SparseCraft: Few-Shot Neural Reconstruction through Stereopsis Guided Geometric Linearization

0

Sign in to get full access
Overview
- The paper introduces "SparseCraft," a method for neural reconstruction of 3D scenes from sparse input views
- It leverages stereopsis to guide a geometric linearization process, enabling high-quality reconstruction from just a few input images
- The key innovations are a neural encoding of 3D geometry, and the use of stereopsis to efficiently optimize this representation
Plain English Explanation
The research paper describes a new technique called "SparseCraft" that can reconstruct 3D scenes from just a handful of input images. Typically, 3D reconstruction requires many images to build an accurate model, but the authors have found a way to do it with far fewer.
The key insight is to use "stereopsis" - the process the human visual system uses to perceive depth from the slight difference between what each eye sees. By leveraging this stereoscopic information, the researchers can efficiently optimize a neural representation of the 3D geometry, even when only a sparse set of input images is available.
This allows SparseCraft to create high-quality 3D reconstructions from just a few photos, rather than requiring dozens or hundreds like previous methods. The researchers demonstrate that their approach can faithfully capture complex 3D environments from limited data.
Technical Explanation
The core of the SparseCraft method is a neural encoding of 3D geometry that can be efficiently optimized from sparse input views. The key innovation is the use of stereopsis to guide this optimization process.
Specifically, the system takes in a small number of input images (e.g. 2-5) and uses a neural network to produce a compact latent representation of the 3D scene. This latent code encodes the scene's geometry, appearance, and other relevant properties.
To optimize this latent representation from the sparse input views, the researchers leverage geometric constraints derived from stereopsis. By modeling the disparity between the input images, the system can estimate the underlying 3D structure and use this to guide the refinement of the neural scene representation. This "stereopsis guided geometric linearization" allows the latent code to be efficiently updated to faithfully capture the 3D scene, even when only a few input images are available.
The authors demonstrate that this approach allows for high-quality 3D reconstruction from just 2-5 input views, outperforming previous sparse-view techniques that rely on more input data or hand-engineered geometric priors.
Critical Analysis
The key strength of the SparseCraft approach is its ability to faithfully reconstruct complex 3D scenes from very limited input data. By leveraging stereopsis, the system can efficiently optimize a neural representation of the geometry, avoiding the need for a dense set of views that plague many traditional 3D reconstruction techniques.
That said, the paper does not extensively explore the limitations of this approach. For example, it is unclear how well SparseCraft would perform in cases with significant occlusion or very sparse viewpoints. The authors also do not discuss potential biases or failure modes that could arise from the stereopsis-guided optimization.
Additionally, while the neural encoding of 3D geometry is a powerful idea, the specific architecture and training procedure are not described in great detail. Further exposition on the representational capacity and optimization dynamics of this latent code would help readers better understand the technical contributions.
Overall, the SparseCraft method represents an interesting advance in few-shot 3D reconstruction, but additional analysis of its strengths, weaknesses, and failure cases would strengthen the paper and help the community better evaluate its significance and potential impact.
Conclusion
The SparseCraft paper introduces a novel technique for reconstructing 3D scenes from just a handful of input images. By leveraging stereopsis to guide the optimization of a neural representation of the scene geometry, the system can faithfully capture complex environments even with very sparse input data.
This work opens up exciting possibilities for 3D reconstruction in scenarios where capturing a dense set of views is impractical or infeasible, such as robotics, augmented reality, or content creation. If the approach can be further refined and its limitations better understood, it could become a powerful tool for efficiently building 3D models from limited data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SparseCraft: Few-Shot Neural Reconstruction through Stereopsis Guided Geometric Linearization
Mae Younes, Amine Ouasfi, Adnane Boukhayma
We present a novel approach for recovering 3D shape and view dependent appearance from a few colored images, enabling efficient 3D reconstruction and novel view synthesis. Our method learns an implicit neural representation in the form of a Signed Distance Function (SDF) and a radiance field. The model is trained progressively through ray marching enabled volumetric rendering, and regularized with learning-free multi-view stereo (MVS) cues. Key to our contribution is a novel implicit neural shape function learning strategy that encourages our SDF field to be as linear as possible near the level-set, hence robustifying the training against noise emanating from the supervision and regularization signals. Without using any pretrained priors, our method, called SparseCraft, achieves state-of-the-art performances both in novel-view synthesis and reconstruction from sparse views in standard benchmarks, while requiring less than 10 minutes for training.
Read more7/22/2024
0
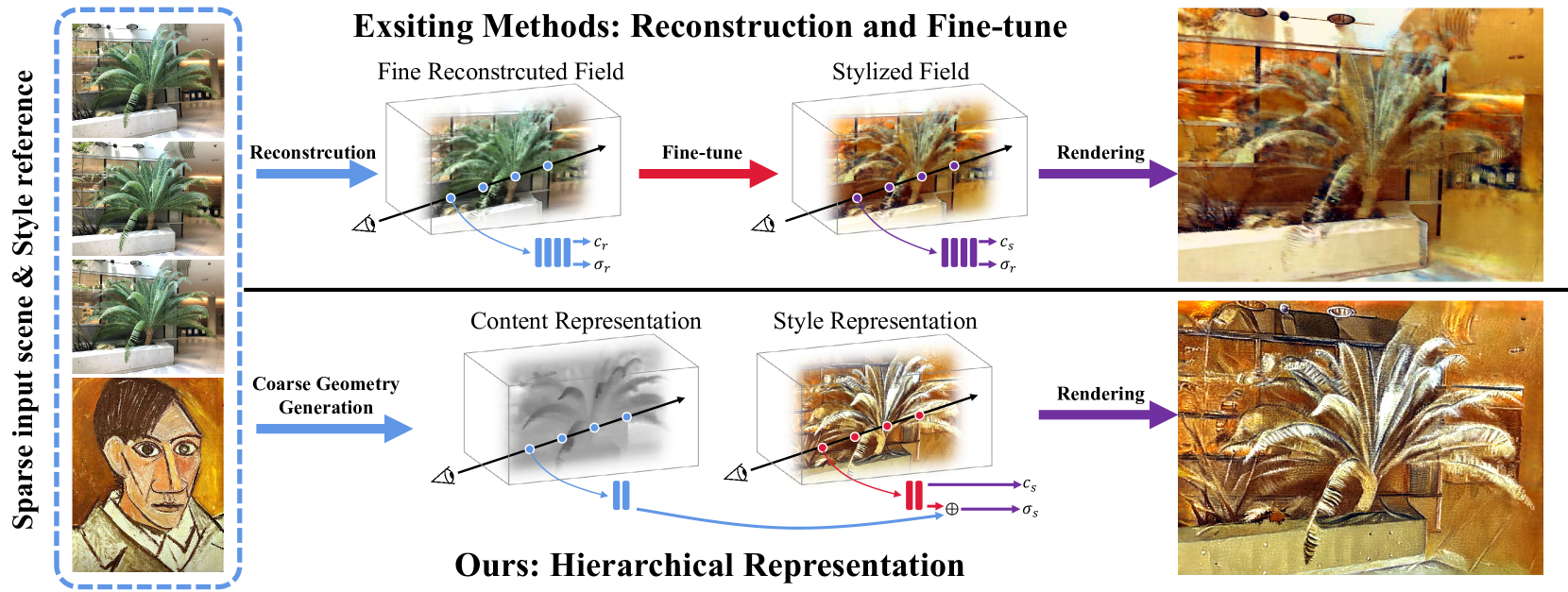
Stylizing Sparse-View 3D Scenes with Hierarchical Neural Representation
Y. Wang, A. Gao, Y. Gong, Y. Zeng
Recently, a surge of 3D style transfer methods has been proposed that leverage the scene reconstruction power of a pre-trained neural radiance field (NeRF). To successfully stylize a scene this way, one must first reconstruct a photo-realistic radiance field from collected images of the scene. However, when only sparse input views are available, pre-trained few-shot NeRFs often suffer from high-frequency artifacts, which are generated as a by-product of high-frequency details for improving reconstruction quality. Is it possible to generate more faithful stylized scenes from sparse inputs by directly optimizing encoding-based scene representation with target style? In this paper, we consider the stylization of sparse-view scenes in terms of disentangling content semantics and style textures. We propose a coarse-to-fine sparse-view scene stylization framework, where a novel hierarchical encoding-based neural representation is designed to generate high-quality stylized scenes directly from implicit scene representations. We also propose a new optimization strategy with content strength annealing to achieve realistic stylization and better content preservation. Extensive experiments demonstrate that our method can achieve high-quality stylization of sparse-view scenes and outperforms fine-tuning-based baselines in terms of stylization quality and efficiency.
Read more4/9/2024
🏋️
0
A Construct-Optimize Approach to Sparse View Synthesis without Camera Pose
Kaiwen Jiang, Yang Fu, Mukund Varma T, Yash Belhe, Xiaolong Wang, Hao Su, Ravi Ramamoorthi
Novel view synthesis from a sparse set of input images is a challenging problem of great practical interest, especially when camera poses are absent or inaccurate. Direct optimization of camera poses and usage of estimated depths in neural radiance field algorithms usually do not produce good results because of the coupling between poses and depths, and inaccuracies in monocular depth estimation. In this paper, we leverage the recent 3D Gaussian splatting method to develop a novel construct-and-optimize method for sparse view synthesis without camera poses. Specifically, we construct a solution progressively by using monocular depth and projecting pixels back into the 3D world. During construction, we optimize the solution by detecting 2D correspondences between training views and the corresponding rendered images. We develop a unified differentiable pipeline for camera registration and adjustment of both camera poses and depths, followed by back-projection. We also introduce a novel notion of an expected surface in Gaussian splatting, which is critical to our optimization. These steps enable a coarse solution, which can then be low-pass filtered and refined using standard optimization methods. We demonstrate results on the Tanks and Temples and Static Hikes datasets with as few as three widely-spaced views, showing significantly better quality than competing methods, including those with approximate camera pose information. Moreover, our results improve with more views and outperform previous InstantNGP and Gaussian Splatting algorithms even when using half the dataset. Project page: https://raymondjiangkw.github.io/cogs.github.io/
Read more6/12/2024
0
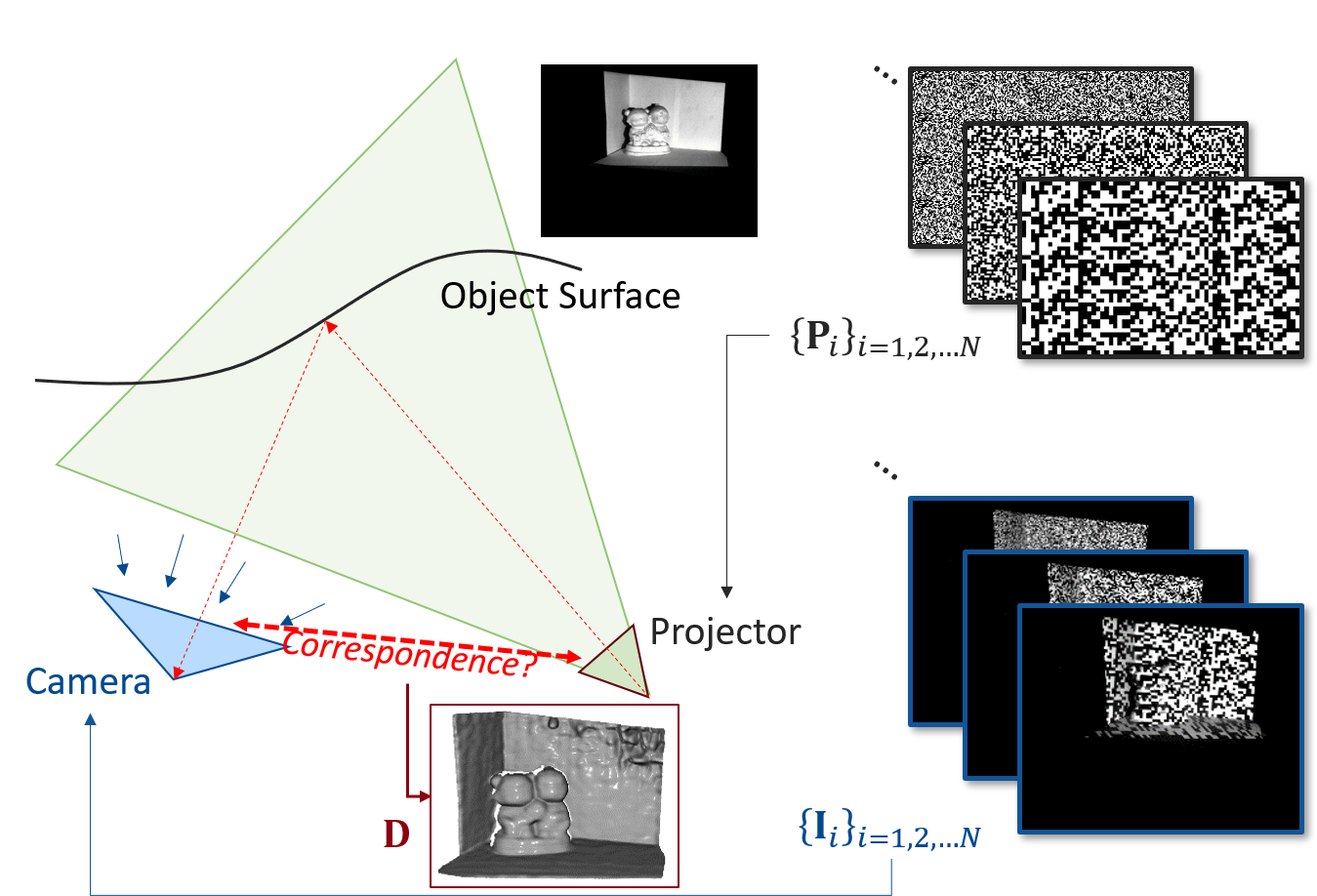
Depth Reconstruction with Neural Signed Distance Fields in Structured Light Systems
Rukun Qiao, Hiroshi Kawasaki, Hongbin Zha
We introduce a novel depth estimation technique for multi-frame structured light setups using neural implicit representations of 3D space. Our approach employs a neural signed distance field (SDF), trained through self-supervised differentiable rendering. Unlike passive vision, where joint estimation of radiance and geometry fields is necessary, we capitalize on known radiance fields from projected patterns in structured light systems. This enables isolated optimization of the geometry field, ensuring convergence and network efficacy with fixed device positioning. To enhance geometric fidelity, we incorporate an additional color loss based on object surfaces during training. Real-world experiments demonstrate our method's superiority in geometric performance for few-shot scenarios, while achieving comparable results with increased pattern availability.
Read more5/21/2024