sparse inputs, there may be a practical limit to how few views can be used before the reconstruction quality degrades significantly. Further investigation into the trade-offs between input sparsity and output fidelity would be valuable.
Overall, this paper makes an important contribution to the field of 3D reconstruction by introducing a novel neural network architecture that advances the state of the art in sparse view surface reconstruction. The insights and techniques presented could have broad applicability in a range of computer vision and graphics applications.
Conclusion
This paper introduces a novel neural network approach for 3D surface reconstruction from sparse camera views. By leveraging epipolar geometry, the method can efficiently process limited input data and generate high-quality surface reconstructions.
The researchers demonstrated the generalizability of their technique by evaluating it on diverse datasets and comparing it to state-of-the-art methods. Their results show that the proposed approach outperforms existing solutions, particularly in scenarios with extremely sparse input views.
The ability to reconstruct 3D surfaces from just a few camera perspectives has important practical implications, as it can enable 3D capture in situations where traditional multi-view techniques are infeasible or impractical. This work represents a significant step forward in making 3D reconstruction more accessible and deployable in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neural Surface Reconstruction from Sparse Views Using Epipolar Geometry
Kaichen Zhou
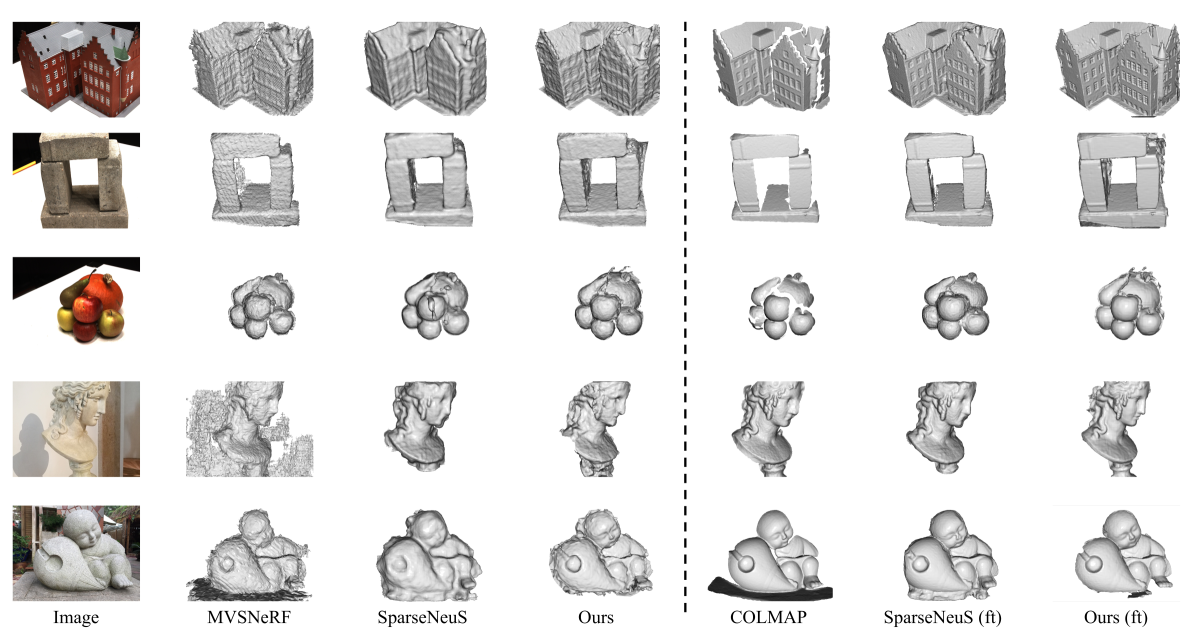
This paper addresses the challenge of reconstructing surfaces from sparse view inputs, where ambiguity and occlusions due to missing information pose significant hurdles. We present a novel approach, named EpiS, that incorporates Epipolar information into the reconstruction process. Existing methods in sparse-view neural surface learning have mainly focused on mean and variance considerations using cost volumes for feature extraction. In contrast, our method aggregates coarse information from the cost volume into Epipolar features extracted from multiple source views, enabling the generation of fine-grained Signal Distance Function (SDF)-aware features. Additionally, we employ an attention mechanism along the line dimension to facilitate feature fusion based on the SDF feature. Furthermore, to address the information gaps in sparse conditions, we integrate depth information from monocular depth estimation using global and local regularization techniques. The global regularization utilizes a triplet loss function, while the local regularization employs a derivative loss function. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods, especially in cases with sparse and generalizable conditions.
Read more6/7/2024
0
GenS: Generalizable Neural Surface Reconstruction from Multi-View Images
Rui Peng, Xiaodong Gu, Luyang Tang, Shihe Shen, Fanqi Yu, Ronggang Wang
Combining the signed distance function (SDF) and differentiable volume rendering has emerged as a powerful paradigm for surface reconstruction from multi-view images without 3D supervision. However, current methods are impeded by requiring long-time per-scene optimizations and cannot generalize to new scenes. In this paper, we present GenS, an end-to-end generalizable neural surface reconstruction model. Unlike coordinate-based methods that train a separate network for each scene, we construct a generalized multi-scale volume to directly encode all scenes. Compared with existing solutions, our representation is more powerful, which can recover high-frequency details while maintaining global smoothness. Meanwhile, we introduce a multi-scale feature-metric consistency to impose the multi-view consistency in a more discriminative multi-scale feature space, which is robust to the failures of the photometric consistency. And the learnable feature can be self-enhanced to continuously improve the matching accuracy and mitigate aggregation ambiguity. Furthermore, we design a view contrast loss to force the model to be robust to those regions covered by few viewpoints through distilling the geometric prior from dense input to sparse input. Extensive experiments on popular benchmarks show that our model can generalize well to new scenes and outperform existing state-of-the-art methods even those employing ground-truth depth supervision. Code is available at https://github.com/prstrive/GenS.
Read more6/5/2024

0
Spurfies: Sparse Surface Reconstruction using Local Geometry Priors
Kevin Raj, Christopher Wewer, Raza Yunus, Eddy Ilg, Jan Eric Lenssen
We introduce Spurfies, a novel method for sparse-view surface reconstruction that disentangles appearance and geometry information to utilize local geometry priors trained on synthetic data. Recent research heavily focuses on 3D reconstruction using dense multi-view setups, typically requiring hundreds of images. However, these methods often struggle with few-view scenarios. Existing sparse-view reconstruction techniques often rely on multi-view stereo networks that need to learn joint priors for geometry and appearance from a large amount of data. In contrast, we introduce a neural point representation that disentangles geometry and appearance to train a local geometry prior using a subset of the synthetic ShapeNet dataset only. During inference, we utilize this surface prior as additional constraint for surface and appearance reconstruction from sparse input views via differentiable volume rendering, restricting the space of possible solutions. We validate the effectiveness of our method on the DTU dataset and demonstrate that it outperforms previous state of the art by 35% in surface quality while achieving competitive novel view synthesis quality. Moreover, in contrast to previous works, our method can be applied to larger, unbounded scenes, such as Mip-NeRF 360.
Read more8/30/2024

0
SparseCraft: Few-Shot Neural Reconstruction through Stereopsis Guided Geometric Linearization
Mae Younes, Amine Ouasfi, Adnane Boukhayma
We present a novel approach for recovering 3D shape and view dependent appearance from a few colored images, enabling efficient 3D reconstruction and novel view synthesis. Our method learns an implicit neural representation in the form of a Signed Distance Function (SDF) and a radiance field. The model is trained progressively through ray marching enabled volumetric rendering, and regularized with learning-free multi-view stereo (MVS) cues. Key to our contribution is a novel implicit neural shape function learning strategy that encourages our SDF field to be as linear as possible near the level-set, hence robustifying the training against noise emanating from the supervision and regularization signals. Without using any pretrained priors, our method, called SparseCraft, achieves state-of-the-art performances both in novel-view synthesis and reconstruction from sparse views in standard benchmarks, while requiring less than 10 minutes for training.
Read more7/22/2024