Neuromorphic Keyword Spotting with Pulse Density Modulation MEMS Microphones

0

Sign in to get full access
Overview
- The paper presents a neuromorphic approach to keyword spotting using pulse density modulation (PDM) MEMS microphones.
- The proposed method leverages the temporal sparsity and event-driven nature of PDM microphones to achieve efficient and low-power keyword spotting.
- Experiments demonstrate the effectiveness of the proposed method on a keyword spotting task, achieving high accuracy while consuming minimal power.
Plain English Explanation
The paper describes a new way to recognize spoken keywords using a type of microphone called a pulse density modulation (PDM) MEMS microphone. These microphones have some unique properties that make them well-suited for low-power applications.
Specifically, PDM microphones produce a stream of digital pulses that represent the sound they detect, rather than the continuous analog signal used in traditional microphones. This temporal sparsity - the fact that the microphone is only active when there is sound - allows for efficient processing and low power consumption.
The researchers developed a neuromorphic approach to keyword spotting that takes advantage of these PDM microphone properties. Their method uses a spiking neural network architecture that can directly process the sparse, event-driven PDM signal, without the need for energy-intensive analog-to-digital conversion.
Through experiments, the researchers demonstrate that their neuromorphic keyword spotting system can achieve high accuracy on a benchmark task while consuming very little power - an important consideration for potential applications like always-on voice interfaces for smart devices.
Technical Explanation
The key elements of the proposed neuromorphic keyword spotting method are:
-
PDM MEMS Microphone: The system uses a PDM MEMS microphone as the audio input. These microphones produce a stream of digital pulses that represent the sound pressure level, rather than a continuous analog signal.
-
Spiking Neural Network: The researchers developed a spiking neural network architecture to process the PDM microphone input directly, without the need for energy-intensive analog-to-digital conversion.
-
Temporal Sparsity: The event-driven, temporally sparse nature of the PDM microphone signal is a key enabler for the efficiency of the proposed neuromorphic approach. The spiking neural network can leverage this temporal sparsity to perform keyword spotting with low latency and power consumption.
-
Feature Extraction: The spiking neural network uses global and local convolution operations to extract relevant features from the PDM microphone input for keyword spotting.
-
Keyword Spotting: The final layer of the spiking neural network performs the keyword spotting classification task, identifying when a target keyword is spoken in the audio input.
Critical Analysis
The paper provides a strong technical demonstration of the benefits of using neuromorphic computing techniques, specifically spiking neural networks, for keyword spotting with PDM MEMS microphones. The results show that the proposed method can achieve high accuracy on a benchmark task while consuming very little power, making it well-suited for always-on voice interfaces and other low-power applications.
However, the paper does not address some potential limitations and areas for further research:
- The experiments are conducted on a relatively small dataset, so the generalization of the method to larger, more diverse datasets is not yet demonstrated.
- The paper does not explore the robustness of the system to noisy or challenging acoustic environments, which would be an important consideration for real-world deployments.
- While the power consumption is low, the paper does not provide a direct comparison to alternative keyword spotting approaches, such as those using traditional microphones and digital signal processing techniques.
Further research could investigate these areas to better understand the practical benefits and limitations of the proposed neuromorphic keyword spotting system.
Conclusion
This paper presents a novel neuromorphic approach to keyword spotting that leverages the unique properties of PDM MEMS microphones. By directly processing the temporally sparse, event-driven microphone signal with a spiking neural network, the researchers achieve high-accuracy keyword spotting with extremely low power consumption.
The results demonstrate the potential of neuromorphic computing techniques, such as spiking neural networks, to enable efficient and low-power voice interfaces for a wide range of smart devices and Internet of Things applications. As the field of neuromorphic computing continues to evolve, this work represents an important step towards realizing the practical benefits of these biologically-inspired approaches.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Neuromorphic Keyword Spotting with Pulse Density Modulation MEMS Microphones
Sidi Yaya Arnaud Yarga, Sean U. N. Wood
The Keyword Spotting (KWS) task involves continuous audio stream monitoring to detect predefined words, requiring low energy devices for continuous processing. Neuromorphic devices effectively address this energy challenge. However, the general neuromorphic KWS pipeline, from microphone to Spiking Neural Network (SNN), entails multiple processing stages. Leveraging the popularity of Pulse Density Modulation (PDM) microphones in modern devices and their similarity to spiking neurons, we propose a direct microphone-to-SNN connection. This approach eliminates intermediate stages, notably reducing computational costs. The system achieved an accuracy of 91.54% on the Google Speech Command (GSC) dataset, surpassing the state-of-the-art for the Spiking Speech Command (SSC) dataset which is a bio-inspired encoded GSC. Furthermore, the observed sparsity in network activity and connectivity indicates potential for remarkably low energy consumption in a neuromorphic device implementation.
Read more8/12/2024

0
Micro-power spoken keyword spotting on Xylo Audio 2
Hannah Bos, Dylan R. Muir
For many years, designs for Neuromorphic or brain-like processors have been motivated by achieving extreme energy efficiency, compared with von-Neumann and tensor processor devices. As part of their design language, Neuromorphic processors take advantage of weight, parameter, state and activity sparsity. In the extreme case, neural networks based on these principles mimic the sparse activity oof biological nervous systems, in ``Spiking Neural Networks'' (SNNs). Few benchmarks are available for Neuromorphic processors, that have been implemented for a range of Neuromorphic and non-Neuromorphic platforms, which can therefore demonstrate the energy benefits of Neuromorphic processor designs. Here we describes the implementation of a spoken audio keyword-spotting (KWS) benchmark Aloha on the Xylo Audio 2 (SYNS61210) Neuromorphic processor device. We obtained high deployed quantized task accuracy, (95%), exceeding the benchmark task accuracy. We measured real continuous power of the deployed application on Xylo. We obtained best-in-class dynamic inference power ($291mu$W) and best-in-class inference efficiency ($6.6mu$J / Inf). Xylo sets a new minimum power for the Aloha KWS benchmark, and highlights the extreme energy efficiency achievable with Neuromorphic processor designs. Our results show that Neuromorphic designs are well-suited for real-time near- and in-sensor processing on edge devices.
Read more6/24/2024
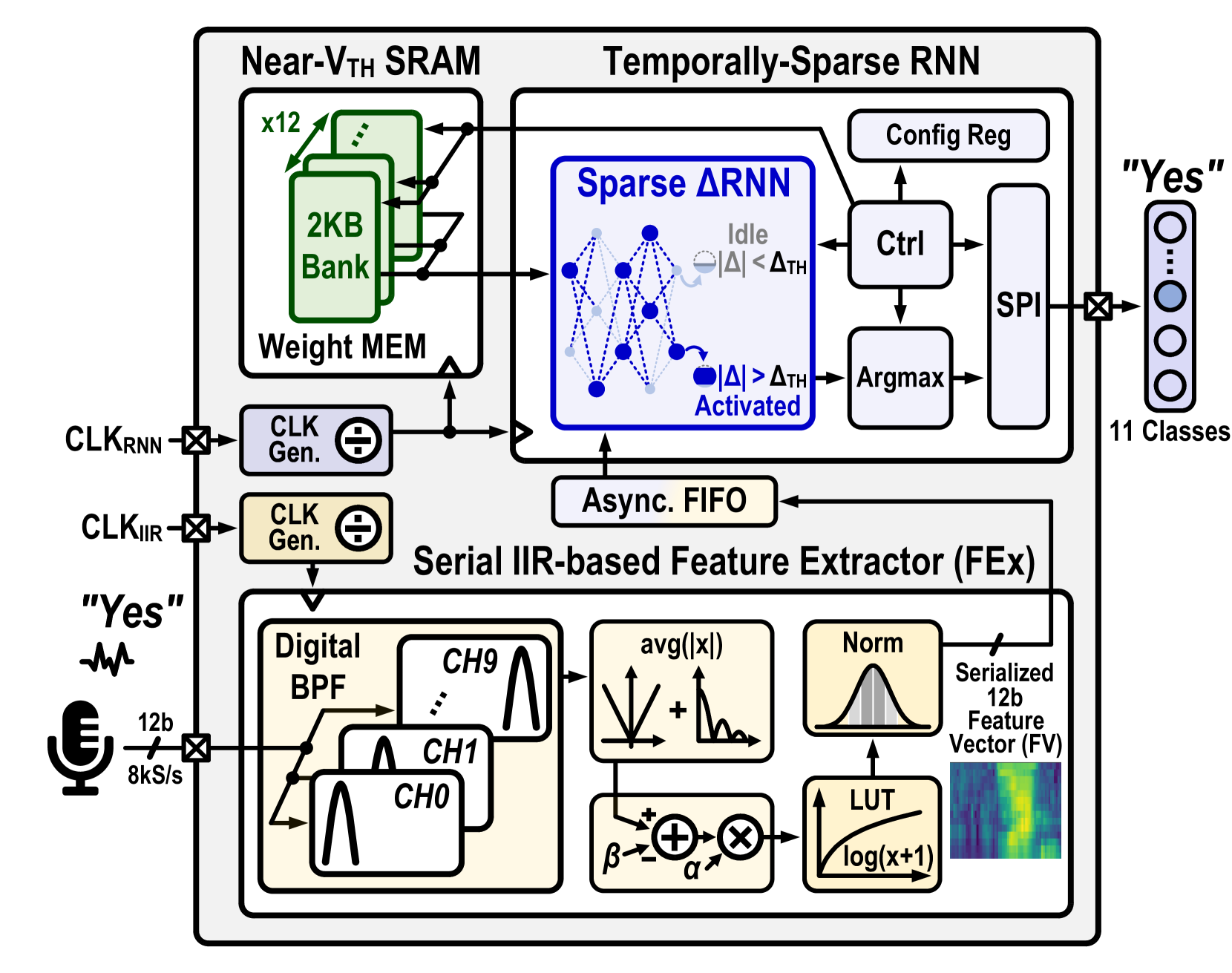
0
A 65nm 36nJ/Decision Bio-inspired Temporal-Sparsity-Aware Digital Keyword Spotting IC with 0.6V Near-Threshold SRAM
Qinyu Chen, Kwantae Kim, Chang Gao, Sheng Zhou, Taekwang Jang, Tobi Delbruck, Shih-Chii Liu
This paper introduces, to the best of the authors' knowledge, the first fine-grained temporal sparsity-aware keyword spotting (KWS) IC leveraging temporal similarities between neighboring feature vectors extracted from input frames and network hidden states, eliminating unnecessary operations and memory accesses. This KWS IC, featuring a bio-inspired delta-gated recurrent neural network ({Delta}RNN) classifier, achieves an 11-class Google Speech Command Dataset (GSCD) KWS accuracy of 90.5% and energy consumption of 36nJ/decision. At 87% temporal sparsity, computing latency and energy per inference are reduced by 2.4$times$/3.4$times$, respectively. The 65nm design occupies 0.78mm$^2$ and features two additional blocks, a compact 0.084mm$^2$ digital infinite-impulse-response (IIR)-based band-pass filter (BPF) audio feature extractor (FEx) and a 24kB 0.6V near-Vth weight SRAM with 6.6$times$ lower read power compared to the standard SRAM.
Read more5/8/2024

0
Self-Learning for Personalized Keyword Spotting on Ultra-Low-Power Audio Sensors
Manuele Rusci, Francesco Paci, Marco Fariselli, Eric Flamand, Tinne Tuytelaars
This paper proposes a self-learning framework to incrementally train (fine-tune) a personalized Keyword Spotting (KWS) model after the deployment on ultra-low power smart audio sensors. We address the fundamental problem of the absence of labeled training data by assigning pseudo-labels to the new recorded audio frames based on a similarity score with respect to few user recordings. By experimenting with multiple KWS models with a number of parameters up to 0.5M on two public datasets, we show an accuracy improvement of up to +19.2% and +16.0% vs. the initial models pretrained on a large set of generic keywords. The labeling task is demonstrated on a sensor system composed of a low-power microphone and an energy-efficient Microcontroller (MCU). By efficiently exploiting the heterogeneous processing engines of the MCU, the always-on labeling task runs in real-time with an average power cost of up to 8.2 mW. On the same platform, we estimate an energy cost for on-device training 10x lower than the labeling energy if sampling a new utterance every 5 s or 16.4 s with a DS-CNN-S or a DS-CNN-M model. Our empirical result paves the way to self-adaptive personalized KWS sensors at the extreme edge.
Read more8/23/2024