NeuralMatrix: Compute the Entire Neural Networks with Linear Matrix Operations for Efficient Inference

0
🧠
Sign in to get full access
Overview
- The paper introduces NeuralMatrix, a technique that transforms deep neural network (DNN) computations into linear matrix operations.
- This allows running various DNN models efficiently on a single general matrix multiplication (GEMM) accelerator.
- Experiments show NeuralMatrix can achieve 2.17-38.72 times better computation efficiency compared to CPUs, GPUs, and SoC platforms.
Plain English Explanation
The paper discusses a method called NeuralMatrix that can help make deep learning models run more efficiently on hardware. Deep learning models often require specialized hardware units to execute different types of computations. This can make the hardware less efficient, leading to slower performance and higher power consumption.
NeuralMatrix solves this by transforming all the computations in a deep learning model into simple matrix operations. This allows the model to run on a single type of accelerator designed for matrix multiplication, rather than needing different specialized units. The experiments show this approach can make the models 2-39 times more efficient in terms of throughput per watt of power compared to general-purpose CPUs, GPUs, and system-on-chip platforms. This level of efficiency is usually only possible with custom accelerators designed for a specific neural network.
Technical Explanation
The paper introduces NeuralMatrix, a technique that can transform the computations within deep neural network (DNN) models into linear matrix operations. This allows running diverse DNN models, including both convolutional neural networks (CNNs) and transformer-based models, efficiently on a single general matrix multiplication (GEMM) accelerator.
Typically, the inherent diversity of computations required by different DNN models necessitates the use of specialized hardware units, which limits computational efficiency and increases both inference latency and power consumption. NeuralMatrix addresses this by elastically converting all DNN computations into matrix operations, enabling seamless execution on a GEMM accelerator.
The authors conduct extensive experiments comparing the performance of NeuralMatrix against CPUs, GPUs, and system-on-chip (SoC) platforms. The results demonstrate that NeuralMatrix can achieve 2.17-38.72 times better computation efficiency, measured as throughput per power, than these general-purpose devices. This level of efficiency is typically only attainable with custom accelerators designed for specific neural network architectures.
Critical Analysis
The paper presents a promising approach to improving the efficiency of deep learning models on hardware. By transforming the computations into a unified matrix format, NeuralMatrix enables the use of a single GEMM accelerator to run a wide range of DNN models, which can lead to significant efficiency gains.
However, the paper does not address potential limitations or challenges with this approach. For example, it's unclear how the matrix transformation process might impact the model's accuracy or whether there are any constraints on the types of DNN architectures that can be supported. Additionally, the paper does not discuss the overhead or complexity of the transformation process itself, which could be an important consideration in real-world deployment.
Further research could explore the generalizability of NeuralMatrix, its impact on model accuracy, and the tradeoffs involved in the transformation process. It would also be valuable to see how NeuralMatrix compares to other approaches for improving DNN hardware efficiency, such as open-source frameworks for efficient numerically-tailored computations or fast, scalable, and energy-efficient non-element-wise operations.
Conclusion
The NeuralMatrix approach presented in this paper offers a promising solution to the challenge of efficiently executing diverse deep learning models on hardware. By transforming DNN computations into a unified matrix format, NeuralMatrix enables the use of a single GEMM accelerator to run a wide range of models, resulting in significant improvements in computation efficiency.
The authors' experiments demonstrate the potential of this approach, with NeuralMatrix achieving up to 38.72 times better throughput per watt compared to general-purpose CPUs, GPUs, and SoC platforms. This level of efficiency is typically only possible with custom accelerators designed for specific neural network architectures.
While the paper does not address all potential limitations and challenges, the NeuralMatrix technique represents an important step towards more efficient and versatile deep learning hardware. Further research to explore the generalizability, accuracy impact, and tradeoffs of this approach could lead to even greater advancements in the field of deep learning hardware acceleration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
NeuralMatrix: Compute the Entire Neural Networks with Linear Matrix Operations for Efficient Inference
Ruiqi Sun, Siwei Ye, Jie Zhao, Xin He, Jianzhe Lin, Yiran Li, An Zou
The inherent diversity of computation types within the deep neural network (DNN) models often requires a variety of specialized units in hardware processors, which limits computational efficiency, increasing both inference latency and power consumption, especially when the hardware processor needs to support and execute different neural networks. In this study, we introduce NeuralMatrix, which elastically transforms the computations of entire DNNs into linear matrix operations. This transformation allows seamless execution of various DNN models all with matrix operations and paves the way for running versatile DNN models with a single General Matrix Multiplication (GEMM) accelerator.Extensive experiments with both CNN and transformer-based models demonstrate the potential of NeuralMatrix to accurately and efficiently execute a wide range of DNN models, achieving 2.17-38.72 times computation efficiency (i.e., throughput per power) compared to CPUs, GPUs, and SoC platforms. This level of efficiency is usually only attainable with the accelerator designed for a specific neural network.
Read more8/21/2024
0
Enabling Accelerators for Graph Computing
Kaustubh Shivdikar
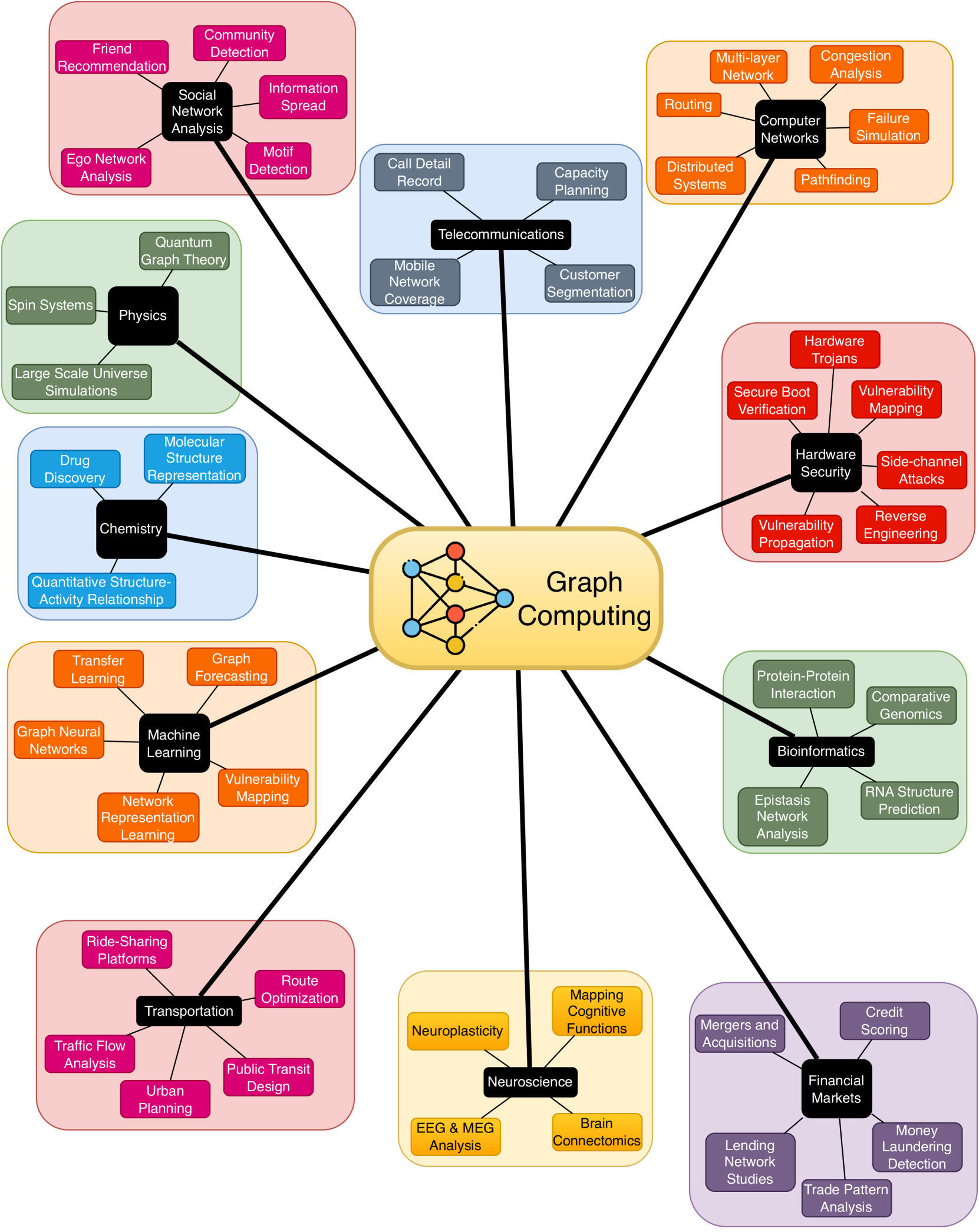
The advent of Graph Neural Networks (GNNs) has revolutionized the field of machine learning, offering a novel paradigm for learning on graph-structured data. Unlike traditional neural networks, GNNs are capable of capturing complex relationships and dependencies inherent in graph data, making them particularly suited for a wide range of applications including social network analysis, molecular chemistry, and network security. GNNs, with their unique structure and operation, present new computational challenges compared to conventional neural networks. This requires comprehensive benchmarking and a thorough characterization of GNNs to obtain insight into their computational requirements and to identify potential performance bottlenecks. In this thesis, we aim to develop a better understanding of how GNNs interact with the underlying hardware and will leverage this knowledge as we design specialized accelerators and develop new optimizations, leading to more efficient and faster GNN computations. A pivotal component within GNNs is the Sparse General Matrix-Matrix Multiplication (SpGEMM) kernel, known for its computational intensity and irregular memory access patterns. In this thesis, we address the challenges posed by SpGEMM by implementing a highly optimized hashing-based SpGEMM kernel tailored for a custom accelerator. Synthesizing these insights and optimizations, we design state-of-the-art hardware accelerators capable of efficiently handling various GNN workloads. Our accelerator architectures are built on our characterization of GNN computational demands, providing clear motivation for our approaches. This exploration into novel models underlines our comprehensive approach, as we strive to enable accelerators that are not just performant, but also versatile, able to adapt to the evolving landscape of graph computing.
Read more5/7/2024

0
An Open-Source Framework for Efficient Numerically-Tailored Computations
Louis Ledoux, Marc Casas
We present a versatile open-source framework designed to facilitate efficient, numerically-tailored Matrix-Matrix Multiplications (MMMs). The framework offers two primary contributions: first, a fine-tuned, automated pipeline for arithmetic datapath generation, enabling highly customizable systolic MMM kernels; second, seamless integration of the generated kernels into user code, irrespective of the programming language employed, without necessitating modifications. The framework demonstrates a systematic enhancement in accuracy per energy cost across diverse High Performance Computing (HPC) workloads displaying a variety of numerical requirements, such as Artificial Intelligence (AI) inference and Sea Surface Height (SSH) computation. For AI inference, we consider a set of state-of-the-art neural network models, namely ResNet18, ResNet34, ResNet50, DenseNet121, DenseNet161, DenseNet169, and VGG11, in conjunction with two datasets, two computer formats, and 27 distinct intermediate arithmetic datapaths. Our approach consistently reduces energy consumption across all cases, with a notable example being the reduction by factors of $3.3times$ for IEEE754-32 and $1.4times$ for Bfloat16 during ImageNet inference with ResNet50. This is accomplished while maintaining accuracies of $82.3%$ and $86%$, comparable to those achieved with conventional Floating-Point Units (FPUs). In the context of SSH computation, our method achieves fully-reproducible results using double-precision words, surpassing the accuracy of conventional double- and quad-precision arithmetic in FPUs. Our approach enhances SSH computation accuracy by a minimum of $5times$ and $27times$ compared to IEEE754-64 and IEEE754-128, respectively, resulting in $5.6times$ and $15.1times$ improvements in accuracy per power cost.
Read more6/6/2024

0
New!Automatic Generation of Fast and Accurate Performance Models for Deep Neural Network Accelerators
Konstantin Lubeck, Alexander Louis-Ferdinand Jung, Felix Wedlich, Mika Markus Muller, Federico Nicol'as Peccia, Felix Thommes, Jannik Steinmetz, Valentin Biermaier, Adrian Frischknecht, Paul Palomero Bernardo, Oliver Bringmann
Implementing Deep Neural Networks (DNNs) on resource-constrained edge devices is a challenging task that requires tailored hardware accelerator architectures and a clear understanding of their performance characteristics when executing the intended AI workload. To facilitate this, we present an automated generation approach for fast performance models to accurately estimate the latency of a DNN mapped onto systematically modeled and concisely described accelerator architectures. Using our accelerator architecture description method, we modeled representative DNN accelerators such as Gemmini, UltraTrail, Plasticine-derived, and a parameterizable systolic array. Together with DNN mappings for those modeled architectures, we perform a combined DNN/hardware dependency graph analysis, which enables us, in the best case, to evaluate only 154 loop kernel iterations to estimate the performance for 4.19 billion instructions achieving a significant speedup. We outperform regression and analytical models in terms of mean absolute percentage error (MAPE) compared to simulation results, while being several magnitudes faster than an RTL simulation.
Read more9/16/2024