Automatic Generation of Fast and Accurate Performance Models for Deep Neural Network Accelerators

0

Sign in to get full access
Overview
- A new approach for automatically generating fast and accurate performance models for deep neural network accelerators
- Enables rapid design exploration and optimization of hardware accelerators
- Combines analytical modeling with machine learning to achieve high accuracy and speed
Plain English Explanation
The paper presents a novel method for generating performance models for deep neural network accelerators. These performance models allow designers to quickly estimate the speed and efficiency of different hardware designs, which is crucial for optimizing deep learning hardware.
The key idea is to combine analytical modeling, which uses mathematical equations to capture the core performance characteristics, with machine learning techniques. This hybrid approach allows the models to be both fast to compute and highly accurate in their predictions. The analytical part ensures the models are interpretable and generalizable, while the machine learning component adapts the models to specific hardware and workloads.
The researchers demonstrate their method on a variety of deep learning accelerator designs and workloads, showing it can achieve over 90% accuracy compared to cycle-accurate simulations, while being 3 orders of magnitude faster. This enables rapid design space exploration and optimization, which is critical for developing efficient deep learning hardware and accelerators for graph computing.
Technical Explanation
The paper introduces a new methodology for automatically generating fast and accurate performance models for deep neural network accelerators. The key contributions are:
-
A hybrid modeling approach that combines analytical modeling and machine learning. The analytical model captures the core performance characteristics using mathematical equations, while the machine learning component adapts the model to specific hardware and workloads.
-
An automated model generation pipeline that takes in descriptions of the hardware architecture and the deep learning workloads, and outputs the performance models. This enables rapid design space exploration and optimization.
-
Extensive evaluation on a diverse set of deep learning accelerator designs and workloads, demonstrating over 90% accuracy compared to cycle-accurate simulations, while being 3 orders of magnitude faster.
The analytical model is based on queueing theory and accounts for factors like memory bandwidth, computational resources, and dataflow. The machine learning component uses neural networks to learn the residuals between the analytical model and the ground truth, further improving the accuracy.
The automated model generation pipeline first extracts the relevant architectural and workload parameters, then trains the hybrid performance model using a combination of the analytical model and machine learning. This allows the models to be quickly generated for new designs, enabling rapid design space exploration.
Critical Analysis
The paper presents a compelling approach for generating fast and accurate performance models for deep neural network accelerators. The hybrid modeling technique leverages the strengths of both analytical and machine learning methods, resulting in models that are interpretable, generalizable, and highly accurate.
One potential limitation is the reliance on having detailed architectural and workload descriptions as inputs to the model generation pipeline. In practice, this information may not always be available, especially for early-stage designs. The authors mention plans to investigate techniques for inferring these parameters from higher-level specifications.
Additionally, the evaluation was conducted on a limited set of accelerator designs and workloads. While the results are impressive, further testing on a wider range of real-world systems and applications would help demonstrate the broader applicability of the approach.
It would also be interesting to see how the performance models handle emerging trends like sparse and quantized neural networks, which can have significantly different computational and memory access patterns compared to dense, floating-point networks.
Overall, this work represents an important step forward in enabling efficient design of deep learning hardware, and the insights could potentially be extended to other domains beyond neural network accelerators.
Conclusion
The paper presents a novel method for automatically generating fast and accurate performance models for deep neural network accelerators. By combining analytical modeling and machine learning, the approach achieves high accuracy while maintaining computational efficiency, enabling rapid design space exploration and optimization.
The demonstrated results show the potential of this hybrid modeling technique to significantly accelerate the development of specialized deep learning hardware, which is crucial for meeting the ever-increasing computational demands of modern AI applications. Further research is needed to expand the capabilities of the models, but this work represents an important step forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Automatic Generation of Fast and Accurate Performance Models for Deep Neural Network Accelerators
Konstantin Lubeck, Alexander Louis-Ferdinand Jung, Felix Wedlich, Mika Markus Muller, Federico Nicol'as Peccia, Felix Thommes, Jannik Steinmetz, Valentin Biermaier, Adrian Frischknecht, Paul Palomero Bernardo, Oliver Bringmann
Implementing Deep Neural Networks (DNNs) on resource-constrained edge devices is a challenging task that requires tailored hardware accelerator architectures and a clear understanding of their performance characteristics when executing the intended AI workload. To facilitate this, we present an automated generation approach for fast performance models to accurately estimate the latency of a DNN mapped onto systematically modeled and concisely described accelerator architectures. Using our accelerator architecture description method, we modeled representative DNN accelerators such as Gemmini, UltraTrail, Plasticine-derived, and a parameterizable systolic array. Together with DNN mappings for those modeled architectures, we perform a combined DNN/hardware dependency graph analysis, which enables us, in the best case, to evaluate only 154 loop kernel iterations to estimate the performance for 4.19 billion instructions achieving a significant speedup. We outperform regression and analytical models in terms of mean absolute percentage error (MAPE) compared to simulation results, while being several magnitudes faster than an RTL simulation.
Read more9/16/2024

0
It's all about PR -- Smart Benchmarking AI Accelerators using Performance Representatives
Alexander Louis-Ferdinand Jung, Jannik Steinmetz, Jonathan Gietz, Konstantin Lubeck, Oliver Bringmann
Statistical models are widely used to estimate the performance of commercial off-the-shelf (COTS) AI hardware accelerators. However, training of statistical performance models often requires vast amounts of data, leading to a significant time investment and can be difficult in case of limited hardware availability. To alleviate this problem, we propose a novel performance modeling methodology that significantly reduces the number of training samples while maintaining good accuracy. Our approach leverages knowledge of the target hardware architecture and initial parameter sweeps to identify a set of Performance Representatives (PR) for deep neural network (DNN) layers. These PRs are then used for benchmarking, building a statistical performance model, and making estimations. This targeted approach drastically reduces the number of training samples needed, opposed to random sampling, to achieve a better estimation accuracy. We achieve a Mean Absolute Percentage Error (MAPE) of as low as 0.02% for single-layer estimations and 0.68% for whole DNN estimations with less than 10000 training samples. The results demonstrate the superiority of our method for single-layer estimations compared to models trained with randomly sampled datasets of the same size.
Read more6/13/2024
🤿
0
Workload-Aware Hardware Accelerator Mining for Distributed Deep Learning Training
Muhammad Adnan, Amar Phanishayee, Janardhan Kulkarni, Prashant J. Nair, Divya Mahajan
In this paper, we present a novel technique to search for hardware architectures of accelerators optimized for end-to-end training of deep neural networks (DNNs). Our approach addresses both single-device and distributed pipeline and tensor model parallel scenarios, latter being addressed for the first time. The search optimized accelerators for training relevant metrics such as throughput/TDP under a fixed area and power constraints. However, with the proliferation of specialized architectures and complex distributed training mechanisms, the design space exploration of hardware accelerators is very large. Prior work in this space has tried to tackle this by reducing the search space to either a single accelerator execution that too only for inference, or tuning the architecture for specific layers (e.g., convolution). Instead, we take a unique heuristic-based critical path-based approach to determine the best use of available resources (power and area) either for a set of DNN workloads or each workload individually. First, we perform local search to determine the architecture for each pipeline and tensor model stage. Specifically, the system iteratively generates architectural configurations and tunes the design using a novel heuristic-based approach that prioritizes accelerator resources and scheduling to critical operators in a machine learning workload. Second, to address the complexities of distributed training, the local search selects multiple (k) designs per stage. A global search then identifies an accelerator from the top-k sets to optimize training throughput across the stages. We evaluate this work on 11 different DNN models. Compared to a recent inference-only work Spotlight, our method converges to a design in, on average, 31x less time and offers 12x higher throughput. Moreover, designs generated using our method achieve 12% throughput improvement over TPU architecture.
Read more4/24/2024
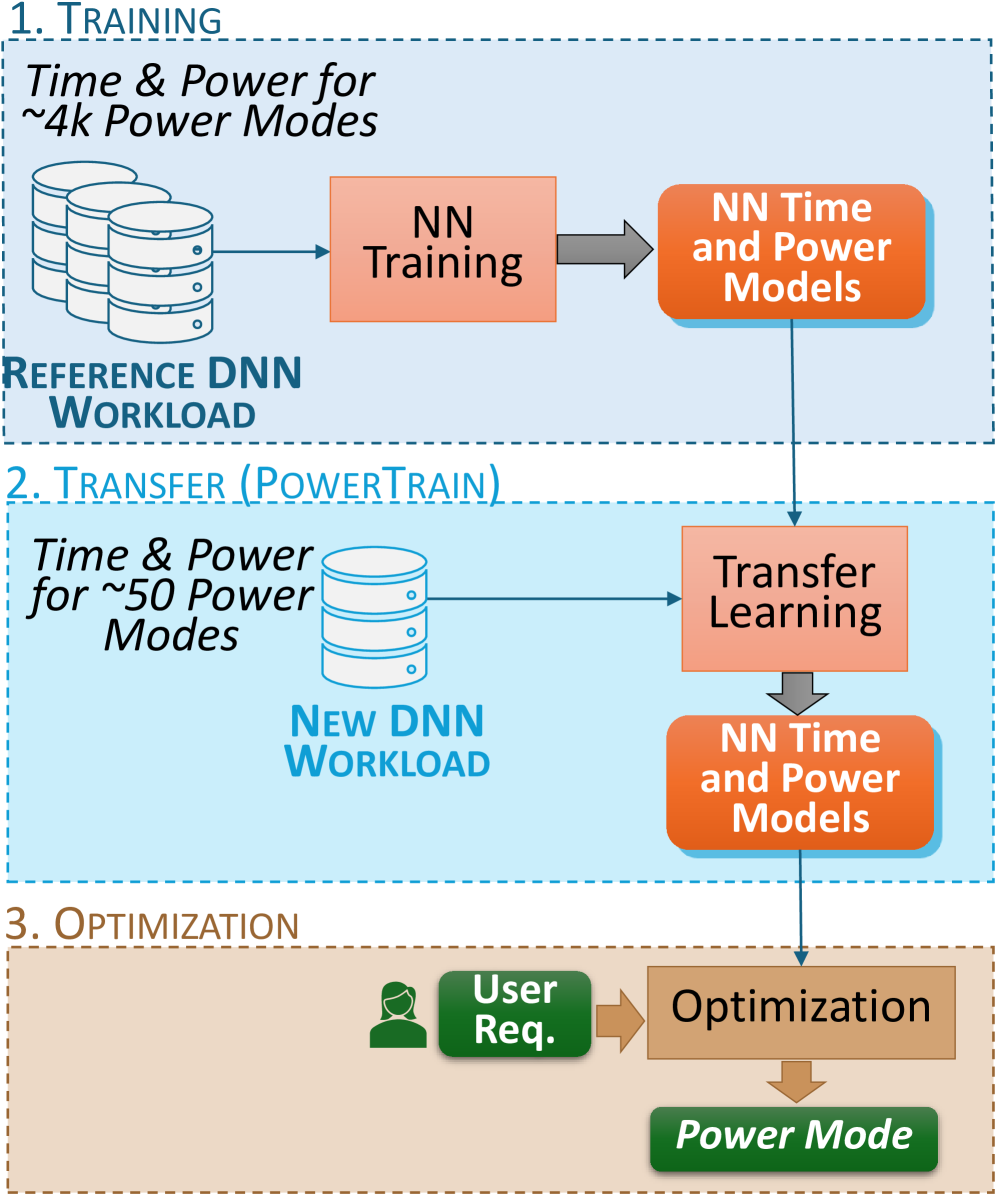
0
PowerTrain: Fast, Generalizable Time and Power Prediction Models to Optimize DNN Training on Accelerated Edges
Prashanthi S. K., Saisamarth Taluri, Beautlin S, Lakshya Karwa, Yogesh Simmhan
Accelerated edge devices, like Nvidia's Jetson with 1000+ CUDA cores, are increasingly used for DNN training and federated learning, rather than just for inferencing workloads. A unique feature of these compact devices is their fine-grained control over CPU, GPU, memory frequencies, and active CPU cores, which can limit their power envelope in a constrained setting while throttling the compute performance. Given this vast 10k+ parameter space, selecting a power mode for dynamically arriving training workloads to exploit power-performance trade-offs requires costly profiling for each new workload, or is done textit{ad hoc}. We propose textit{PowerTrain}, a transfer-learning approach to accurately predict the power and time consumed when training a given DNN workload (model + dataset) using any specified power mode (CPU/GPU/memory frequencies, core-count). It requires a one-time offline profiling of $1000$s of power modes for a reference DNN workload on a single Jetson device (Orin AGX) to build Neural Network (NN) based prediction models for time and power. These NN models are subsequently transferred (retrained) for a new DNN workload, or even a different Jetson device, with minimal additional profiling of just $50$ power modes to make accurate time and power predictions. These are then used to rapidly construct the Pareto front and select the optimal power mode for the new workload. PowerTrain's predictions are robust to new workloads, exhibiting a low MAPE of $<6%$ for power and $<15%$ for time on six new training workloads for up to $4400$ power modes, when transferred from a ResNet reference workload on Orin AGX. It is also resilient when transferred to two entirely new Jetson devices with prediction errors of $<14.5%$ and $<11%$. These outperform baseline predictions by more than $10%$ and baseline optimizations by up to $45%$ on time and $88%$ on power.
Read more7/22/2024