NeuroSpex: Neuro-Guided Speaker Extraction with Cross-Modal Attention

0

Sign in to get full access
Overview
- NeuroSpex is a novel approach to speaker extraction that leverages cross-modal fusion of neural and audio-visual cues.
- It combines brain activity signals, visual features, and audio signals to better isolate a target speaker's voice in a noisy environment.
- The proposed method outperforms state-of-the-art audio-only and audio-visual speaker extraction models.
Plain English Explanation
NeuroSpex is a new technique that uses a combination of brain activity, visual information, and audio signals to identify and extract a specific person's voice from a noisy background.
Traditional speaker extraction models rely solely on audio cues, which can be challenging in busy environments with multiple people speaking. NeuroSpex overcomes this limitation by incorporating neural signals from the brain that indicate where a person is focusing their attention. This "neuro-guidance" helps the model better isolate the target speaker.
Additionally, NeuroSpex uses visual features like the speaker's lip movements and facial expressions to further refine the extracted audio. By fusing these cross-modal cues - brain activity, visuals, and audio - the model can more accurately separate the target voice from background noise and other speakers.
Overall, NeuroSpex demonstrates significant improvements over existing audio-only and audio-visual speaker extraction techniques, making it a promising approach for applications like virtual meetings, audio transcription, and human-computer interaction.
Technical Explanation
NeuroSpex is a novel speaker extraction model that leverages multi-modal fusion of neural, visual, and audio signals. The key innovation is the use of brain activity signals, captured via electroencephalography (EEG), to guide the audio-visual speaker extraction process.
The model takes in a mixed audio signal, video of the speakers, and the listener's EEG data. It first extracts visual features like lip movements and facial expressions from the video. It also processes the EEG data to identify neural signatures of the listener's selective auditory attention.
These cross-modal cues - visual features and neural attention signals - are then fused with the audio input using a transformer-based architecture. This allows the model to better isolate the target speaker's voice compared to using audio alone or simple audio-visual fusion.
The authors evaluate NeuroSpex on benchmark speaker extraction datasets and show that it outperforms state-of-the-art audio-only and audio-visual models, reducing signal distortion and improving target speaker intelligibility. This demonstrates the value of incorporating brain activity signals to guide the speaker extraction process.
Critical Analysis
The NeuroSpex paper presents a compelling approach to speaker extraction that leverages multiple modalities. However, the authors acknowledge some limitations:
- The model requires access to the listener's EEG data, which may not always be available in real-world scenarios. Further research is needed to reduce reliance on this signal.
- The experiments were conducted in relatively controlled environments. Additional testing is required to assess NeuroSpex's performance in more complex, real-world acoustic conditions.
- The paper does not explore how NeuroSpex could scale to scenarios with more than two speakers. Extending the model to handle larger numbers of speakers is an important area for future work.
Despite these caveats, NeuroSpex represents an important step forward in utilizing brain activity signals to enhance audio-visual processing. As the authors note, this line of research has the potential to improve human-computer interaction, assistive technologies, and other applications that require robust speaker extraction.
Conclusion
NeuroSpex is a novel speaker extraction model that combines brain activity, visual, and audio signals to better isolate a target speaker's voice in noisy environments. By fusing these cross-modal cues, NeuroSpex outperforms state-of-the-art audio-only and audio-visual approaches, demonstrating the value of incorporating neural attention signals to guide the speaker extraction process.
While the current implementation has some limitations, the core idea of leveraging multi-modal information, including brain activity, represents an exciting direction for advancing speaker extraction and related audio processing technologies. As this line of research progresses, NeuroSpex and similar neuro-guided models could have a significant impact on applications ranging from virtual meetings to assistive devices for the hearing impaired.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NeuroSpex: Neuro-Guided Speaker Extraction with Cross-Modal Attention
Dashanka De Silva, Siqi Cai, Saurav Pahuja, Tanja Schultz, Haizhou Li
In the study of auditory attention, it has been revealed that there exists a robust correlation between attended speech and elicited neural responses, measurable through electroencephalography (EEG). Therefore, it is possible to use the attention information available within EEG signals to guide the extraction of the target speaker in a cocktail party computationally. In this paper, we present a neuro-guided speaker extraction model, i.e. NeuroSpex, using the EEG response of the listener as the sole auxiliary reference cue to extract attended speech from monaural speech mixtures. We propose a novel EEG signal encoder that captures the attention information. Additionally, we propose a cross-attention (CA) mechanism to enhance the speech feature representations, generating a speaker extraction mask. Experimental results on a publicly available dataset demonstrate that our proposed model outperforms two baseline models across various evaluation metrics.
Read more9/17/2024
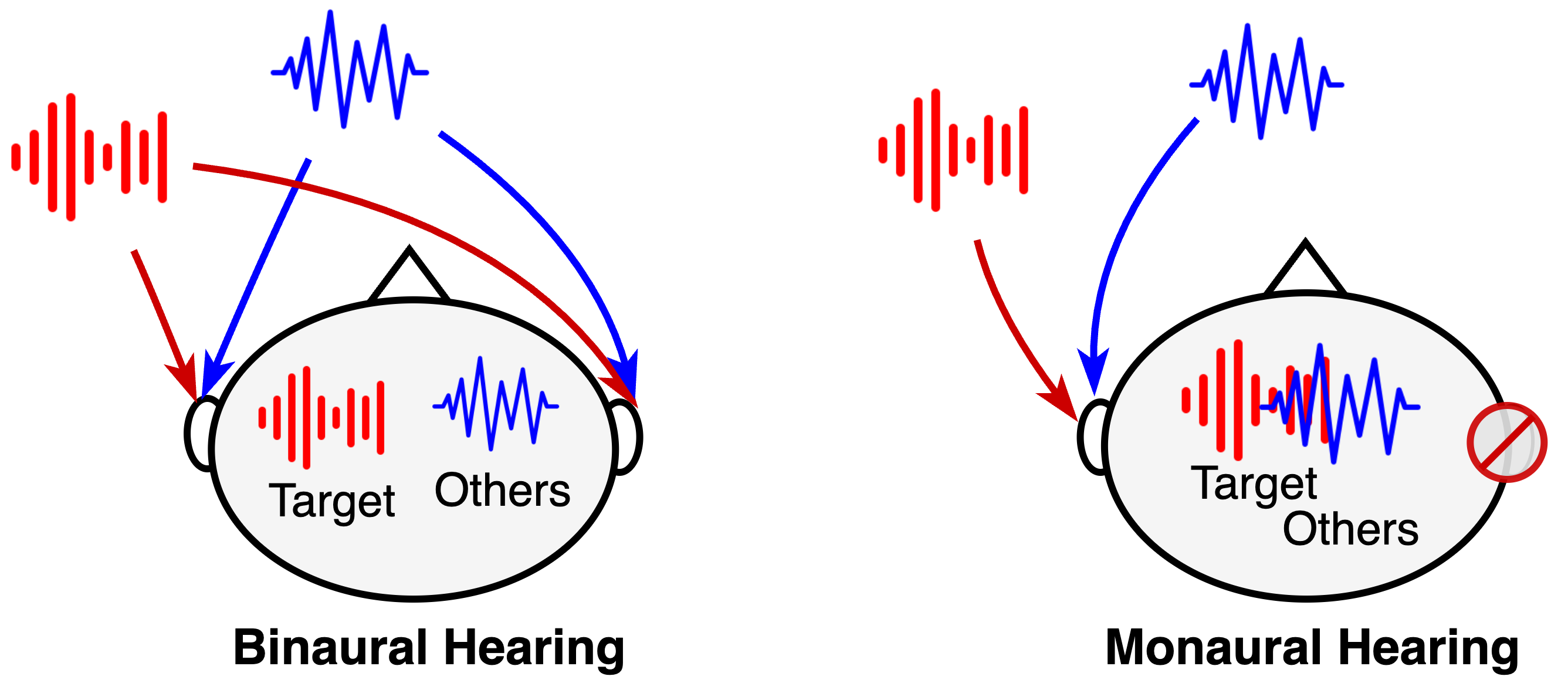
0
Binaural Selective Attention Model for Target Speaker Extraction
Hanyu Meng, Qiquan Zhang, Xiangyu Zhang, Vidhyasaharan Sethu, Eliathamby Ambikairajah
The remarkable ability of humans to selectively focus on a target speaker in cocktail party scenarios is facilitated by binaural audio processing. In this paper, we present a binaural time-domain Target Speaker Extraction model based on the Filter-and-Sum Network (FaSNet). Inspired by human selective hearing, our proposed model introduces target speaker embedding into separators using a multi-head attention-based selective attention block. We also compared two binaural interaction approaches -- the cosine similarity of time-domain signals and inter-channel correlation in learned spectral representations. Our experimental results show that our proposed model outperforms monaural configurations and state-of-the-art multi-channel target speaker extraction models, achieving best-in-class performance with 18.52 dB SI-SDR, 19.12 dB SDR, and 3.05 PESQ scores under anechoic two-speaker test configurations.
Read more6/19/2024

0
Using Ear-EEG to Decode Auditory Attention in Multiple-speaker Environment
Haolin Zhu, Yujie Yan, Xiran Xu, Zhongshu Ge, Pei Tian, Xihong Wu, Jing Chen
Auditory Attention Decoding (AAD) can help to determine the identity of the attended speaker during an auditory selective attention task, by analyzing and processing measurements of electroencephalography (EEG) data. Most studies on AAD are based on scalp-EEG signals in two-speaker scenarios, which are far from real application. Ear-EEG has recently gained significant attention due to its motion tolerance and invisibility during data acquisition, making it easy to incorporate with other devices for applications. In this work, participants selectively attended to one of the four spatially separated speakers' speech in an anechoic room. The EEG data were concurrently collected from a scalp-EEG system and an ear-EEG system (cEEGrids). Temporal response functions (TRFs) and stimulus reconstruction (SR) were utilized using ear-EEG data. Results showed that the attended speech TRFs were stronger than each unattended speech and decoding accuracy was 41.3% in the 60s (chance level of 25%). To further investigate the impact of electrode placement and quantity, SR was utilized in both scalp-EEG and ear-EEG, revealing that while the number of electrodes had a minor effect, their positioning had a significant influence on the decoding accuracy. One kind of auditory spatial attention detection (ASAD) method, STAnet, was testified with this ear-EEG database, resulting in 93.1% in 1-second decoding window. The implementation code and database for our work are available on GitHub: https://github.com/zhl486/Ear_EEG_code.git and Zenodo: https://zenodo.org/records/10803261.
Read more9/16/2024
🗣️
0
Sparsity-Driven EEG Channel Selection for Brain-Assisted Speech Enhancement
Jie Zhang, Qing-Tian Xu, Zhen-Hua Ling, Haizhou Li
Speech enhancement is widely used as a front-end to improve the speech quality in many audio systems, while it is hard to extract the target speech in multi-talker conditions without prior information on the speaker identity. It was shown that the auditory attention on the target speaker can be decoded from the electroencephalogram (EEG) of the listener implicitly. In this work, we therefore propose a novel end-to-end brain-assisted speech enhancement network (BASEN), which incorporates the listeners' EEG signals and adopts a temporal convolutional network together with a convolutional multi-layer cross attention module to fuse EEG-audio features. Considering that an EEG cap with sparse channels exhibits multiple benefits and in practice many electrodes might contribute marginally, we further propose two channel selection methods, called residual Gumbel selection and convolutional regularization selection. They are dedicated to tackling training instability and duplicated channel selections, respectively. Experimental results on a public dataset show the superiority of the proposed BASEN over existing approaches. The proposed channel selection methods can significantly reduce the amount of informative EEG channels with a negligible impact on the performance.
Read more6/26/2024